


还不知道 SPL?你 OUT 了
作为数据相关的从业人员,你肯定对结构化数据不会陌生,我们无时不在与结构化数据打交道。比如,早上乘坐地铁上班产生的出入站信息是结构化数据,到公司打开编辑的 Excel 是结构化数据,从 OA 系统查询的考勤数据是结构化数据,在 ERP 系统录入的物料信息是结构化数据,统计的生产经营报表是结构化数据,工业设备采集的数据是结构化数据,数据库、大数据平台、文件系统存储的相当一部分还是结构化数据,金融、电信、能源、政府等企事业的核心系统产生的都是结构化数据…… 甚至很多非结构化数据(如图片、音视频)最后都要转成结构化数据再利用。结构化数据是我们这个时代最重要的数据种类,广泛存在于我们的工作生活中,以前是,以后也是。
当然,有数据就会有相应的数据处理技术。结构化数据处理历史悠久,相应的技术也有很多,包括最经常使用的 SQL(数据库),还有 Java、Python、Scala(Spark)、…。
而 SPL 呢,就是另一种结构化数据处理的技术。
SPL 全称为 Structured Process Language,结构化数据处理语言。目标是解决结构化数据处理中的两个问题:计算难和计算慢。我们处理数据通常都要编程序来做,SPL 也是一种程序语言,那么,也可以说 SPL 的目标是让程序容易写(Make Programming Easy)和让程序跑得快(Make Program Fast)。
为什么已经有了这么多结构化数据处理技术还要再发明 SPL 呢?
那当然是因为现有技术还不能满足 Make Programming Easy 和 Make Program Fast 这两个要求,特别是前者。
接下来我们就来再具体地看看,SPL 都有什么用,以及有什么好处。
Got SQL
应用计算
一直以来 SQL 都是结构化数据处理最主流的技术,使用者众多,相对其他技术 SQL 也算简单。但不幸的是,数据库的计算能力是封闭的,SQL 的能力也被封闭进了数据库,没有数据库就没法用 SQL 来做计算了。比如查询计算 CSV/Excel、解析 XML/JSON、处理 RESTful 返回数据、针对 MongoDB 做 JOIN 等。还有一些场景限于架构要求,虽然有数据库但也不提倡用,比如前后端分离、微服务等。
这种情况下,无 SQL 可用就只能使用 Java 等高级语言进行硬编码。但 Java 缺少必要的结构化计算类库,实现简单的分组汇总就要几十行代码,远没有 SQL 简单(一句 group by 就完事儿了)。比如在 Java 中完成一个简单的分组汇总要写成这样:
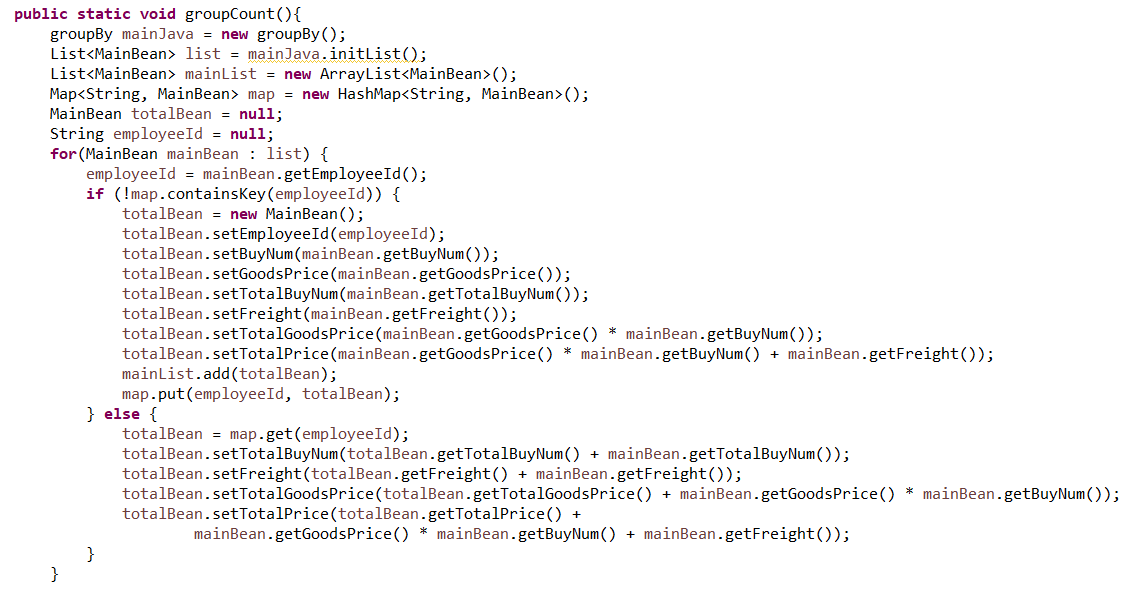
即使 Java8 增加了 Stream 以后,这种情况也没有明显改善。究其根本原因,Java 并非为结构化数据处理而设计,有些先天不足。而且,Java 作为编译型语言很难实施热部署,这对数据处理这类经常变化的业务非常不友好。
相对 Java,SPL 不仅提供了丰富的结构化计算类库,敏捷语法在计算实现上可以达到与 SQL 相当的简易程度,支持各类数据源访问以及之间的混合计算,解释执行天然支持热部署等。在无 SQL 可用时也可以很好完成这些场景下的数据处理任务。
