


开源SPL将银行手机账户查询的预先关联变成实时关联
【摘要】
S 银行的手机银行活期明细查询后台是 Elastic Search,营业单位代码表要通过预先关联冗余到明细宽表中。当营业单位发生变更时,必须刷新几亿条数据量的大表,耗时好几个小时。点击了解开源 SPL 将银行手机账户查询的预先关联变成实时关联
现状
S银行的手机银行系统要对外提供活期明细查询功能,数据量大、访问量大而且要求秒级响应。银行先采用国内某知名商用HADOOP平台作为查询后台,支持多表实时关联查询,但是并发性能太差,无法满足要求。不得已改用Elastic Search(简称ES)集群作为查询后台,共部署了6台服务器。对三年的活期明细3亿条查询,近百并发量时,响应时间做到1秒内。使用ES后,性能可以达到要求了,但是存在三个较严重的问题:
1、 ES不支持多表关联,营业单位代码表要预先关联好,将营业单位名称冗余到活期明细宽表中。当营业单位发生合并、撤销、新增或者变更时,要把宽表中3亿条数据全部刷新,耗时几个小时,这时候不能提供及时准确的查询。而营业单位发生变更的情况并不罕见,几乎每隔几个月就会发生。
2、 ES集群重启很慢,每次程序升级都需要重启,在这期间只能暂停对外查询服务。
3、 ES集群节点较多,管理维护工作量大。
图1 手机账户查询访问量很大
在保证性能的前提下,有没有什么办法,能做到活期明细和营业单位实时关联,避免代码刷新问题及其带来的ES重启问题呢?
解决办法
第一步,分析业务数据和计算特征。
账户查询后台服务器内存是256G,装下3年的3亿条明细数据已经比较吃力,明细数据还会随着时间不断增长,必须基于单台服务器内存装不下全部明细数据的前提来设计方案。
在手机银行账户查询时,每个客户只能查询他本人的活期明细。明细数据总量很大,但是每个客户数据量并不大,只有几条到几千条。
营业单位代码表数据量也不大,只有几千条数据。
第二步,确定优化方案。
