


结构化数据中的存在判断问题
【摘要】
从数据表中选出数据时,有时候需要判断成员在某些条件下是否存在,这些条件可能是从其他的数据表中查询的。例如分数是成绩表的字段,怎样从学生表中选出各科分数都高于 80 分的学生?如何简便快捷的处理结构化数据中的存在判断问题,这里为你全程解析,并提供 esProc 示例代码。结构化数据中的存在判断问题
1. 外键映射的存在性检测
在两个表中,根据外键映射的存在性查找记录。
【例 1】 统计一班男生的平均分。成绩表和学生表如下:
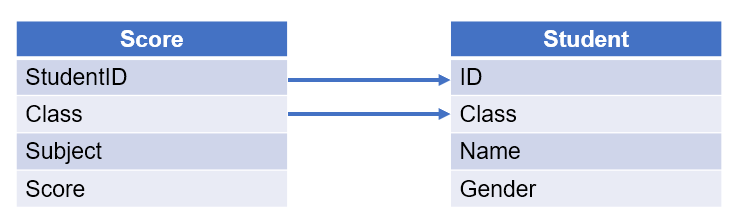
【解题思路】
从分数表选出数据时,判断是否存在班级的名称是一班且学生性别是男性的记录,如果存在则选出。
【SPL 脚本】
A |
B |
|
1 |
=connect("db") |
/连接数据库 |
2 |
=A1.query("select * from Score") |
/查询学生表 |
3 |
=A1.query("select * from Student") |
/查询学生成绩表 |
4 |
=A3.select(Class=="Class 1" && Gender=="Male") |
/选出一班男生 |
5 |
=A2.join@i(Class:StudentID, A4:Class:ID) |
/使用函数 A.join@i() 连接过滤 |
6 |
=A5.groups(StudentID; avg(Score):Score) |
/分组汇总每个学生的平均分 |
A6的执行结果如下:
StudentID |
Score |
1 |
76 |
3 |
74 |
… |
… |
当外键表数据量大时,可以使用游标的有序归并来解决。
【例 2】 查询 2014 年每月没有使用折扣的订单数量。订单表和订单明细表如下:
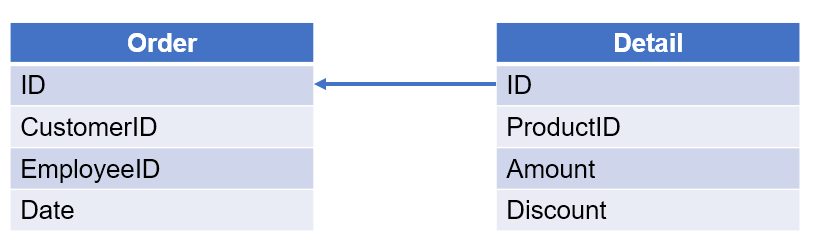
【解题思路】
从订单表选出数据时,判断是否存在折扣为 0 的订单,如果存在则选出。
【SPL 脚本】
A |
B |
|
1 |
=connect("db") |
/连接数据库 |
2 |
=A1.cursor("select * from Order where year(Date)=2014 order by ID") |
/创建订单表游标,选出 2014 年记录 |
3 |
=A1.cursor("select * from Detail order by ID") |
/创建订单明细表游标 |
4 |
=A3.select(Discount==0) |
/选出没有使用折扣的记录 |
5 |
=joinx(A2:Order,ID;A4:Detail,ID) |
/使用函数 joinx 对订单表和订单明细表的游标进行有序归并 |
6 |
=A5.groups(month(Order.Date):Month; icount(Order.ID):OrderCount) |
/分组汇总每个月的订单数量 |
A6的执行结果如下:
Month |
OrderCount |
1 |
16 |
2 |
25 |
… |
… |
2. 非等值连接的存在性检测
在一个表中,通过非等值连接的存在性检测查找数据。
【例 3】 查询同一订单跨度超过一年的订单的销售额。订单表部分数据如下:
ID |
NUMBER |
AMOUNT |
DELIVERDATE |
ARRIVALDATE |
10814 |
1 |
408.0 |
2014/01/05 |
2014/04/18 |
10814 |
2 |
204.0 |
2014/02/21 |
2014/04/05 |
10814 |
3 |
102.0 |
2014/03/14 |
2014/04/06 |
10814 |
4 |
102.0 |
2014/04/09 |
2014/04/27 |
10814 |
5 |
102.0 |
2014/05/04 |
2014/07/04 |
10848 |
1 |
873.0 |
2014/01/06 |
2014/04/21 |
… |
… |
… |
… |
… |
【解题思路】
从订单表中选出数据时,判断订单跨度超过一年的记录是否存在,如果存在则选出。
【SPL 脚本】
A |
B |
|
1 |
=connect("db") |
/连接数据库 |
2 |
=A1.query("select * from Detail") |
/查询订单明细表 |
3 |
=A2.group(ID) |
/按订单日期分组 |
4 |
=A3.select(interval(~.min(DELIVERDATE), ~.max(ARRIVALDATE)) > 365) |
/选出同一订单的时间间隔超过 365 天的记录 |
5 |
=A4.new(ID, ~.sum(AMOUNT):Amount) |
/创建数据表,统计每个订单的销售额 |
A5的执行结果如下:
ID |
Amount |
10998 |
6800.0 |
11013 |
4560.0 |
11032 |
20615.0 |
… |
… |
3. 外键映射的不存在性检测
在两个表中,根据外键映射的不存在性检测查找记录。
【例 4】查询所有科目均高于 80 分的学生。成绩表和学生表如下:
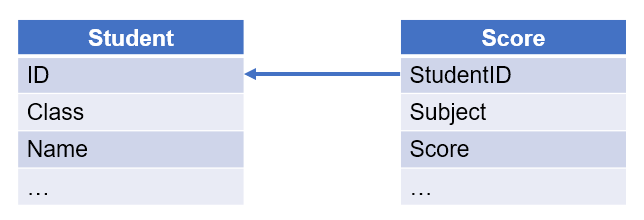
【解题思路】
