


有序集合上的定位计算
【摘要】
在数据计算时,除了每条记录本身,经常也会关心有序集合中与位置相关的计算。例如:编号为 752084 的订单在销售表中的第几行?2019 年上证指数收盘价最高的是第几个交易日?如何简单快捷的实现定位?这里将为你全程剖析,并提供 esProc SPL 示例代码。有序集合上的定位计算
1. 定位成员
定位成员是指在有序集合中通过比较成员来查找位置。
【例 1】根据每周的课程表,查看每节课适合的任课教师有哪些。下面任课教师表中,第一列是教师姓名,第三列起是课程代码(null 表示空)。任课教师表部分数据如下:
Teachers.txt |
||||||||
Petitti |
Matematica |
mif |
mig |
vif |
vig |
null |
null |
… |
Canales |
Apesca |
luc |
lud |
mac |
mad |
mic |
mid |
… |
Lucero |
NavegacionI |
lub |
luc |
lud |
lue |
mab |
mac |
… |
Bergamaschi |
TecPesc |
lua |
luf |
maa |
maf |
mia |
mif |
… |
… |
… |
… |
… |
… |
… |
… |
… |
… |
课程表数据如下:
Monday |
Tuesday |
Wednesday |
Thursday |
Friday |
lua |
maa |
mia |
jua |
via |
lub |
mab |
mib |
jub |
vib |
luc |
mac |
mic |
juc |
vic |
lud |
mad |
mid |
jud |
vid |
lue |
mae |
mie |
jue |
vie |
luf |
maf |
mif |
juf |
vif |
lug |
mag |
mig |
jug |
vig |
【SPL脚本】
A |
B |
|
1 |
=file("Teachers.txt").import() |
/导入任课老师表 |
2 |
=A1.new(#1:professor,~.array().to(3,A1.fno()).select(~):codeArray) |
/由任课教师表生成新表,其中第一列是教师名,第二列是课程列表。 |
3 |
=file("Courses.txt").import@t().conj(~.array()) |
/导入课程表,然后将所有课程合并在一起 |
4 |
=A3.(A2.select(codeArray.pos(A3.~)).(professor)) |
/循环课程,使用 pos 函数在教师的课程列表中查找当前课程,选出每节课适合的教师。 |
5 |
=create(Monday,Tuesday,Wednesday,Thursday,Friday).record(A4.(~.concat@c())) |
/创建周一到周五的课程表,并依此填入教师。 |
A5的执行结果如下:
Monday |
Tuesday |
Wednesday |
Thursday |
Friday |
Bergamaschi,Puebla |
Bergamaschi,Pue… |
Bergamaschi,Puebla |
Bergamaschi,Pue… |
Bergamaschi,Puebla |
Lucero,Puebla,Lu… |
Lucero,Mazza,Pu… |
Lucero,Puebla,Chi… |
Lucero,Mazza,Pe… |
Lucero,Puebla,Vel… |
Canales,Lucero,P… |
Canales,Lucero,M… |
Canales,Lucero,P… |
Canales,Lucero,M… |
Lucero,Velasco,Lu… |
… |
… |
… |
… |
… |
在集合中定位成员时,成员可能重复出现。例如定位数学 100 分的同学可能有多个,名字叫 Ashley 的员工可能不止一人等等。
【例 2】 根据销售表和客户表,查询 2014 年无销售记录的客户。销售表和客户表的关系如下:
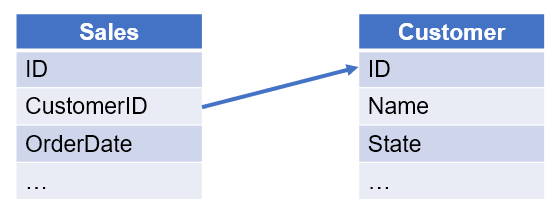
【SPL 脚本】
A |
B |
|
1 |
=connect("db") |
/连接数据库 |
2 |
=A1.query("select * from Sales where year(OrderDate)=2014") |
/查询 2014 年的销售记录 |
3 |
=A1.query("select * from Customer") |
/查询客户表 |
4 |
=A3.(ID).sort() |
/列出客户序号并排序 |
5 |
=A2.align(A4.len(), A4.pos@b(CustomerID)) |
/销售数据按照客户序号进行定位分组,使用 pos 函数查找客户序号。由于客户序号是有序的,这里使用 @b 选项进行二分法查找,可以更快速定位。 |
6 |
=A3(A5.pos@a(null)) |
/使用 pos() 函数的 @a 选项,选出所有没有销售记录(值为 null)的客户信息,否则只会选出一个。 |
A6的执行结果如下:
ID |
Name |
State |
… |
ALFKI |
CMA-CGM |
Texas |
… |
CENTC |
Nedlloyd |
Florida |
… |
2. 定位最大值 / 最小值
