


爱恨交加的存储过程该往何处去?
针对存储过程优缺点的讨论(争论)由来已久,这里我们不妨来详细盘点一下存储过程的利与弊。
先说优点
毕竟还是有不少人在用,总要有点好处。
SQL 过程化
很少人提及存储过程的这个优点,似乎是认为理所当然。SQL 的语法要求数据处理必须写成一句,不管嵌套几层、用多少子查询,这对复杂数据处理简直是灾难。而存储过程让 SQL 也能支持分步计算,虽然是多个独立 SQL 语句拼接、虽然可能要频繁写临时表、虽然… ,但至少过程化解决了多少人的数据处理困难。
但是,过程计算并不是存储过程的专利,使用 Java 来指挥 SQL 也一样可以,仅此一条优点并不足以导致程序员偏爱存储过程。
界面与逻辑分离
界面与逻辑分离是现代应用开发的一个基本准则。相对于后台数据处理逻辑,界面会有更多样性的环境,如 PC、手机等,而且业务稳定性也不强,经常会改。如果能把两者分离,开发和维护界面时不必绑着数据处理逻辑一起改,成本就低很多。
使用存储过程能实现界面与逻辑分离。存储过程在后台数据库中运算,只要向前端提供数据,而不必关心界面的形式和异动。把所有的数据处理逻辑都写成存储过程,还有利于统一数据的出入口,易于实现数据权限管控。
再说一遍“但是”,实现界面与逻辑分离也不是存储过程的专利。只要做一个数据访问层,所有数据的进出都通过这个访问层,也会有同样效果,事实上也确实有些应用是这么做的,但在微服务流行以前并不普遍。这个原因在于开发复杂度上,处理结构化数据写 SQL 总比写 Java 要简单多得多。而微服务架构强制在 Java 中实现数据处理逻辑的机制,其实是牺牲了开发效率。
性能好
通常,使用存储过程会比在库外用 Java 指挥 SQL 完成数据处理性能更好一点。这个原因主要在于数据不出库。外部程序访问库内数据时必须通过数据库提供的接口,而这些接口的性能大都不好,特别是面向 Java 程序的 JDBC 接口。每次发出 SQL 让数据库执行都会调用这个接口,速度就上不去。如果应用程序和数据库不在同一台物理机器上时,还会有一些网络延迟,不过和接口的低性能相比并不算严重。在外部计算时,从数据库获取数据的时间常常会超过计算本身的时间。
存储过程的性能好主要得益于数据库低效的访问接口。
总结一下。存储过程的优点主要来源于两方面:一是 SQL 的数据处理能力,至少目前来看结构化数据处理尤其是复杂计算,SQL 仍然比 Java 强很多。二是库内计算的便利,数据不用出库省下的 IO 成本对数据密集型任务有莫大优势。
再说缺点
传说阿里有一条军规,“禁止使用存储过程,存储过程难以调试和扩展,更没有移植性”。我们这就来罗列一下存储过程的缺点。
移植性差