上面的分组汇总使用 SPL 可以写成这样,相对 Java 简洁很多。
A |
|
1 |
=T(“duty.csv”) |
2 |
=A1.groups(name;count(name):cc) |
更多参考:
开源 SPL 助力 JAVA 处理公共数据文件(txt\csv\json\xml\xls)
开源 SPL,Webservice/Restful 的后处理利器
应用架构
因为数据库的封闭性,我们没法在数据库外利用数据库的计算能力。有时为了获得数据库的计算能力,被迫把本来清爽的体系结构弄得非常累赘,数据库内也搞得非常臃肿。
比如:
ETL 过程经常伴随复杂计算,这些计算如果使用 SQL(数据库)完成会比在库外用 Java 实施更方便,所以经常会将数据先装载(L)到数据库再计算(ET),形成 LET。本来应该在库外完成的任务都压给数据库,会引发数据库容量和性能问题,ETL 效率也很低。
还有涉及多样性数据源混合计算的情况也类似,在库外用 Java 完成过于复杂,将多源数据入库再借助数据库的计算能力可以简化工程实施难度。但这样做除了无法保证数据的实时性外,也会引发数据的容量和性能问题。
有时为了保证前端查询效率会将要查询的数据事先加工出来形成数据库中间汇总表,这些表由于后续还涉及计算,存储在数据库中可以继续使用 SQL 完成,其实还是为了数据库的计算能力。但中间表过多就会给数据库带来各种问题,同时多个应用共用中间表还会引发应用间的紧耦合,应用结构变得异常复杂。
同理在数据库中使用存储过程计算数据也是为了利用 SQL,但存储过程也会造成应用间的耦合性问题,也会引发数据库性能问题,而且创建使用存储过程需要较高的权限还会带来安全隐患。
类似的场景还有很多,这里就不一一列举了。这些场景无一例外都是为了使用 SQL(数据库计算能力)才不得不牺牲在架构上的优点。
其实这些场景如果用了 SPL 就可以不必再忍受糟糕的架构和臃肿的数据库以及其它问题。SPL 提供了不依赖于数据库的计算能力,我们不需要仅仅为了计算而部署数据库或把数据写入库中。比如在库外先进行数据清洗(E)和转换(T)再转载(L)到数据库实现真正的 ETL 可以有效缓解数据库压力,还能加速 ETL 进程;多样性数据源可以进行实时混合计算,不需要入库也能轻松完成多源数据处理;中间表可以从数据库中剥离出来采用文件存储,再使用 SPL 进行计算;存储过程也没必要再基于数据库,使用 SPL 在数据库外就能完成计算,实现“库外存储过程”……
通过 SPL 将数据和计算搬到数据库外,原来的数据库压力、耦合性、管理与安全难题等等就都不存在了,应用结构可以回归原来合理的形式,再也不必为了数据库的计算能力而屈服了。
更多参考:
Beyond SQL
写着简单
无 SQL 可用时可以通过 SPL 来补位,相对 Java 等其他技术 SPL 写的更简单,而且可以跟 Java 应用无缝集成嵌入使用。那么,是不是有 SQL 可用的时候就用不上 SPL 了呢?