定位最大值 / 最小值,是指获取最大值 / 最小值成员(或表达式)所在的序号。
【例 3】 根据股市交易表,统计上证指数收盘价最高的当天,相对前日的涨幅。部分数据如下:
Date |
Open |
Close |
Amount |
2019/12/31 |
3036.3858 |
3050.124 |
2.27E11 |
2019/12/30 |
2998.1689 |
3040.0239 |
2.67E11 |
2019/12/27 |
3006.8517 |
3005.0355 |
2.58E11 |
2019/12/26 |
2981.2485 |
3007.3546 |
1.96E11 |
2019/12/25 |
2980.4276 |
2981.8805 |
1.9E11 |
… |
… |
… |
… |
【SPL 脚本】
A |
B |
|
1 |
=file("000001.csv").import@ct() |
/导入数据文件 |
2 |
=A1.sort(Date) |
/按日期排序 |
3 |
=A2.pmax(Close) |
/使用函数 A.pmax(),获取收盘价最大值的成员序号。 |
4 |
=A2.calc(A3,Close/Close[-1]-1) |
/使用当天收盘价和前日收盘价计算涨幅 |
A4的执行结果如下:
Member |
0.010276967857506536 |
同样可以使用函数 A.pmin() 来取最小值的成员序号:
A |
B |
|
3 |
=A3.pmin(Close) |
/使用函数 A.pmin(),获取收盘价最小值的成员序号。 |
最大值所在记录不一定是唯一的,如果想返回所有记录的序号,可以使用函数A.pmax()的选项@a :
A |
B |
|
3 |
=A2.pmax@a(Close) |
/使用函数 A.pmin() 的 @a 选项,取出所有股市最高点记录的序号 |
如果希望从后向前定位,可以使用函数A.pmax()的选项@z :
A |
B |
|
3 |
=A2.pmax@z(Close) |
/使用函数 A.pmax() 的 @z 选项,从后向前取出股市最高点记录的序号 |
3. 根据条件定位
根据条件定位,是指对有序集合的成员按指定条件进行计算,返回结果为 "true" 的成员序号。例如在员工表中查找年龄大于 50 岁的员工序号,在成绩表中查找数学分数高于 90 分的成绩序号等等。
【例 4】 根据股市交易表,统计收盘价涨幅超过 3% 的交易日,相对前日的交易量涨幅。部分数据如下:
Date |
Open |
Close |
Amount |
2019/12/31 |
3036.3858 |
3050.124 |
2.27E11 |
2019/12/30 |
2998.1689 |
3040.0239 |
2.67E11 |
2019/12/27 |
3006.8517 |
3005.0355 |
2.58E11 |
2019/12/26 |
2981.2485 |
3007.3546 |
1.96E11 |
2019/12/25 |
2980.4276 |
2981.8805 |
1.9E11 |
… |
… |
… |
… |
【SPL脚本】
A |
B |
|
1 |
=file("000001.csv").import@ct() |
/导入数据文件 |
2 |
=A1.select(year(Date)==2019).sort(Date) |
/选出 2019 年的股市记录并按日期排序 |
3 |
=A2.pselect@a(Close/Close[-1]>1.03) |
/使用函数 A.pselect () 取出股市收盘价涨幅超过 3% 的记录序号,@a 选项会返回所有满足条件的成员序号。 |
4 |
=A3.new(A2(~).Date:Date, A2(~).Amount/A2(~-1).Amount:'Amount increase') |
/循环用每天交易量和前日交易量计算涨幅 |
A3的执行结果如下:
Member |
161 |
187 |
211 |
A4的执行结果如下:
Date |
Amount increase |
2019/02/25 |
1.758490566037736 |
2019/03/29 |
1.3344827586206895 |
2019/05/10 |
1.3908629441624365 |
我们可以看到,收盘价涨幅超过 3% 的这三天,交易量较前日大幅提升。
4. 区间定位
前面介绍了根据成员或者表达式来定位,有时候我们还需要通过区间定位,从而进行分组汇总等计算。例如年龄集合 [0,18,35,60] 分别代表少年、青年、中年和老年,查找年龄 20 在集合中的区段序号,结果是 2,也就是青年;工资集合定义为[0,8000,15000,30000],查找工资 25000 在集合中的区段序号,结果是 3。
【例 5】 根据员工薪资表,统计 8000 以下、8000~12000 和 12000 以上每个薪资分段的员工总数。部分数据如下:
ID |
NAME |
BIRTHDAY |
SALARY |
1 |
Rebecca |
1974-11-20 |
7000 |
2 |
Ashley |
1980-07-19 |
11000 |
3 |
Rachel |
1970-12-17 |
9000 |
4 |
Emily |
1985-03-07 |
7000 |
5 |
Ashley |
1975-05-13 |
16000 |
… |
… |
