


用 Java Stream 实现代码困难时该怎么办?
Stream 是 JAVA 8 开始提供的重要类库,提供了更丰富流畅的 Lambda 语法,能够较方便地实现很多集合运算,但实际上,Stream 的专业程度还远远不够,在结构化计算方面还有很多短板。
当集合的成员是简单数据类型时(整数、浮点、字符串、日期),Stream 可方便地实现集合计算,比如过滤、排序、汇总整数数组:
IntStream iStream=IntStream.of(1,3,5,2,3,6);
IntStream r1=iStream.filter(m->m>2);
Stream r2=iStream.boxed().sorted();
int r3=iStream.sum();
但结构化计算的数据对象不是简单数据类型,而是记录(Map\ entity\ record)。一旦数据对象变成记录,Stream 就不那么方便了。比如按年份和 Client 分组:
Calendar cal=Calendar.getInstance();
Map<Object, DoubleSummaryStatistics> c=Orders.collect(Collectors.groupingBy(
r->{
cal.setTime(r.OrderDate);
return cal.get(Calendar.YEAR)+"_"+r.SellerId;
},
Collectors.summarizingDouble(r->{
return r.Amount;
})
)
);
for(Object sellerid:c.keySet()){
DoubleSummaryStatistics r =c.get(sellerid);
String year_sellerid[]=((String)sellerid).split("_");
System.out.println("group is (year):"+year_sellerid[0]+"\t (sellerid):"+year_sellerid[1]+"\t sum is:"+r.getSum());
}
Stream 不直接支持关联计算。比如对 Orders 表和 Employee 表进行内关联,然后对 Employee.Dept 进行分组,对 Orders.Amount 求和:
Map<Integer, Employee> EIds = Employees.collect(Collectors.toMap(Employee::EId, Function.identity()));
//创建新的OrderRelation类,里面SellerId是单值,指向对应的那个Employee对象。
record OrderRelation(int OrderID, String Client, Employee SellerId, double Amount, Date OrderDate){}
Stream<OrderRelation> ORS=Orders.map(r -> {
Employee e=EIds.get(r.SellerId);
OrderRelation or=new OrderRelation(r.OrderID,r.Client,e,r.Amount,r.OrderDate);
return or;
}).filter(e->e.SellerId!=null);
Map<String, DoubleSummaryStatistics> c=ORS.collect(Collectors.groupingBy(r->r.SellerId.Dept,Collectors.summarizingDouble(r->r.Amount)));
for(String dept:c.keySet()){
DoubleSummaryStatistics r =c.get(dept);
System.out.println("group(dept):"+dept+" sum(Amount):"+r.getSum());
}
硬编码实现的关联计算不仅冗长,而且逻辑复杂。左关联和外关联的代码同样要硬编码,关键的代码逻辑还不一样,编写起来难度更大,这对专业 JAVA 程序员来说都是个挑战。
在 Stream 出现之前,Java 实现集合类的运算都非常麻烦。Stream 的出现改善了 JAVA 在结构化计算方面不专业的状况,比如,Stream 有基本的集合运算,对 lambda 语法也支持良好。但 Stream 缺乏专业的结构化数据对象,仍然要使用基于 JAVA 的数据类型完成运算。
其实,直接在 JAVA 中实现的计算类库都不够专业,根本问题就在于 JAVA 缺乏专业的结构化数据对象,缺少来自底层的有力支持。结构化计算的返回值的结构随计算过程而变,大量的中间结果同样是动态结构,这些都难以事先定义,而 JAVA 是强类型语言,又必须事先定义数据对象的结构(否则只能用 map 这类操作繁琐的数据对象),这就使 JAVA 的结构化计算僵化死板, lambda 语法的能力严重受限。解释性语言可以简化参数的定义,函数本身就可指定参数表达式应解释成值参数还是函数参数,而 JAVA 是编译型语言,难以区分不同类型的参数,必须设计复杂难懂的接口才能实现匿名函数(主要指 lambda 语法)。省略数据对象而直接引用字段(比如写成“单价数量”),可显著简化结构化计算,但 JAVA 缺乏专业的结构化数据对象,目前还无法支持此类表面简单实则巧妙的语法,这就使 JAVA 代码冗长且不直观(只能写成“x. 单价x. 数量”)。
Stream 缺乏专业的数据对象,在结构化计算方面远不如 SQL 专业,SQL 虽然足够专业,但必须依赖数据库,两者都有其短板。有时候我们既需要 SQL 专业的结构化计算语法,又需要像 Stream 那样的库外计算能力,这种情况应该怎么办?