存储过程的移植确实很困难,一般业务逻辑复杂到需要写存储过程的地步,总会不可避免地用到数据库独有的特性和语法,更换数据库时这部分代码就需要重写。如果只是简单地替换函数名和参数规则(如日期转换等),那成本还不高;如果用到了新数据库不支持的某种特性,那还要重新设计算法来编写计算逻辑;如果还要再兼顾性能因素,有时候就会是个不可能完成的任务了。
调试困难
编辑调试是个大问题,存储过程的开发一直缺少有效的 IDE 环境。SQL 本身经常很长,调试式要把句子拆开分别独立执行,非常麻烦。存储过程中也常常有大量的长 SQL,当然也有同样的问题。即使是分步的运算,因为没有好的 IDE 支持,要看哪一步出错,也要把中间结果输出才行,仍然是非常麻烦。
存储过程的调试功能近年来略有起色,但离流畅实用始终差距甚远,数据库厂商似乎也无心解决。这和 Java 等拥有成熟的开发环境完全不可同日而语。困难的调试自然会导致低下的开发效率。
体系封闭
说到封闭性,其实是数据库的问题。数据库有“库”的概念,外部数据只有入库才能计算。而现代应用数据源众多,临时转入的效率很低(因为数据库的 IO 成本高),很可能跟不上访问需求,定时批量转入又很难获得最新的数据,同样影响计算结果的实时性。同时,ETL 往往有时间窗口(如当天夜里到第二天凌晨),赶上业务繁忙的时候还可能因为时间窗口不足无法完成 ETL 工作而影响第二天的业务。
不仅如此,把外部数据存储在数据库中,又会形成众多中间表,面临中间表的各种问题。而且有些互联网上取过来的数据常常是多层的 json 或 XML 格式,在关系数据库中还要建立多个关联的表来存储,会进一步加剧中间表的问题,占用过多宝贵的数据库空间。
存储过程在数据库中运算自然继承了封闭性的特点,想混合计算外部数据很不方便。
耦合性高
存储过程通常是为前端应用服务的,理论上两者应该在一起,从而组成完整的业务功能点。但存储过程与数据库紧密耦合,所以实践中存储过程与前端应用是物理分离的,且无法使用统一的技术路线。对于同一个功能点的存储过程和前端应用,维护其中一处,通常就要维护另一处,但两者物理上分离,维护因此变得很困难,而不统一的技术路线则加剧了这种困难。
存储过程与数据库紧密耦合,反而与前端应用分离,这就容易使同一个存储过程被多个前端应用共享。时间一长,哪个存储过程到底被哪些应用调用就变成了谜团。如果某个应用的计算发生变化,面对谜团一般的共享调用关系,管理员只能新建存储过程而不敢修改原存储过程。这样恶性循环下去,存储过程越来越多,谜团越来越大,终将变得不可收拾。
管理困难
存储过程的目录是扁平的,而不是文件系统那样的树形结构,脚本少的时候还好办,一旦多起来,目录就会陷入混乱。可以想象,多个项目的存储过程、同一个项目不同模块的存储过程、同一模块不同年份或不同版本的存储过程,这些如果混杂在同一个目录下,区分起来会非常困难,除非加大管理幅度,比如按项目、模块、年代、版本命名,这显然又会影响开发效率。有些项目管理较弱的团队,在开发周期紧张时,常常就顾不得这些规矩了,先赶着让项目上线再说,而上线之后这些遗留问题又容易被忘掉,结果常常一直存在很久。