并不是!SPL 还提供了超越 SQL 的能力。
我们在实际工作中经常要写复杂 SQL 计算数据,这些 SQL 通常不是按行而是按 KB 计。复杂 SQL 不仅写的困难,维护也不方便,经常出现作者过了一段时间自己也看不懂的尴尬情况。对于为何 SQL 难写,这里 SQL 为什么动不动就 N 百行以 K 计 做了更深入的分析。
那么我们能否通过 SPL 解决 SQL 写的难的问题呢?可以通过下面的例子感受一下。
计算目标:计算一支股票最长连续上涨了多少天?
SQL 的写法:
select max (consecutive_day)
from (select count(*) (consecutive_day
from (select sum(rise_mark) over(order by trade_date) days_no_gain
from (select trade_date,
case when closing_price>lag(closing_price) over(order by trade_date)
then 0 else 1 END rise_mark
from stock_price ) )
group by days_no_gain)
这个 SQL 恐怕读起来都有困难更别提写了。这说明什么问题?说明在面对复杂计算逻辑时 SQL 的表达能力很差。
而同样的计算逻辑用 SPL 可以这样写:
stock_price.sort(trade_date).group@i(closing_price<closing_price[-1]).max(~.len())
基本是按照自然思维方式写出来的,与 SQL 相比高下立判了。针对结构化数据计算,写的简单是 SPL 的第一目标。
更多 SPL 与 SQL 的对比可以参考:
跑得更快
SQL 除了难写,还有个问题是跑不快。
先来看一个例子:1 亿条数据中取前 10 名。这个任务用 SQL 写出来并不复杂:
SELECT TOP 10 x FROM T ORDER BY x DESC
但是,这个语句对应的执行逻辑是先对所有数据进行大排序,然后再取出前 10 个,后面的不要了。大家知道,排序是一个很慢的动作,会多次遍历数据,如果数据量大到内存装不下,那还需要外存做缓存,性能还会进一步急剧下降。如果严格按这句 SQL 体现的逻辑去执行,这个运算无论如何是跑不快的。然而,很多程序员都知道这个运算并不需要大排序,也用不着外存缓存,一次遍历用一点点内存就可以完成,也就是存在更高性能的算法。可惜的是,用 SQL 却写不出这样的算法,只能寄希望于数据库的优化器足够聪明,能把这句 SQL 转换成高性能算法执行,但情况复杂时数据库的优化器也未必靠谱。
