


SQL 和 SPL 的等值分组对比
【摘要】
把集合中具有相同属性的成员分配到同一个组,这就是分组运算。比如员工表根据部门分组,每组的员工都具有相同的部门;销售表可以根据销售年份分组,每组都是同一个年份的销售记录等等。SQL 和 SPL 是大家比较熟悉的程序语言,本文将探讨对于分组问题,这两种语言的解决方案和基本原理。如何简便快捷的处理分组运算,这里为你全程解析,并提供 SQL 和 SPL 示例代码。SQL 和 SPL 的等值分组对比
一. 分组汇总
有时候我们需要将数据按不同类型进行统计,这就要用到分组汇总。分组汇总是指根据一定的规则将数据进行分组,然后针对每个分组进行聚合运算。
统计每位学生的总分: |
分组 |
汇总 |
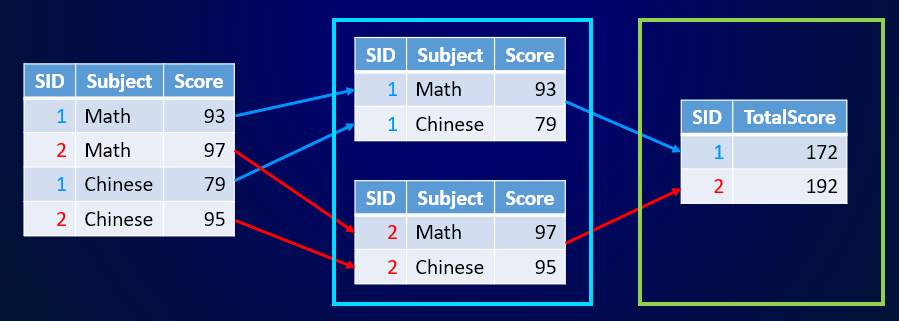
使用过 SQL 或 SPL 的朋友对分组汇总都不会陌生。在 SQL 中,GROUP BY 语句可以用来分组汇总。GROUPY BY 经常和聚合函数 SUM、COUNT 等一起出现,用来将查询结果按照某些字段进行归类分组,并汇总统计。SPL 则提供了函数 groups() 用于分组汇总。
【例 1】 根据销售表,查询 2014 年每个月的总销售额。部分数据如下:
ID |
CUSTOMERID |
ORDERDATE |
SELLERID |
PRODUCTID |
AMOUNT |
10400 |
EASTC |
2014/01/01 |
1 |
27 |
3063.0 |
10401 |
HANAR |
2014/01/01 |
1 |
17 |
3868.6 |
10402 |
ERNSH |
2014/01/02 |
8 |
70 |
2713.5 |
10403 |
ERNSH |
2014/01/03 |
4 |
42 |
1005.9 |
10404 |
MAGAA |
2014/01/03 |
2 |
74 |
1675.0 |
… |
… |
… |
… |
… |
… |
SQL的解决方案:
select
extract (month from ORDERDATE) MONTH, sum(AMOUNT) AMOUNT
from
SALES
where
extract (year from ORDERDATE)=2014
group by
extract (month from ORDERDATE)
order by
MONTH
在 SQL 语句中,GROUP BY 语句用于根据 BY 语句的分组字段进行分组汇总。GROUP BY 语句中 SELECT 指定的字段必须是分组字段,其他字段若想出现在 SELECT 中则必须包含在聚合函数中。可以使用 WHERE 语句,在分组汇总前对数据进行过滤。
另外,这里是以 ORACLE 为例,其他数据库计算年份和月份时,可以使用函数 YEAR 和 MONTH。
SPL的解决方案:
在 SPL 中提供了函数 A.groups() 用于分组汇总。
A |
|
1 |
=T("Sales.csv").select(year(ORDERDATE)==2014) |
2 |
=A1.groups(month(ORDERDATE):MONTH; sum(AMOUNT):AMOUNT) |
A1:从文件中导入销售表,并选出 2014 年的记录。
A2:使用函数 A.groups() 按月份分组汇总每个月的总销售额。
SPL同样也支持从数据库中读取数据表,比如A1可以改为:
A |
|
1 |
=connect("db").query("select * from SALES where extract (year from ORDERDATE)=2014") |
【例 2】 查询在纽约州平均年龄低于 40 岁的部门。部分数据如下:
ID |
NAME |
BIRTHDAY |
STATE |
DEPT |
SALARY |
1 |
Rebecca |
1974/11/20 |
California |
R&D |
7000 |
2 |
Ashley |
1980/07/19 |
New York |
Finance |
11000 |
3 |
Rachel |
1970/12/17 |
New Mexico |
Sales |
9000 |
4 |
Emily |
1985/03/07 |
Texas |
HR |
7000 |
5 |
Ashley |
1975/05/13 |
Texas |
R&D |
16000 |
… |
… |
… |
… |
… |
… |
SQL的解决方案:
select
DEPT, avg(TRUNC(months_between(sysdate, BIRTHDAY)/12)) AVGAGE
from
EMPLOYEE
where
STATE='New York'
group by
DEPT
having
avg(TRUNC(months_between(sysdate, BIRTHDAY)/12))<40
在 SQL 语句中,分组汇总前的选出需要使用 WHERE 语句,分组汇总后的选出需要使用 HAVING 语句。
SPL的解决方案:
A |
|
1 |
=T("Employee.csv").select(STATE=="New York") |
2 |
=A1.groups(DEPT; avg(age(BIRTHDAY)):AVGAGE) |
3 |
=A2.select(AVGAGE<40) |
A1:导入员工表,并选出纽约州的记录。
A2:使用函数 A.groups() 按部门分组统计平均年龄。
A3:在分组汇总后的结果集中选出平均年龄小于 40 的记录。
SPL中无论在分组前后,都可以使用函数 A.select()进行选出。 SPL 提供了函数 age(),可以直接根据员工出生日期计算出年龄。
【例 3】 根据销售表,统计 2014 年客户排进每月单笔销售额前三名的次数。部分数据如下:
ID |
CUSTOMERID |
ORDERDATE |
SELLERID |
PRODUCTID |
AMOUNT |
10400 |
EASTC |
2014/01/01 |
1 |
27 |
3063.0 |
10401 |
HANAR |
2014/01/01 |
1 |
17 |
3868.6 |
10402 |
ERNSH |
2014/01/02 |
8 |
70 |
2713.5 |
10403 |
ERNSH |
2014/01/03 |
4 |
42 |
1005.9 |
10404 |
MAGAA |
2014/01/03 |
2 |
74 |
1675.0 |
… |
… |
… |
… |
… |
… |
SQL的解决方案:
select
CUSTOMERID, count(*) COUNT
from
(select
CUSTOMERID,
ROW_NUMBER()OVER(PARTITION BY extract (month from ORDERDATE) ORDER BY AMOUNT DESC) MONTH_RANK
from SALES
where extract (year from ORDERDATE)=2014)
where MONTH_RANK<=3
group by CUSTOMERID
order by CUSTOMERID
在分组时计算排名是很常用的需求,但是 SQL 的 GROUP BY 语句并不支持排名函数。所以我们需要使用 ROW_NUMBER,RANK,DENSE_RANK 等函数,进行分组后的排名计算,不能使用 GROUP BY 语句。
SPL的解决方案:
A |
|
1 |
=T("Sales.csv").select(year(ORDERDATE)==2014) |
2 |
=A1.groups(month(ORDERDATE):MONTH; top(-3;AMOUNT):TOP3) |
3 |
=A2.conj(TOP3).groups(CUSTOMERID; count(~):COUNT) |
A1:导入销售表,并选出 2014 年的记录。
A2:使用函数 A.groups() 按月份分组汇总前三名。
A3:将每月前三名的记录合并后,使用函数 A.groups() 按客户分组统计次数。
在 SPL 中,函数 A.groups() 不仅支持 sum,count,avg,max,min 等 SQL 支持的聚合函数,还支持一些比较常用,但是 SQL 的 GROUP BY 语句并不支持的聚合函数:top(取前 N 名 / 后 N 名)、iterate(迭代函数)、icount(唯一值计数)、median(中位数,部分数据库支持)等等。
【例 4】 统计每个班级各科的得分中位数和不及格(低于 60 分)人数。部分数据如下:
CLASS |
STUDENTID |
SUBJECT |
SCORE |
1 |
1 |
English |
84 |
1 |
1 |
Math |
77 |
1 |
1 |
PE |
69 |
1 |
2 |
English |
81 |
1 |
2 |
Math |
80 |
… |
… |
… |
… |
SQL的解决方案:
select
t1.CLASS,t1.SUBJECT,t1.MEDIAN_SCORE,
nvl(t2.FAIL_COUNT,0) FAIL_COUNT
from
(select CLASS, SUBJECT, median(SCORE) MEDIAN_SCORE
from SCORES
group by CLASS, SUBJECT
order by CLASS, SUBJECT) t1
left join
(select CLASS, SUBJECT, count(*) FAIL_COUNT
from SCORES
where SCORE<60
group by CLASS, SUBJECT) t2
on t1.CLASS=t2.CLASS and t1.SUBJECT=t2.SUBJECT
在 SQL 中统计不及格人数时,需要在 WHERE 语句中选出低于 60 分的记录,再通过函数 COUNT 来计数。这就导致计算不及格人数和计算得分的中位数不能同时进行。