安全性差
很多存储过程是为查询分析服务的,而这类业务的需求经常在变,由于存储过程与数据库紧密结合,所以程序员每次修改存储过程代码之后,都要提交给数据库管理员,由管理员编译并发布,无疑会大大增加管理员的工作负担。所以通常的做法是:给程序员赋予高级权限,至少也是创建存储过程的权限,这样就不用频繁打扰管理员了。这样做虽然方便,但存在严重的安全隐患。本来做报表查询只需要对数据库有“读”权限,而可以编译存储过程的权限就太大了,几乎可以做一切了。程序员如果失误,很可能删除或修改了数据,造成严重的安全事故。
开源 SPL 充当库外存储过程
从罗列的优缺点数量上看,缺点比优点多不少,所以就不难理解阿里的军规了:存储过程能不用还是不要用了。当然了,用不用存储过程完全是自己综合自己的情况考虑,如人饮水冷暖自知。
其实存储过程也并非不可替代,开源 SPL 就可以搞定存储过程的各类缺点,同时延续其优点, 实现“库外存储过程”。
集算器 SPL 是一款专业的开源数据计算引擎,提供不依赖数据库的计算能力,数据库更换不需要更改 SPL 计算脚本,解决存储过程的移植性问题;简洁易用的 IDE 环境编辑调试功能齐全,算法实现更加简单;SPL 体系更加开放,可以直接使用多样数据源计算;“外置存储过程”不依赖数据库,可随应用存放解决耦合性问题;借助文件系统的树状结构进一步解决管理问题;SPL 独立数据库运行,更不会带来安全问题。
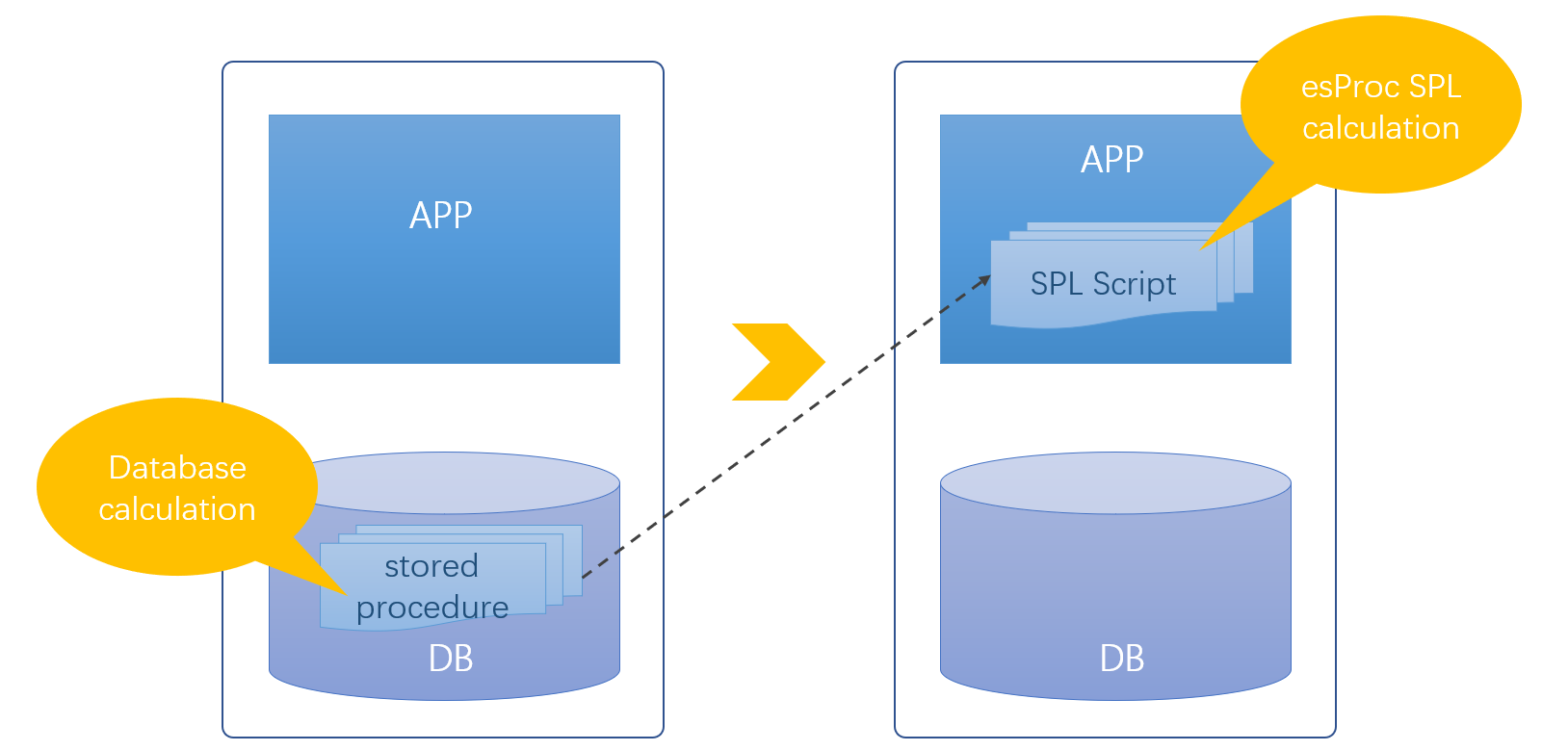
SPL 在库外实现存储过程,不再依赖数据库,这样原来绑定数据库带来的各种问题也就解决了。
直观易用的开发环境
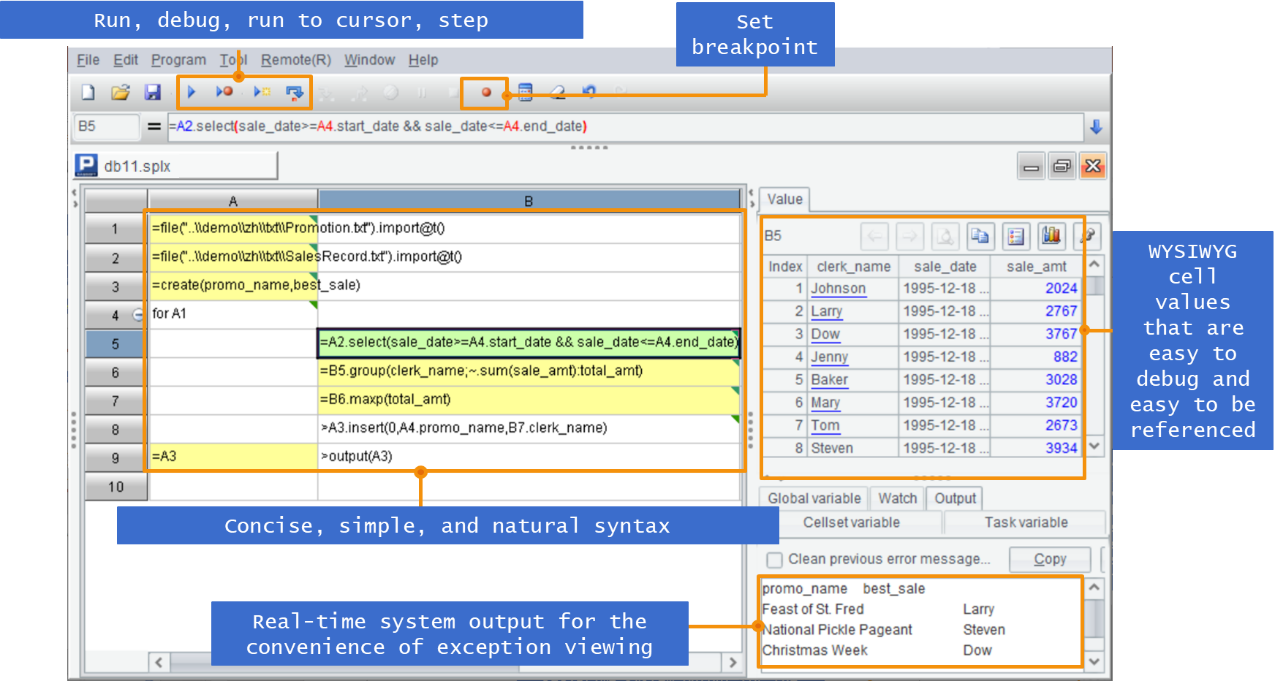
相对存储过程的编辑调试困难,SPL 提供了简洁易用的开发环境,单步执行、设置断点,所见即所得的结果预览窗口…,开发效率更高。
库外计算降低耦合性,提升移植性与安全性
SPL 提供了不依赖数据库的计算能力,在库外实施计算。原来不得不依赖存储过程的两个能力(计算和分步)完全可以使用 SPL 替代,实现“库外存储过程”。这样原本紧耦合在数据库中的计算逻辑可以完全独立到应用中,从而降低与数据库的耦合性。
与数据库解耦以后,数据库变化无需修改 SPL 的计算逻辑,可以做到轻松移植。同时,SPL 实现的“库外存储过程”创建和使用不需要对数据库有写权限,使用存储过程带来的安全性问题就可以彻底避免。
在运维方面,SPL 是解释执行的,天然支持热切换。可以很好适应微服务架构下多变的服务修改需求,应用修改不需要重启即时生效。

数据处理逻辑位于 SPL 文件(.splx)中,修改后实时生效,相对 Java 等编译型语言需要重启服务有很大优势。