解决办法:esProc - Java 专业计算包
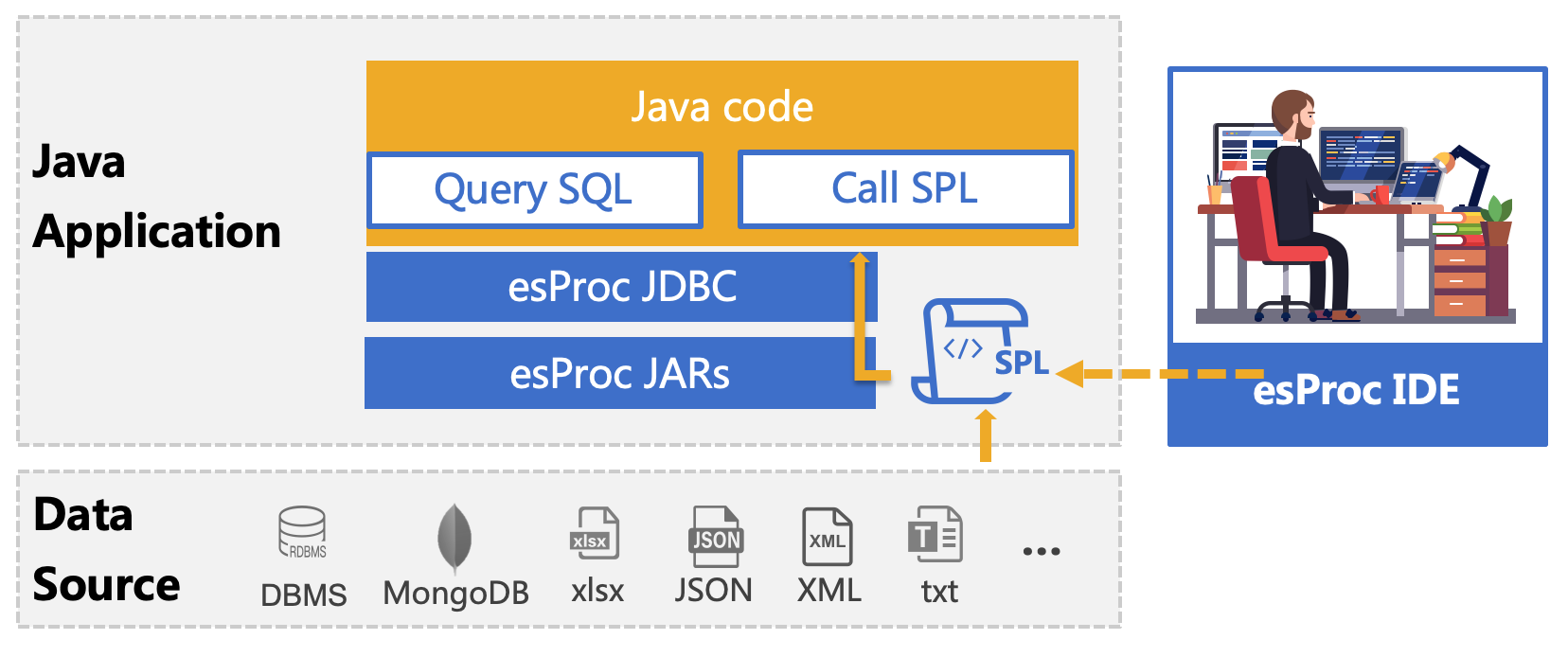
esProc 是专门用于 Java 计算的类库,旨在简化 Java 代码,提供不依赖数据库的计算能力。 SPL 是基于 esProc 计算包的脚本语言,和 Java 程序一起部署,用法和 Java 程序中调用存储过程相同,通过 JDBC 接口调用,返回 ResultSet 对象。
数据集的过滤、排序、分组汇总、连接等,用 SPL 读取都非常简单。比如:找出英语平均分低于70分的班级。
A |
|
1 |
=T(“E:/txt/Students_scores.txt”) |
2 |
=A1.groups(CLASS;avg(English):avg_En) |
3 |
=A2.select(avg_En<70) |
这段代码可在esProc的IDE中调试/执行,然后将其存为脚本文件(比如condition.dfx),通过JDBC接口在JAVA中调用,具体代码如下:
package Test;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class test1 {
public static void main(String[] args)throws Exception {
Class.forName("com.esproc.jdbc.InternalDriver");
Connection connection =DriverManager.getConnection("jdbc:esproc:local://");
Statement statement = connection.createStatement();
ResultSet result = statement.executeQuery("call condition.dfx");
printResult(result);
if(connection != null) connection.close();
}
…
}
上面的用法类似存储过程,其实 SPL 也支持类似 SQL 的用法,即无须脚本文件,直接将 SPL 嵌入 JAVA,代码如下:
…
ResultSet result = statement.executeQuery("
=file(\"D:\\sOrder.csv\").groups(CLASS;avg(English):avg_En).select(avg_En<70)");
…
用 SPL 实现关联计算:
比如:销售订单信息和产品信息分别存储在两个文本文件中,计算各订单的销售额。两个文件数据结构如下图:
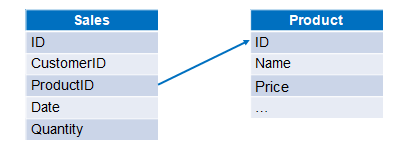
A |
|
1 |
=T(“e:/orders/sales.csv”) |
2 |
=T(“e:/orders/product.csv”).keys(ID) |
3 |
=A1.join(ProductID,A2,Name,Price) |
4 |
=A3.derive(Quantity*Price:amount) |
SPL 中提供了完善的用 SQL 查询数据的方法:
比如:州信息,部门信息和员工信息分别存储在3个文本文件中,查询经理在California州的New York州员工。
A |
|
1 |
$select e.NAME as ENAME from E:/txt/EMPLOYEE.txt as e join E:/txt/DEPARTMENT.txt as d on e.DEPT=d.NAME join E:/txt/EMPLOYEE.txt as emp on d.MANAGER=emp.EID where e.STATE='New York' and emp.STATE='California' |
利用 SPL 可以极大简化 Java 程序中的结构化数据计算,示例总结整理如下:
更多计算示例,参见 SPL 应用计算


英文版