… |
… |
【SPL脚本】
A |
B |
|
1 |
=connect("db") |
/连接数据库 |
2 |
=A1.query("select * from EMPLOYEE") |
/查询员工表 |
3 |
[0,8000,12000] |
/定义工资区间 |
4 |
=A2.align@a(A3.len(),A3.pseg(SALARY)) |
/使用 A.pseg(y) 函数获取工资所在区间序号 |
5 |
=A4.new(A3 (#):SALARY,~.count():COUNT) |
/统计每组的人数 |
A5的执行结果如下:
SALARY |
COUNT |
0 |
308 |
8000 |
153 |
12000 |
39 |
有时候集合的区段值需要经过计算后再计算成员在集合中的区段序号。
【例 6】 根据员工薪资表,统计入职 10 年以下、10~20 年和 20 年以上每组的员工平均工资。部分数据如下:
ID |
NAME |
HIREDATE |
SALARY |
1 |
Rebecca |
2005-03-11 |
7000 |
2 |
Ashley |
2008-03-16 |
11000 |
3 |
Rachel |
2010-12-01 |
9000 |
4 |
Emily |
2006-08-15 |
7000 |
5 |
Ashley |
2004-07-30 |
16000 |
… |
… |
… |
… |
【SPL 脚本】
A |
B |
|
1 |
=connect("db") |
/连接数据库 |
2 |
=A1.query("select * from EMPLOYEE") |
/查询员工表 |
3 |
[0,10,20] |
/定义入职年限区间 |
4 |
=A2.align@a(A3.len(),A3.pseg(year(now())-~,year(HIREDATE))) |
/使用函数 A.pseg(x,y) 获取入职时间所在区间 |
5 |
=A4.new(A3(#):EntryYears,~.avg(SALARY):AvgSalary) |
/统计每组的平均工资 |
A5的执行结果如下:
EntryYears |
AvgSalary |
0 |
6807.69 |
10 |
7417.78 |
20 |
7324.32 |
5. 获取排序后在原集合的位置
将有序集合的成员,通过一定的方法按关键字顺序排列的过程叫做排序。其目的是将一组“无序”的记录集合调整为“有序”的记录集合。有时候有序集合的原序是有意义的,例如查询出来的订单表是按时间顺序生成的,现在要按照销售额进行排序。但是时间顺序在后续的计算中还需要使用,希望按新条件排序的同时可以保留原序。
【例 7】 根据员工表,求年龄最大的三名员工的入职顺序。部分数据如下:
ID |
NAME |
BIRTHDAY |
HIREDATE |
1 |
Rebecca |
1974-11-20 |
2005-03-11 |
2 |
Ashley |
1980-07-19 |
2008-03-16 |
3 |
Rachel |
1970-12-17 |
2010-12-01 |
4 |
Emily |
1985-03-07 |
2006-08-15 |
5 |
Ashley |
1975-05-13 |
2004-07-30 |
… |
… |
… |
… |
【SPL 脚本】
A |
B |
|
1 |
=connect("db") |
/连接数据库 |
2 |
=A1.query("select * from EMPLOYEE order by HIREDATE") |
/使用函数 A.psort() 查询员工表并按入职时间排序 |
3 |
=A2.psort(BIRTHDAY) |
/获取员工生日排序后在排序前的序号 |
4 |
=A2(A3.to(3).sort()) |
/在员工表中按生日前三的员工序号选出 |
A4的执行结果如下:
ID |
NAME |
BIRTHDAY |
HIREDATE |
296 |
Olivia |
1968-11-05 |
2006-11-01 |
440 |
Nicholas |
1968-11-24 |
2008-07-01 |
444 |
Alexis |
1968-11-12 |
2010-12-01 |
6. 集合的整体定位
前面介绍了单个成员的定位运算,下面要介绍集合的整体定位。例如在集合 [a,b,c,d,e] 中定位集合 [c,d,a],返回结果为[3,4,1]。再比如在集合[a,b,c,d,e] 中定位集合[c,f],虽然 c 存在,但是 f 不存在,所以返回结果为空。
【例 8】 根据发帖记录表,按标签分组并统计各个标签出现频数。部分数据如下:
ID |
TITLE |
Author |
Label |
1 |
Easy analysis of Excel |
2 |
Excel,ETL,Import,Export |
2 |
Early commute: Easy to pivot excel |
3 |
Excel,Pivot,Python |
3 |
Initial experience of SPL |
1 |
Basics,Introduction |
4 |
Talking about set and reference |
4 |
Set,Reference,Dispersed,SQL |
5 |
Early commute: Better weapon than Python |
4 |