从数据量上看,如果采用全内存方案,就必须使用多台服务器集群,但这会带来较高的管理和采购成本。其实,即使有并发查询,同时涉及的数据量相对于全量数据来讲仍然是很小的一部分,全内存的利用率很低,投入不划算。我们还是希望能够基于外存机制来设计优化方案,这样可以较低成本地应对较长期的数据增长。
再从数据和计算特征来看,如果将活期明细数据按照账号有序存放,再建立账号索引,就可以在查询时快速找到指定账号的全部数据。如下图所示:
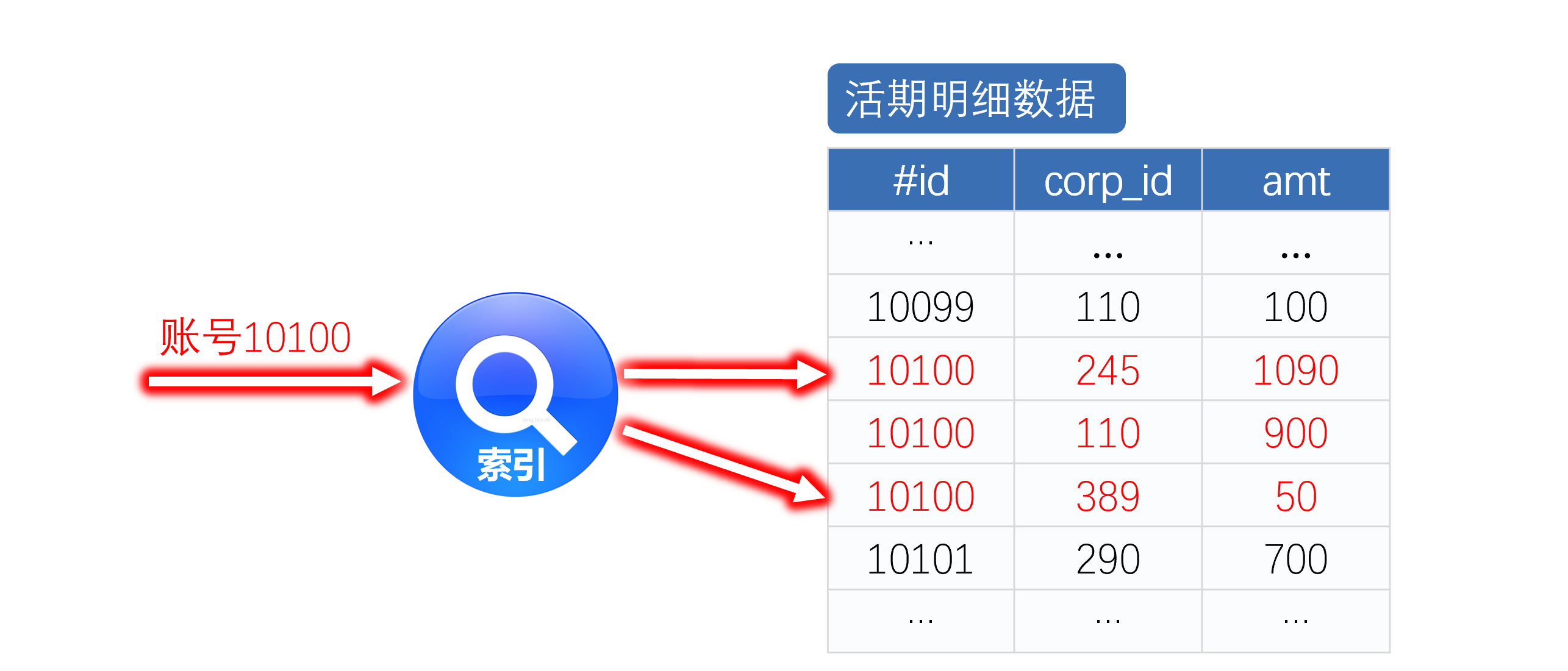
图2物理有序存储的索引查询
从图2可以看到,查询活期明细时,在磁盘上连续读取,可以显著减少磁盘 IO,有效提速。这样,即使是外存机制,每次查询量也非常少,也可以满足性能要求。
营业单位代码表独立存放,预先加载到内存中,不需要冗余到活期明细表中。
快速找到当前账户数据之后,全部读入内存,和预先装入内存中的营业单位代码表关联就非常快了。这种全内存的关联,要采用指针引用方式做HASH关联,性能最佳。
这样,营业代码表和活期明细表是实时关联的,就能避免预关联带来的代码刷新问题。
第三步,确定技术选型。ES不支持多表关联,无法解决营业单位代码刷新问题,被排除在选型范围之外。
关系数据库(包括HADOOP体系的关系数据库)普遍是无序集合理论基础,不能保证数据在物理上的有序存储,加索引只是逻辑上的有序,无法减少实质上的硬盘碎块访问。如下图所示:
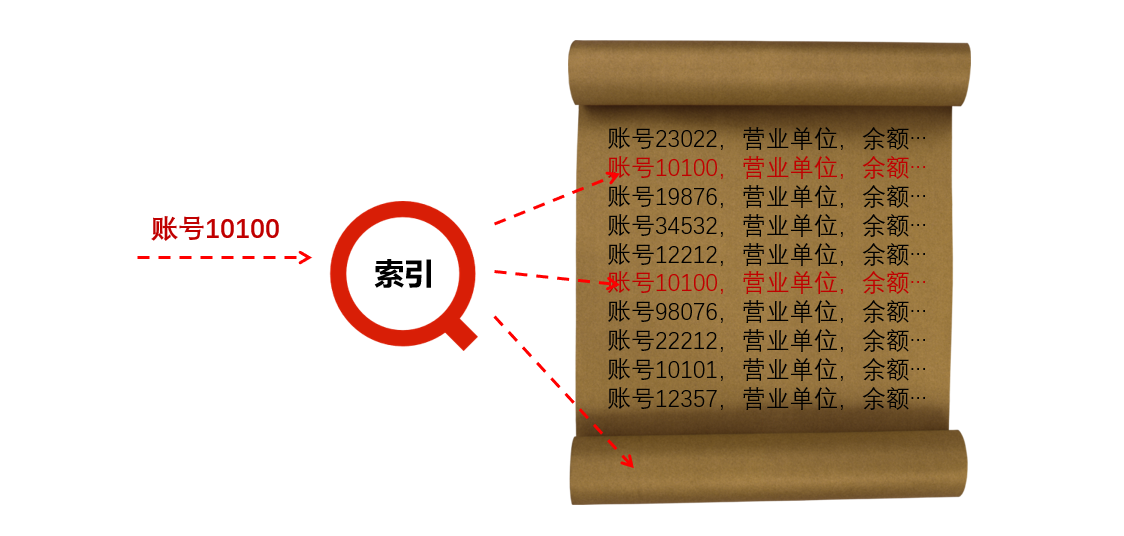
图3数据库索引存在的问题
从图3可以看到,在关系数据库的表中,同一账号在各处都可能有。索引查找不得不在硬盘多处读取数据。每个查询都慢些,大并发总体性能就会很差。传统关系数据库难以确定实现上述优化方案,也被排除了。