软件没办法改变硬件的性能,CPU 和硬盘该多快就是多快。不过,我们可以设计出低复杂度的算法,也就是计算量更小的算法,这样计算机执行的动作变少,自然也就会快了。但是,光想出算法还不够,还要把这个算法用某种形式语言写得出来才行,否则计算机不会执行。而且,写起来还要比较简单,都要写很长很麻烦,也没有人会去用。所以呢,对于程序来讲,跑得快和写着简单其实是同一个问题,实现 Make Programming Easy 经常也就带来 Make Program Fast 了。
按照这个道理来看 Spark 等大数据技术也存在类似的问题,基于 DataFrame 机制不仅复杂运算描述困难,而且计算时由于无效运算多导致性能较差,强依赖内存涉及外存计算性能劣势非常明显。Spark 更多的关注点是希望通过集群(硬件)规模来提升计算性能,而非算法本身。况且,Spark 也在回归 SQL 不是。
SPL 则不同,SPL 提供了诸多高效算法(和存储机制),很多都是 SPL 的独创发明,在业内首次提出,有了这些基础类库,快速写出高性能数据处理代码也就不奇怪了。
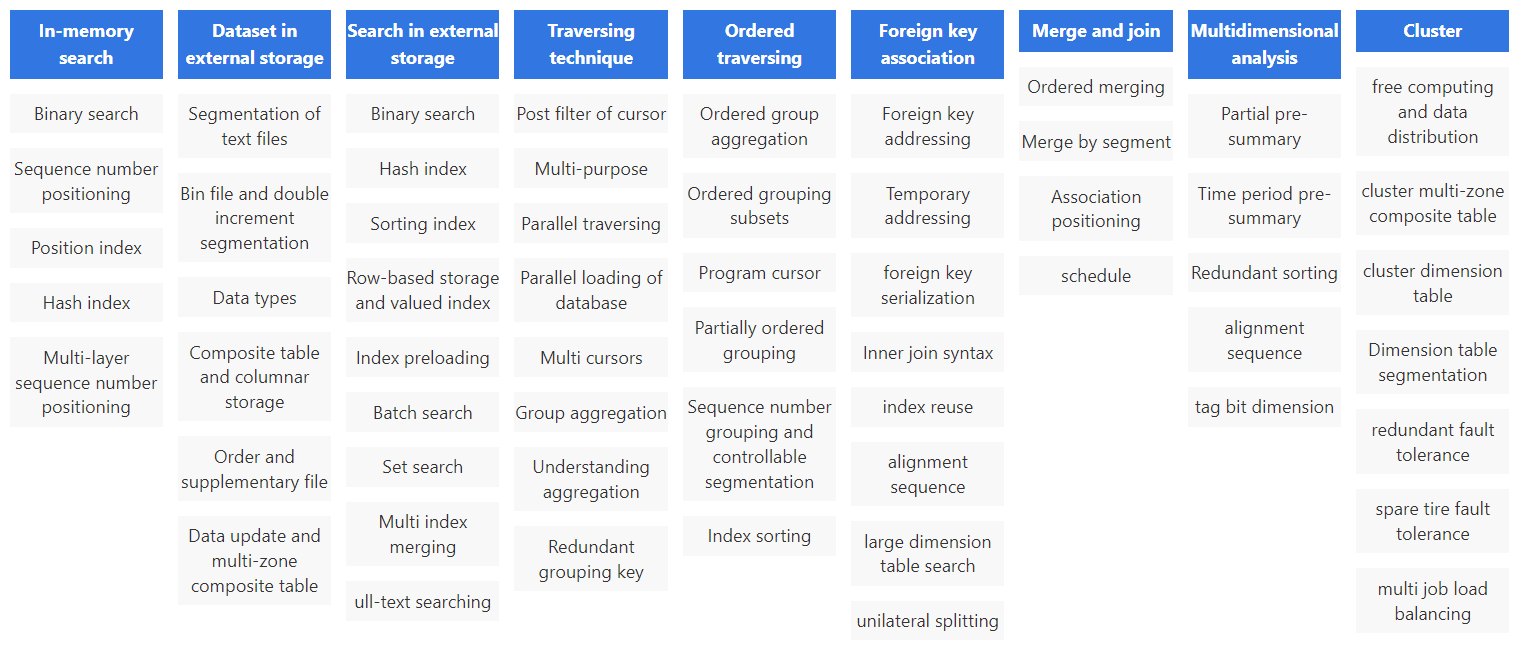
像前面例子中的 TopN 运算,在 SPL 中 TopN 被理解为聚合运算,这样可以将高复杂度的排序转换成低复杂度的聚合运算,而且很还能扩展应用范围。
A |
||
1 |
=file(“data.ctx”).open().cursor() |
|
2 |
=A1.groups(;top(10,amount)) |
金额在前 10 名的订单 |
3 |
=A1.groups(area;top(10,amount)) |
每个地区金额在前 10 名的订单 |
和 SQL 不同,SPL 完成这个运算的语句中没有排序字样,也就不会产生大排序的动作,在全集还是分组中计算 TopN 的语法基本一致,不仅写法上更简单,性能也更高。
关于 SPL 高性能部分的内容可以参考:
For Desktop
除了程序员要处理结构化数据外,其实日常职场人员也经常接触结构化数据,比如常见的 Excel、csv 等。这些数据如果都靠手动加工有时会很麻烦(比如把一堆 Excel 表格合并起来、用花名册生成员工卡片表格等),但如果通过编程来自动完成会方便很多。所以,对于职场人员也会面临使用编程实现办公自动化的需求。
目前可供职场人员使用的两个编程语言是 VBA 和 Python。前者随 Office 自带,免安装就可以使用比较方便,但 VBA 的结构化数据处理的能力有限,这可能也是很多人拥抱 Python 的原因。那 Python 表现怎么样呢?