在管理方面,SPL 文件使用文件系统管理机制,树状结构可以很清晰地存放各个应用、各个模块的计算逻辑,不会不知道有哪些模块在使用的情况,使用和管理都很方便。
多源支持与开放体系
不同于数据库需要数据先入库再计算,SPL 面对多样性数据源时可以直接计算。数据入库不仅时效性差,也无法保证数据的实时性。此外不同数据源有各自的优点,文件的 IO 效率很高,NoSQL 可以存储文档数据,RDB 计算能力较强,数据入库就无法享受这些优点了。
SPL 提供了开放的数据源支持,你听说过还是没听说过的数据源几乎都能支持,不仅可以连接取数,还可以进行跨数据源混合计算。SPL 可以充分利用各类数据源的优点后,再实施跨源计算也更加高效。

开放体系下,不再有“库”的概念,充分利用各类数据源的特点,发挥其优势。
支持过程的简洁代码提高开发效率
存储过程虽然支持过程计算,但 SQL 本身在实现复杂计算时就比较困难,这是由 SQL 的特性(缺乏离散性、集合化不彻底等)决定的,比如根据股票记录查询某只股票最长连续上涨天数,SQL(oracle)的写法如下:
SELECT code, MAX(ContinuousDays) - 1
FROM (
SELECT code, NoRisingDays, COUNT(*) ContinuousDays
FROM (
SELECT code,
SUM(RisingFlag) OVER (PARTITION BY code ORDER BY day) NoRisingDays
FROM (
SELECT code, day,
CASE WHEN price>LAG(price) OVER (PARTITION BY code ORDER BY day)
THEN 0 ELSE 1 END RisingFlag
FROM stock ) )
GROUP BY NoRisingDays )
GROUP BY code
可以尝试读一下这个 SQL 在算什么。是不是很绕?其实按照分步解法,只需要 3 步就能搞定,根本不用这么绕来绕去。
而存储过程是用 SQL 实现的自然继承了这个缺点,我们经常能在项目中看到上千行、上百 KB 存储过程的情况,就是因为 SQL 对复杂计算支持不好的缘故。
SPL 不仅支持天然支持过程计算,数据处理可以分多步、按照自然思维一步一步实施,而且提供了丰富的计算类库和敏捷语法,基于 SPL 可以更容易实现复杂计算。
上一段代码看一下效果:
【计算目标】要找出销售额占到一半的前 n 个客户(大客户)的订单情况。
A |
|
1 |
=file(“/opt/ods/orders.csv”).import@tc() |
2 |
=A1.groups(customer;sum(amount):amount).sort(amount:-1) |
3 |
=A2.sum(amount)/2 |