从学生表选出数据时,判断学生是否存在任意科目低于 80 分的成绩,如果不存在则选出。
【SPL 脚本】
A |
B |
|
1 |
=connect("db") |
/连接数据库 |
2 |
=A1.query("select * from Student") |
/查询学生表 |
3 |
=A1.query("select * from Score") |
/查询成绩表 |
4 |
=A3.select(Score<=80) |
/选出成绩不高于 80 分的记录 |
5 |
=A4.id(StudentID) |
/按学生 ID 去重 |
6 |
=A2.join@d(ID, A5) |
/使用函数 A.join@d() 选出不匹配的记录 |
A6的执行结果如下:
ID |
Class |
Name |
2 |
Class 1 |
Ashley |
16 |
Class 2 |
Alexis |
4. 双重否定的存在性检测
通过双重否定,查询能够匹配的记录。
【例 5】 查询选修了所有课程的学生。选课表、课程表和学生表如下:
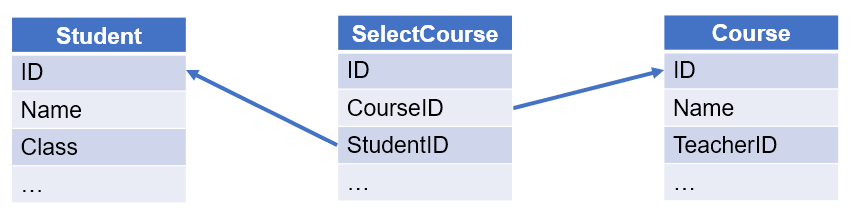
【解题思路】
从学生表选出数据时,判断学生是否存在某一科目课程没有选出的记录,如果不存在则选出。处理双重否定的存在性检测时,我们也可以正向思考,只要选出选修科目数量与所有科目数量相同的记录即可。
【SPL 脚本】
A |
B |
|
1 |
=connect("db") |
/连接数据库 |
2 |
=A1.query("select * from Student") |
/查询学生表 |
3 |
=A1.query("select * from Course") |
/查询课程表 |
4 |
=A1.query("select * from SelectCourse") |
/查询选课表 |
5 |
=A4.groups(StudentID; icount(CourseID):CourseCount) |
/选课表按照学生 ID 分组汇总每个学生的选课数量 |
6 |
=A5.select(CourseCount==A3.len()) |
/选出选择了所有课程的学生 ID |
7 |
=A2.join@i(ID, A6:StudentID) |
/使用函数 A.join@i() 连接过滤 |
A7的执行结果如下:
ID |
Name |
Class |
4 |
Emily Smith |
Class 1 |
5. 任意条件的存在性检测
在两个表中,根据任意条件的存在性检测查找记录。
【例 6】 查询两科分数差超过 30 分的学生。成绩表和学生表如下:
【SQL 语句】
从学生表选出数据时,判断是否存在有任意两个科目成绩相差 30 分的记录,存在则选出。
【SPL 脚本】
A |
B |
|
1 |
=connect("db") |
/连接数据库 |
2 |
=A1.query("select * from Student") |
/查询学生表 |
3 |
=A1.query("select * from Score") |
/查询成绩表 |
4 |
=A3.group(StudentID) |
/成绩表按学生 ID 分组 |
5 |
=A4.select(~.max(Score)-~.min(Score)>30) |
/选出最高分和最低分相差超过 30 分的学生 |
6 |
=A5.id(StudentID) |
/按学生 ID 去重 |
7 |
=A2.join@i(ID,A6) |
/使用函数 A.join@i() 连接过滤 |
A7的执行结果如下:
ID |
Name |
Class |
4 |
Emily Smith |
Class 1 |
8 |
Megan |
Class 1 |
… |
… |
… |
6. 全部条件的存在性检测
根据一个表中数据,筛选出满足所有条件的记录。
【例 7】查询哪些员工的工资比所有销售部员工都要高。员工表部分数据如下:
ID |
NAME |
DEPT |
SALARY |
1 |
Rebecca |
R&D |
7000 |
2 |
Ashley |
Finance |
11000 |
3 |
Rachel |
Sales |
9000 |
4 |
Emily |
HR |
7000 |
5 |
Ashley |
R&D |
16000 |
… |
… |
… |
… |
【SQL 语句】
从员工表选出数据时,判断员工工资大于所有销售部员工工资的记录是否存在,存在则选出。
【SPL 脚本】
A |
B |
|
1 |
=connect("db") |
/连接数据库 |
2 |
=A1.query("select * from Employee") |
/查询员工表 |
3 |
=A2.select(DEPT:"Sales").max(SALARY) |
/选出所在城市包含在一线城市中的记录 |
4 |
=A2.select(SALARY>A3) |
/分组汇总各部门的平均工资 |
A4的执行结果如下:
ID |
NAME |
DEPT |
SALARY |
5 |
Ashley |
R&D |
16000 |
20 |
Alexis |
Administration |
16000 |
22 |
Jacob |
R&D |
18000 |
47 |
Elizabeth |
Marketing |
17000 |
《SPL CookBook》中还有更多相关计算示例。

