


结构化数据中的从属判断问题
【摘要】
从数据表中选出数据时,有时需要判断成员是否从属于某一个集合。例如从房价表中选出重要城市的房价信息,从销售表中选出 VIP 客户的销售记录等等。如何简便快捷的处理结构化数据中的从属判断问题,这里为你全程解析,并提供 esProc 示例代码。结构化数据中的从属判断问题
1. 集合包含性检测
在一个表中,根据集合的包含性判断查找记录。
【例 1】 在员工表中,统计一线城市各部门的平均工资。部分数据如下:
ID |
NAME |
CITY |
SALARY |
1 |
Rebecca |
Tianjin |
7000 |
2 |
Ashley |
Tianjin |
11000 |
3 |
Rachel |
Shijiazhuang |
9000 |
4 |
Emily |
Shenzhen |
7000 |
5 |
Ashley |
Nanjing |
16000 |
… |
… |
… |
… |
【解题思路】
从员工表选出数据时,需要判断员工的所在城市是否从属于由北京、上海、广州、深圳组成的常数集合。当集合的成员数小于 10 个时,可以使用函数 A.contain() 进行过滤。
【SPL 脚本】
A |
B |
|
1 |
=connect("db").query("select * from Employee") |
/连接数据库并查询员工表 |
2 |
[Beijing, Shanghai, Guangzhou, Shenzhen] |
/创建一线城市的常数集合 |
3 |
=A1.select(A2.contain(CITY)) |
/使用函数 A.contain() 选出所在城市包含在一线城市中的记录。 |
4 |
=A3.groups(DEPT; avg(SALARY):SALARY) |
/分组汇总各部门的平均工资 |
A4的执行结果如下:
DEPT |
SALARY |
Finance |
7833.33 |
HR |
7187.5 |
Marketing |
7977.27 |
… |
… |
在一个表中,根据较大集合的包含性判断来查找记录。
【例 2】 在销售表中,统计 2014 年大客户的每月销售额。部分数据如下:
ID |
Customer |
SellerId |
Date |
Amount |
10400 |
EASTC |
1 |
2014/01/01 |
3063.0 |
10401 |
HANAR |
1 |
2014/01/01 |
3868.6 |
10402 |
ERNSH |
8 |
2014/01/02 |
2713.5 |
10403 |
ERNSH |
4 |
2014/01/03 |
1005.9 |
10404 |
MAGAA |
2 |
2014/01/03 |
1675.0 |
… |
… |
… |
… |
… |
【解题思路】
本题与【例 1】类似,从销售表选出数据时,需要判断销售客户是否从属于大客户的常数集合。当集合的成员较多时(超过 10 个),可以先对常数集合排序,再使用函数 A.contain() 的 @b 选项,进行二分法查找。
【SPL 脚本】
A |
B |
|
1 |
=connect("db").query("select * from Sales") |
/连接数据库并查询销售表 |
2 |
=["SAVEA","QUICK","ERNSH","HUN","RATTC","HANAR","FOLKO","QUEEN,MEREP","WHITC","FRANK","KOENE"].sort() |
/创建大客户的常数集合并排序 |
3 |
=A1.select(year(Date)==2014 && A2.contain@b(Customer)) |
/选出 2014 年的大客户记录。当集合 A 有序时,使用函数 A.contain() 的 @b 选项,进行二分法查找。 |
4 |
=A3.groups(month(Date):Month; sum(Amount):Amount) |
/分组汇总每月的销售额 |
A4的执行结果如下:
STATE |
SALARY |
California |
7700.0 |
Texas |
7592.59 |
New York |
7677.77 |
Florida |
7145.16 |
Other |
7308.1 |
2. 外键映射的包含性检测
在两个表中,根据外键映射的包含性检测查找记录。
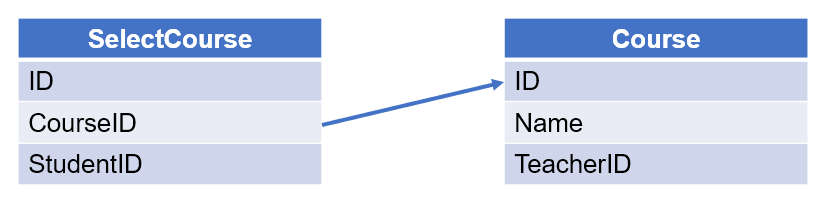
【例 3】 查询各班有多少学生选修了“Matlab”课程。选课表和课程表如下:
【解题思路】
从选课表选出数据时,需要判断课程的名称是否等于“Matlab”。可以先在课程表中筛选出课程名称是“Matlab”的课程集合,再选出选课表的课程 ID 从属于这个集合的记录。
【SPL 脚本】
A |
B |
|
1 |
=connect("db") |
/连接数据库 |
2 |
=A1.query("select * from Course") |
/查询课程表 |
3 |
=A1.query("select * from SelectCourse") |
/查询选课表 |
4 |