很遗憾,也不好。Python 太难了,不仅安装复杂,想要处理结构化数据还要添加各种依赖包(Pandas),这对非专业人员就有点困难了。关键是,Pandas 本来就不是为结构化数据设计的,它并不是我们熟悉的表格(一行行数据的集合),而是个矩阵。用来处理结构化数据时,做些过滤合并这些简单运算还好点,碰到分组有序等复杂一些运算,就会让初学者摸不着头脑了。还有调试,你不可能一下子就把代码写对,调试对于学习程序语言也是特别有用的工具。Python 开发环境的调试功能本来就不太好,Pandas 又不是 Python 的原生内容,调试就更费劲。
在 零基础同学自学编程的正确姿势 这里更细致的给出了零基础同学自学编程的正确姿势,也细数了 Python 的不足,想要通过编程提升工作效率的小伙伴可要好好看看了。
相比之下,SPL 就非常适合职场人员学习掌握用来处理桌面数据。
SPL 精心设计的语法易学易通;直接计算 Excel 文件,还能对着文件执行 SQL(SPL 提供了 SQL 大部分能力,学 SQL 可以不用安装数据库);一键式安装,特色网格代码很容易调试等……
我们也可以通过一个例子感受 Python 和 SPL 的不同。像前面计算股票最长连涨天数的例子,用 Python 写:
import pandas as pd
aapl = pd.read_excel(‘d:/AAPL.xlsx’)
continue_inc_days=0 ; max_continue_inc_days=0
for i in aapl[‘price’].shift(0)>aapl[‘price’].shift(1):
continue_inc_days =0 if i==False else continue_inc_days +1
max_continue_inc_days = continue_inc_days if max_continue_inc_days < continue_inc_days else max_continue_inc_days
print(max_continue_inc_days)
这段代码看起来不算长,但看懂就要费点劲了,对于职场人员来说太难。而同样的计算 SPL 表达就很简洁(参考前面给的解法)了,也更适合非专业人员使用。
这里 帮你早下班 - esProc 桌面版与 Excel 数据处理 还有一系列处理 Excel 的 SPL 例程,可以涵盖大部分职场编程需求,帮助职场人员早下班可不是说说而已。
Do Intelligence
不仅如此,SPL 还可以用于工业智能计算。
嗯,你没看错。人工智能处理的大部分数据,还是结构化数据,只不过使用的算法比较特殊,不是通常碰到的统计汇总运算,而是矩阵、拟合之类的数学运算。这些运算 SQL 本来也不提供,当然也没法用 SQL 来做了。
而且,工业场景中有大量时序数据,时序数据库虽然提供 SQL,但由于 SQL 的有序计算能力很弱,无法协助计算,只能读出来再用高级语言处理,十分繁琐。
用 SPL 就能很好搞定了。SPL 支持有序计算,而且提供了丰富的数学函数,如矩阵、拟合等:
-
时序游标:按粒度聚合、平移、相邻引用、关联合并
-
历史数据压缩固化,透明引用
-
向量与矩阵运算
-
各种线性拟合:最小二乘、偏最小二乘、lasso、ridge、…
-
…
这样,就能够更方便地应对工业场景的计算需求。
同时,由于智能算法和场景及数据相关性很强,常常需要反复实验才能做出来可用的结果,如果开发效率太低(Make Programming Easy 不够),同样时间尝试次数就太少了(如 Java),而借助 SPL 的敏捷语法可以让这个过程的迭代效率更高,同时间内可以尝试更多算法。
下面是我们用 SPL 成功地实现过的一些工业智能算法:
-
仪表异常发现算法
-
异常测量样本定位
-
曲线升降及振荡模式识别
-
有约束线性拟合
-
管道传输调度算法
-
…
结语
无处不在的结构化数据带来了结构化数据处理技术的广泛性,SPL 也会同样显得无处不在。报表数据源、ETL、大数据计算、文本分析、Excel 处理、Java 计算中间件、数据网关、工业智能计算、…. 都能应用 SPL 满足并改善现有问题,相对其他技术也更有优势。从这个角度来看,我们再去理解 SPL 为什么有那么多应用场景也就合情合理了。

