


非常规聚合问题举例
【摘要】
聚合运算是指对数据进行计算,返回聚合结果。聚合运算经常伴随着分组运算,除了常见的求和、最大值、最小值、计数等聚合运算,还有一些逻辑运算等等。如何简便快捷的处理聚合问题,这里为你全程解析,并提供 esProc 示例代码。非常规聚合问题举例
1. 枚举分组后聚合求和
【例 1】 从城市 GDP 表中,分别统计直辖市、一线城市和二线城市的人均 GDP。城市 GDP 表部分数据如下:
ID |
City |
GDP |
Population |
1 |
Shanghai |
32679 |
2418 |
2 |
Beijing |
30320 |
2171 |
3 |
Shenzhen |
24691 |
1253 |
4 |
Guangzhou |
23000 |
1450 |
5 |
Chongqing |
20363 |
3372 |
… |
… |
… |
… |
【SPL 脚本】
A |
B |
|
1 |
=connect("db") |
/连接数据库 |
2 |
=A1.query("select * from GDP") |
/查询城市 GDP 表 |
3 |
[["Beijing","Shanghai","Tianjing","Chongqing"].pos(?)>0,["Beijing","Shanghai","Guangzhou","Shenzhen"].pos(?)>0,["Chengdu","Hangzhou","Chongqing","Wuhan","Xian","Suzhou","Tianjing","Nanjing","Changsha","Zhengzhou","Dongguan","Qingdao","Shenyang","Ningbo","Kunming"].pos(?)>0] |
/枚举直辖市、一线城市和二线城市 |
4 |
=A2.enum@r(A3,City) |
/按城市枚举分组 |
5 |
=A4.new(A3(#):Area,~.sum(GDP)/~.sum(Population)*10000:CapitaGDP) |
/统计每组的人均 GDP。其中用到了函数 sum() 求和 |
A5的执行结果如下:
Area |
CapitaGDP |
["Beijing","Shanghai","Tianjing","Chongqing"].pos(?)>0 |
107345.03 |
["Beijing","Shanghai","Guangzhou","Shenzhen"].pos(?)>0 |
151796.49 |
["Chengdu","Hangzhou","Chongqing","Wuhan","Xian","Suzhou","Tianjing","Nanjing","Changsha","Zhengzhou","Dongguan","Qingdao","Shenyang","Ningbo","Kunming"].pos(?)>0 |
106040.57 |
2. 合并重叠的时间区间
【例 2】 将客户 ANATR 有重复时间段的订单记录合并。客户表部分数据如下:
OrderID |
Customer |
SellerId |
OrderDate |
FinishDate |
10308 |
ANATR |
7 |
2012/09/18 |
2012/10/16 |
10309 |
ANATR |
3 |
2012/09/19 |
2012/10/17 |
10625 |
ANATR |
3 |
2013/08/08 |
2013/09/05 |
10702 |
ANATR |
1 |
2013/10/13 |
2013/11/24 |
10759 |
ANATR |
3 |
2013/11/28 |
2013/12/26 |
… |
… |
… |
… |
… |
【SPL脚本】
A |
B |
|
1 |
=connect("db") |
/连接数据源 |
2 |
=A1.query("select * from Orders where Customer='ANATR'order by OrderDate") |
/选出客户 ANATR 的订单信息,按订单日期排序 |
3 |
=A2.group@i(OrderDate>max(FinishDate[,-1])) |
/当订单日期大于前面所有订单的完成日期时分到新组 |
4 |
=A3.new(Customer,~.min(OrderDate):OrderDate,~.max(FinishDate):FinishDate) |
/使用函数 min() 计算每组最早的订单日期作为订单日期,使用函数 max 计算最晚的订单日期作为完成日期 |
A4的执行结果如下:
Customer |
OrderDate |
FinishDate |
ANATR |
2012/09/18 |
2012/10/17 |
ANATR |
2013/08/08 |
2013/09/05 |
ANATR |
2013/10/13 |
2013/11/24 |
ANATR |