另外这里还是以 ORACLE 为例,ORACLE 有函数 MEDIAN 可以用于计算中位数,但是有些数据库是并不支持计算中位数的。这种情况就有些麻烦了,我们可以利用排序后的行号来计算中位数。
SPL的解决方案:
A |
|
1 |
=T("Scores.csv") |
2 |
=A1.groups(CLASS,SUBJECT; median(,SCORE):MEDIAN_SCORE, count(SCORE<60):FAIL_COUNT) |
A1:导入成绩表。
A2:使用函数 A.groups() 按班级和科目分组汇总中位数和不及格人数。
在 SPL 中,函数 count() 可以直接使用参数“SCORE<60”来统计不及格人数,不需要先选出不及格的记录,再进行计数。这样就可以很方便的同时计算中位数和统计人数了。
二. 分组子集
分组运算的实质是将一个集合按照某种规则拆分成若干个子集,也就是说,返回值应当是一个由集合构成的集合。对于每个成员集合,我们称为分组子集。
严格来说,分组和汇总是两个独立的动作,但在 SQL 中总是一起出现,从而给人一种两者必须同时使用的假象。事实上,这种组合是对分组操作的一种局限,或者说分组之后,能够进行的计算远不止 SQL 中的几种聚合函数。
在 SPL 中提供了函数 group(),我们可以用它来实现真正的分组,分组后的结果集是由多个分组子集组成的集合:
按学生分组: |
分组 |
分组子集 |

通常人们对分组子集的聚合值更感兴趣,因此分组运算常常伴随着对子集的进一步汇总计算。但是,我们仍然有对这些分组子集而不是聚合值更感兴趣的时候。
【例 5】 根据员工表,找出有相同出生日期的员工。部分数据如下:
ID |
NAME |
BIRTHDAY |
STATE |
DEPT |
SALARY |
1 |
Rebecca |
1974/11/20 |
California |
R&D |
7000 |
2 |
Ashley |
1980/07/19 |
New York |
Finance |
11000 |
3 |
Rachel |
1970/12/17 |
New Mexico |
Sales |
9000 |
4 |
Emily |
1985/03/07 |
Texas |
HR |
7000 |
5 |
Ashley |
1975/05/13 |
Texas |
R&D |
16000 |
… |
… |
… |
… |
… |
… |
SQL的解决方案:
在 SQL 中并不支持真正的分组,无法保留分组子集。我们只能先按照出生日期分组统计每组的人数,选出人数大于 1 的生日。再从员工表重新选出记录,使用内连接与之前选出的生日来过滤。本来只需要一次分组就可以解决的问题,却又多了一次查询和连接过滤。SQL 语句如下:
select *
from EMPLOYEE t1
inner join
(select BIRTHDAY
from EMPLOYEE
group by BIRTHDAY
having count(*)>1) t2
on t1.BIRTHDAY=t2.BIRTHDAY
SPL的解决方案:
SPL提供了函数 A.group() 用于真正的分组。
A |
|
1 |
=T("Employee.csv") |
2 |
=A1.group(BIRTHDAY) |
3 |
=A2.select(~.len()>1).conj() |
A1:导入员工表。
A2:使用了函数 A.group() 按出生日期分组。
A3:选择分组子集的成员数量大于 1 的分组,即有相同出生日期的。再将分组子集合并。
与 SQL 相比,SPL 的脚本十分简洁。这是因为 SPL 的分组,是真正的分组,每一个分组子集是具有相同出生日期的员工记录的集合。
【例 6】 根据员工表,查询年龄低于部门平均年龄的员工。部分数据如下:
ID |
NAME |
BIRTHDAY |
STATE |
DEPT |
SALARY |
1 |
Rebecca |
1974/11/20 |
California |
R&D |
7000 |
2 |
Ashley |
1980/07/19 |
New York |
Finance |
11000 |
3 |
Rachel |
1970/12/17 |
New Mexico |
Sales |
9000 |
4 |
Emily |
1985/03/07 |
Texas |
HR |
7000 |
5 |
Ashley |
1975/05/13 |
Texas |
R&D |
16000 |
… |
… |
… |
… |
… |
… |
SQL的解决方案:
使用 SQL 分组汇总时,只支持 SUM、COUNT、AVG、MAX、MIN 等聚合函数,除此之外不能进行其他复杂运算。我们只能先使用 GROUP BY 语句分组汇总每个部门的平均年龄,再查询员工表,通过内连接选出低于平均年龄的员工。
select *
from EMPLOYEE t1
inner join
(select
DEPT, avg(TRUNC(months_between(sysdate, BIRTHDAY)/12)) AVG_AGE
from EMPLOYEE
group by DEPT) t2