Python,Contrast,Install |
… |
… |
… |
… |
【SPL 脚本】
A |
B |
|
1 |
=connect("db") |
/连接数据库 |
2 |
=A1.query("select * from PostRecord") |
/查询发帖记录表 |
3 |
=A2.conj(Label.split(",")).id() |
/将标签按逗号分隔后合并到一起,获得没有重复值的全部标签。 |
4 |
=A2.align@ar(A3.len(),A3.pos(Label.split(","))) |
/使用函数 A.pos()整体定位帖子的标签在全部标签中的位置。再使用 align() 函数的 @r 选项,按照定位分组。 |
5 |
=A4.new(A3(#):Label,~.count():Count).sort@z(Count) |
/统计每个标签的帖子数量,按降序排列 |
A5的执行结果如下:
Label |
Count |
SPL |
7 |
SQL |
6 |
Basics |
5 |
… |
… |
7. 判断是否集合成员
有时候我们并不关心集合 B 的成员在集合 A 中的序号,只需要判断集合 A 中是否包含了集合 B 的所有成员。
【例 9】 根据各国官方语言表,查询官方语言同时包括中文和英文的国家。部分数据如下:
Country |
Language |
China |
Chinese |
UK |
English |
Singapore |
English |
Singapore |
Malay |
Singapore |
Chinese |
Singapore |
Tamil |
Malaysia |
Malay |
… |
… |
【SPL 脚本】
A |
B |
|
1 |
=connect("db") |
/连接数据库 |
2 |
=A1.query("select * from Language") |
/查询官方语言表 |
3 |
=A2.group(Country) |
/按国家分组 |
4 |
=A3.select(~.(Language).contain("Chinese","English")) |
/使用 A.contain() 函数判断当前国家的语言是否包含中文和英文。 |
5 |
=A4.(Country) |
/取出国家列表 |
A5的执行结果如下:
Member |
Singapore |
8. 定位主键值
当需要定位的字段是主键时,可以特殊处理。
【例 10】 在相互关联的产品表和类别表中,查询产品类别未出现在类别表中的有哪些。产品表和类别表的关系如下:
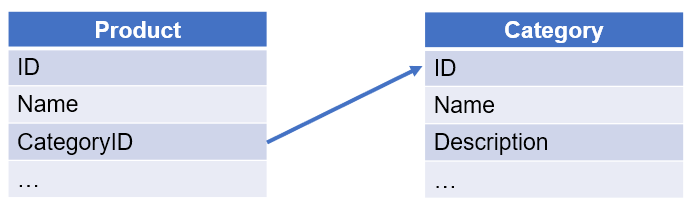
【SPL 脚本】
A |
B |
|
1 |
=connect("db") |
/连接数据库 |
2 |
=A1.query("select * from Category").keys(ID) |
/查询类别表,并设置主键为 ID |
3 |
=A1.query("select * from Product") |
/查询产品表 |
4 |
=A3.select(A2.pfind(CategoryID)==0) |
/使用 A.pfind() 函数在类别表中查找主键等于类别 ID 的序号,返回 0 说明不存在。在产品表中选出类别 ID 不存在的记录。 |
A4的执行结果如下:
ID |
Name |
CategoryID |
… |
12 |
German cheese |
… |
|
26 |
Spun sugar |
9 |
… |
9. 定位前 N 名 / 后 N 名
定位前 N 名 / 后 N 名是比较常见的计算。例如查询班级数学前三名,查询入职时间最短的五名员工等等。这一节要来介绍如何获取前 N 名 / 后 N 名成员所在的序号。
【例 11】 根据股市交易表,统计上证指数 2019 年收盘价最高的三天,相对前日的涨幅。部分数据如下:
Date |
Open |
Close |
Amount |
2019/12/31 |
3036.3858 |
3050.124 |
2.27E11 |
2019/12/30 |
2998.1689 |
3040.0239 |
2.67E11 |
2019/12/27 |
3006.8517 |
3005.0355 |
2.58E11 |
2019/12/26 |
2981.2485 |
3007.3546 |
1.96E11 |
2019/12/25 |
2980.4276 |
2981.8805 |
1.9E11 |
… |
… |
… |
… |
【SPL 脚本】
A |
B |
|
1 |
=file("000001.csv").import@ct() |
/导入数据文件 |
2 |
=A1.select(year(Date)==2019) |
/选出 2019 年的记录 |
3 |
=A2.ptop(-3, Close) |
/使用 A.ptop() 函数取出股市收盘价最高三天的记录序号,-3 表示从大到小取前三。如果是正整数表示从小到大取。 |
4 |
=A3.run(~=A2(~).Amount/A2(~+1).Amount-1) |
/循环用每天交易量和前日交易量计算涨幅 |
A3的执行结果如下:
Member |
154 |
156 |
157 |
A4的执行结果如下:
Member |
-0.0278 |
-0.0139 |
0.0112 |
《SPL CookBook》中还有更多相关计算示例。


英文版