4 |
=0 |
5 |
=A2.pselect((A4=A4+amount,A4>=A3)) |
6 |
=A2.(customer).to(,A5) |
7 |
=A1.select(A6.pos(A1.customer)) |
通过分步的方式,先找到符合条件的大客户,再查询这些客户的详细订单信息。这些计算都是在库外完成的,甚至可以使用文件数据源。从实现的过程来看,SPL 的过程计算比存储过程更加优秀,语法也更为简洁。
而前面提到的计算某只股票最长连续上涨天数,SPL 的实现是这样的:
A |
|
1 |
=db.query("select * from stock order by day") |
2 |
=A1.group@i(price<price[-1]).max(~.len())-1 |
按交易日排好序,将连涨的记录分到一组,然后求最大值 -1 就是最长连续上涨天数了,完全按照自然思维实现,不用绕来绕去。SQL 虽然比 Java 在某些场合方便了点,但仍然差很多,SPL 不仅支持过程计算,实现复杂计算也更简单,比 SQL 更有优势。
降低数据库负担并获得更高性能
不过,SPL 是一种库外计算引擎,需要将数据从数据库中取出来再计算。这样在涉及数据量较大时,可能会因为数据库 IO 性能低下导致低性能。
这一点,SPL 也有应对方法,可以实现数据外置。将数据库中大量历史冷数据外置到文件中,使用 SPL 读取文件直接计算,这样不仅可以降低数据库负担(数据库不再需要承担过多的数据存储和数据计算工作自然压力降低),基于文件还可以获得更高的 IO 效率。
将大历史数据外置后,借助 SPL 的多源混算能力,还很容易实现 T+0 查询。从数据库中读取当期热数据,从文件中读取历史冷数据,二者混合计算完成 T+0 全量实时数据查询。
此外,使用 SPL 还能获得更高的运算性能。
SPL 提供了众多高性能数据存储和高性能算法机制,SQL 中很难实现的高性能算法及存储方案用 SPL 却可以轻松实现,而软件提高性能关键就在于算法和存储。
例如,SPL 可以把 TopN 理解为聚合运算,这样可以将高复杂度的排序转换成低复杂度的聚合运算,而且很还能扩展应用范围。
A |
||
1 |
=file(“data.ctx”).create().cursor() |
|
2 |
=A1.groups(;top(10,amount)) |
金额在前 10 名的订单 |
3 |
=A1.groups(area;top(10,amount)) |
每个地区金额在前 10 名的订单 |
相比之下,SQL 描述 TopN 会涉及大排序,性能非常低下,只能寄希望于数据库的优化。但在稍复杂的情况(比如 A3 中伴随分组运算)数据库优化器就会失效。
总体看来,SPL 可以作为存储过程很好的替代和延伸。


英文版