2013/11/28 |
2013/12/29 |
… |
… |
… |
3. 在分组聚合中统计满足条件的数量
【例 4】 求一班各科不及格人数。成绩表部分数据如下:
CLASS |
STUDENTID |
SUBJECT |
SCORE |
Class one |
1 |
English |
84 |
Class one |
1 |
Math |
77 |
Class one |
1 |
PE |
69 |
Class one |
2 |
English |
81 |
Class one |
2 |
Math |
80 |
… |
… |
… |
… |
【SPL 脚本】
A |
B |
|
1 |
=connect("db") |
/连接数据库 |
2 |
=A1.query("select * from Scores where CLASS='Class one'") |
/查询一班学生成绩 |
3 |
=A2.groups(SUBJECT; count(SCORE<60):FailCount) |
/分组汇总,其中用到了函数 count() 统计不及格人数 |
A3的执行结果如下:
SUBJECT |
FailCount |
English |
2 |
Math |
0 |
PE |
2 |
4. 在布尔值构成的集合中,聚合时执行逻辑与运算
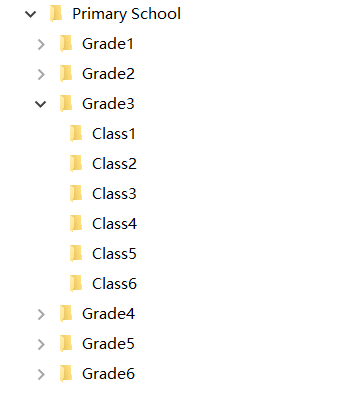
【例 5】 根据一系列某小学在线教学终端调查表,查看是否所有学生都能够使用手机。各班问卷及汇总目录如下:
ID |
STUDENT_NAME |
TERMINAL |
1 |
Rebecca Moore |
Phone |
2 |
Ashley Wilson |
Phone,PC,Pad |
3 |
Rachel Johnson |
Phone,PC,Pad |
4 |
Emily Smith |
Phone,Pad |
5 |
Ashley Smith |
Phone,PC |
6 |
Matthew Johnson |
Phone |
7 |
Alexis Smith |
Phone,PC |
8 |
Megan Wilson |
Phone,PC,Pad |
… |
… |
… |
【SPL 脚本】
A |
B |
C |
|
1 |
=directory@ps("D:/Primary School") |
/递归遍历目录,列出所有文件 |
|
2 |
for A1 |
=file(A2).xlsimport@t() |
/循环导入各班级问卷 excel 文件 |
3 |
=B2.([TERMINAL,"Phone"].ifn().split@c().pos("Phone") > 0)|@ |
/当问卷中终端未填写时不认为不支持手机终端,使用函数 ifn() 保证此项为 true。 |
|
4 |
=B3.cand() |
/使用函数 A.cand() 计算 B3 的成员是否都是 true |
A4的执行结果如下:
Value |
false |
5. 在布尔值构成的集合中,聚合时执行逻辑或运算
【例 6】 查询客户 RATTC,在 2014 年是否排进过单月销售额的前三名。销售表部分数据如下:
OrderID |
Customer |
SellerId |
OrderDate |
Amount |
10400 |
EASTC |
1 |
2014/01/01 |
3063.0 |
10401 |
HANAR |
1 |
2014/01/01 |
3868.6 |
10402 |
ERNSH |
8 |
2014/01/02 |
2713.5 |
10403 |
ERNSH |
4 |
2014/01/03 |
1005.9 |
10404 |
MAGAA |
2 |
2014/01/03 |
1675.0 |
… |
… |
… |
… |
… |
【SPL脚本】
A |
B |
|
1 |
=connect("db").query("select * from sales") |
/连接数据源,读取销售表 |
2 |
=A1.select(year(OrderDate)==2014) |
/选出 2014 年数据 |
3 |
=A2.group(month(OrderDate)) |
/将 2014 年的数据按照月份分组 |
4 |
=A3.(~.groups(Customer; sum(Amount):Amount)) |
/分组后的成员按照客户分组汇总销售额 |
5 |
=A4.new(~.top(-3; Amount):Top3) |
/循环每个月的数据,计算每月销售额前 3 的客户 |
6 |
=A5.(Top3.(Customer).pos("RATTC")>0) |
/判断每个月前三名是否包含客户 RATTC |
7 |
=A6.cor() |
/使用函数 A.cor() 计算 A6 的成员是否存在 true |
A7的执行结果如下:
Value |
false |
《SPL CookBook》中还有更多相关计算示例。