on t1.DEPT=t2.DEPT and
TRUNC(months_between(sysdate, t1.BIRTHDAY)/12)<t2.AVG_AGE
SPL的解决方案:
前面已经介绍过,在 SPL 中函数 A.group()用于分组。我们可以在函数 A.group() 中,定义在分组后对每个分组子集的运算。不限于 SQL 支持的 SUM、COUNT 等聚合运算,可以定义一些复杂运算。
A |
|
1 |
=T("Employee.csv") |
2 |
=A1.group(DEPT; (a=~.avg(age(BIRTHDAY)), ~.select(age(BIRTHDAY)<a)):YOUNG) |
3 |
=A2.conj(YOUNG) |
A1:导入员工表。
A2:按部门分组,并在每个分组中选出年龄低于平均年龄的记录。在函数 A.group() 的聚合运算中,我们可以使用临时变量,使得运算更加简单易懂。
A3:将选出的记录合并。
【例 7】 根据员工表,选出员工人数超过 50 人的州,查询这些州各部门的平均工资。部分数据如下:
ID |
NAME |
BIRTHDAY |
STATE |
DEPT |
SALARY |
1 |
Rebecca |
1974/11/20 |
California |
R&D |
7000 |
2 |
Ashley |
1980/07/19 |
New York |
Finance |
11000 |
3 |
Rachel |
1970/12/17 |
New Mexico |
Sales |
9000 |
4 |
Emily |
1985/03/07 |
Texas |
HR |
7000 |
5 |
Ashley |
1975/05/13 |
Texas |
R&D |
16000 |
… |
… |
… |
… |
… |
… |
SQL的解决方案:
按照正常的逻辑,我们应该先按州进行分组,选出员工人数超过 50 的州。再将每个州的员工按部门进行分组汇总平均工资。但是由于 SQL 的 GROUP BY 语句无法保留分组子集,实现起来就变得非常复杂。我们先将员工按州分组,选出人数大于 50 人的州。再将员工按州和部门两个字段进行分组,统计每个州各部门的平均工资。最后将两个结果集内连接,选出大于 50 人的州且年龄低于部门平均年龄的记录。SQL 语句如下:
select
t1.STATE,DEPT,AVG_SALARY
from
(select
STATE,DEPT,AVG(SALARY) AVG_SALARY
from EMPLOYEE
group by STATE,DEPT
order by STATE,DEPT) t1
inner join
(select
STATE, COUNT(*)
from EMPLOYEE
group by STATE
HAVING COUNT(*)>50) t2
on t1.STATE=t2.STATE
SPL的解决方案:
分组本身是复杂运算,保留分组子集可重复使用,提高运行效率。在 SPL 中,函数 A.group() 在分组后可以保留分组子集,可以针对分组子集再次进行分组汇总等运算。
A |
|
1 |
=T("Employee.csv") |
2 |
=A1.group(STATE).select(~.len()>50) |
3 |
=A2.conj(~.groups(DEPT; avg(SALARY):AVG_SALARY).derive(A2.~.STATE:STATE)) |
A1:导入员工表。
A2:按州进行分组,并选出员工数大于 50 人的分组子集。
A3:对每个州的分组子集再按部门分组汇总平均工资,再把这些结果集合并。
总结
SPL的分组与 SQL 的分组有着本质上的区别。 SQL 的分组除了只能得到分组汇总的结果,查询时也只能选出分组时使用的字段和聚合结果。而 SPL 的分组是真正的分组,将具有相同属性的记录分在一组,分组子集中保留了数据的全部信息。分组本身是复杂运算,保留分组子集可重复使用,提高运行效率。
另外,当查询比较复杂时,SQL 语句的复杂程度会成倍增加。比如经常要用到临时表、嵌套查询等等,使得 SQL 语句的编写和维护难度提升。而 SPL 只要按自然思维去组织计算逻辑,逐行书写出简洁的代码。
esProc 是专业的数据计算引擎,基于有序集合设计,同时提供了完善的分组运算,相当于 Java 和 SQL 优势的结合。在 SPL 的支持下,分组运算会非常容易。
SQL 与 SPL 对比系列:
SQL 和 SPL 的集合运算对比
SQL 和 SPL 的选出运算对比
SQL 和 SPL 的有序运算对比
SQL 和 SPL 的等值分组对比
SQL 和 SPL 的非等值分组对比
SQL 和 SPL 的有序分组对比
SQL 和 SPL 的一对一和一对多连接对比
SQL 和 SPL 的多对一连接对比
SQL 和 SPL 的多对多连接对比
SQL 和 SPL 的基本静态转置对比
SQL 和 SPL 的复杂静态转置对比
SQL 和 SPL 的动态转置对比
SQL 和 SPL 的递归对比 Salescsv