=A2.select(Name=="Matlab") |
/从课程表中选出指定课程 |
5 |
=A3.join@i(CourseID, A4:ID) |
/使用函数 A.join() 的 @i 选项进行连接过滤 |
6 |
=A5.groups(Class; count(1):SelectCount) |
/分组汇总各班报名的人数 |
A6的执行结果如下:
Class |
SelectCount |
Class 1 |
3 |
Class 2 |
5 |
… |
… |
3. 非外键的包含性检测
在两个表中,根据非外键的包含性检测查找记录。
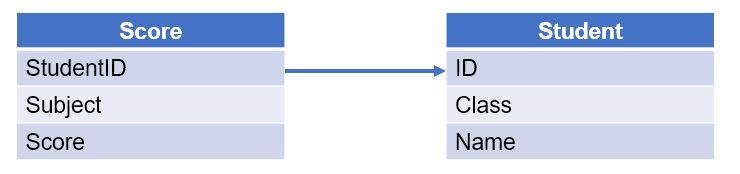
【例 4】 查询各班所有某科成绩超过 80 分的学生数量。成绩表和学生表如下:
【SQL 语句】
从学生表选出数据时,需要判断学生是否有单科成绩超过 80 分的。可以先在成绩表中选出所有大于 80 分的记录,再按学生 ID 去重,得到某科成绩高于 80 分的学生 ID 的集合。接下来只要选出学生的 ID 从属于这个集合的记录。
【SPL 脚本】
A |
B |
|
1 |
=connect("db") |
/连接数据库 |
2 |
=A1.query("select * from Student") |
/查询学生表 |
3 |
=A1.query("select * from Score") |
/查询学生成绩表 |
4 |
=A3.select(Score>80) |
/选出有成绩超过 80 分的记录 |
5 |
=A4.id(StudentID) |
/使用 id 函数按学生 ID 去重 |
6 |
=A2.join@i(ID, A5) |
/使用函数 A.join@i() 连接过滤 |
7 |
=A6.groups(Class; count(1):StudentCount) |
/分组汇总每个班级的学生数量 |
A7的执行结果如下:
Class |
StudentCount |
Class 1 |
9 |
Class 2 |
11 |
… |
… |
在两个表中,根据非外键的匹配性检测查找记录,优化提速。
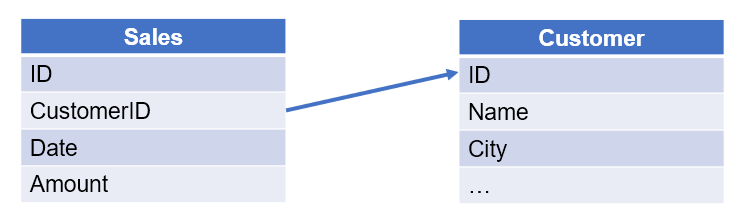
【例 5】查询 2014 年各城市有销售记录的客户数量。销售表和客户表如下:
【解题思路】
从客户表选出数据时,需要判断客户在 2014 年是否有销售记录。可以先在销售表中选出 2014 年的记录,再按客户 ID 去重,得到 2014 年有销售记录的客户 ID 的集合。接下来只要选出客户表的 ID 从属于这个集合的记录。
【SPL 脚本】
A |
B |
|
1 |
=connect("db") |
/连接数据库 |
2 |
=A1.query("select * from Customer") |
/查询客户表 |
3 |
=A1.query("select * from Sales where year(Date)=2014 order by CustomerID") |
/查询 2014 年的销售记录,并按客户 ID 排序 |
4 |
=A3.groups@o(ID) |
/使用 groups 函数按客户 ID 去重,有序时使用 @o 选项 |
5 |
=A2.join@i(ID, A4:CustomerID) |
/使用函数 A.join@i() 连接过滤 |
6 |
=A5.groups(City; count(1):CustomerCount) |
/分组汇总每个城市的客户数量 |
A6的执行结果如下:
City |
CustomerCount |
Dongying |
6 |
Tangshan |
7 |
… |
… |
4. 外键映射的不包含性检测
在两个表中,根据外键映射的不包含性检测查找记录。
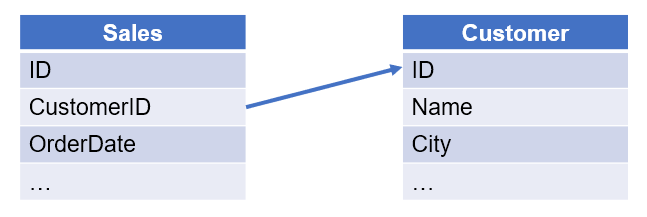
【例 6】 查询 2014 年每个新增客户的销售总额。销售表和客户表如下:
【解题思路】
从客户表选出数据时,需要判断该客户在 2014 年没有销售记录。可以先在销售表中筛选出 2014 年有销售记录的集合,再选出客户表的 ID 不从属于这个集合的记录。
【SPL 脚本】
A |
B |
|
1 |
=connect("db") |
/连接数据库 |
2 |
=A1.query("select * from Sales where year(OrderDate)=2014") |
/查询 2014 年的销售记录 |
3 |
=A1.query("select * from Customer") |
/查询客户表 |
4 |
=A2.join@d(CustomerID ,A3:ID) |
/使用函数 A.join@d() 从销售表中选出客户 ID 在客户表中不存在的记录 |
5 |
=A4.groups(CustomerID; sum(Amount):Amount) |
/分组汇总每个客户的销售额 |
A5的执行结果如下:
CustomerID |
Amount |
DOS |
11830.1 |
HUN |
57317.39 |
… |
… |
《SPL CookBook》中还有更多相关计算示例。


英文版