使用Java或C++等高级语言可以实现上述算法,但这些运算在Java或C++中非常难写,仅一个HASH关联就要数百行代码,而且还不通用。过大的编码量会导致实现周期过长,还容易出现代码错误隐患,也很难调试和维护。
开源的集算器SPL语言提供上述所有的算法支持,包括高性能文件、物理有序存储、文件索引、全内存指针引用方式关联等机制,能够让我们用较少的代码量快速实现这种个性化的计算。
第四步,实施优化方案。
首先要编写用于数据初始化和转换的集算器SPL代码,将活期明细数据按照账号有序存储在高性能文件中,并生成基于账号的索引文件。
再编写用于查询的SPL代码,输入参数是账号。先用索引文件查找输入账号的全部数据装入内存,然后和预先装入内存的营业单位代码表关联,关联采用指针引用方式。最后将结果返回给前端应用。
ES中的数据,原先是由ETL工具每天从数据仓库抽取出来的。优化改造时,由ETL每天抽取当日增量数据,有序归并到集算器高性能文件中。前端应用原先访问ES是调用JDBC接口实现。优化之后,改为调用集算器JDBC接口,用类似调用数据库存储过程的方式,调用SPL代码。
实际效果
经过几天时间的SPL编码、测试,优化的效果非常明显。优化之后,仍然对三年的活期明细3亿条查询,相同并发量时,仅用一台服务器,响应时间0.5秒。集算器服务器硬件配置和ES的服务器完全相同,而并发访问的能力提高了6倍。
活期明细表和营业单位代码表是分别存放、实时关联计算的。当营业单位发生变更时,只要改变营业单位代码表即可,不需要刷新整个活期明细大表,代码表变更维护时间不到1秒,彻底解决了代码刷新问题。
集算器重启仅需要1、2秒时间,也解决了ES重启非常慢的问题。
高性能查询采用集算器实现,ES用于全文检索和搜索,各取所长。
从开发难度来看,SPL做了大量封装,提供了丰富的函数,内置了上述优化方案需要的基本算法。上述算法对应的SPL代码也只有几行:
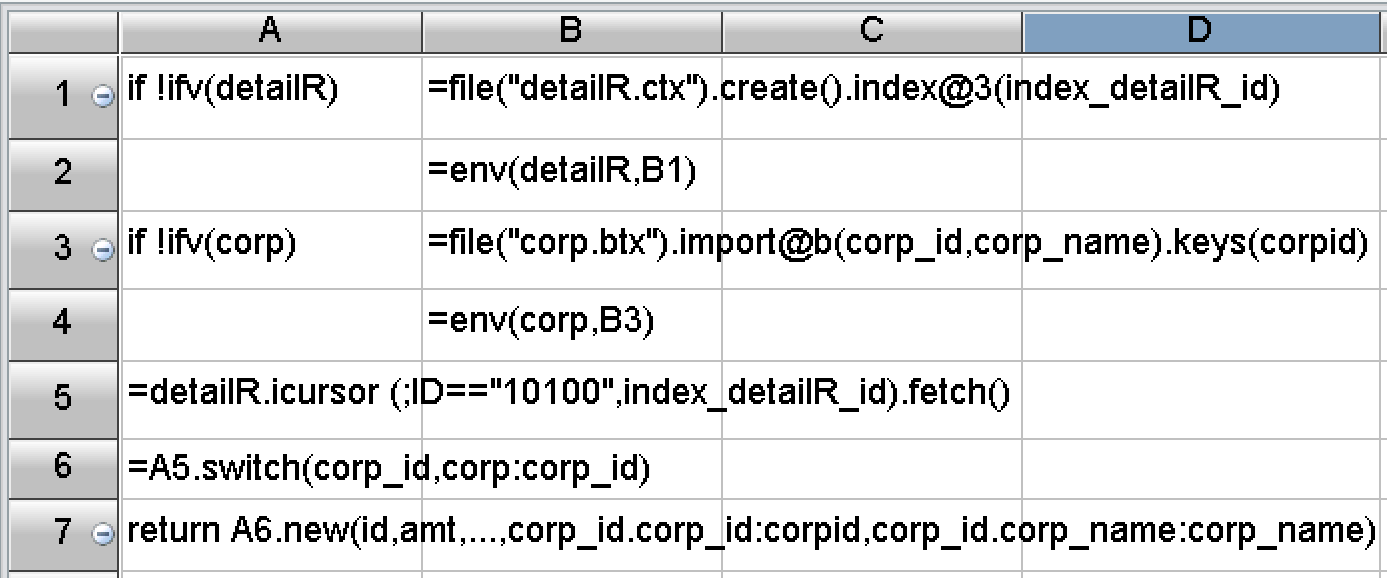
图4账号查询的SPL代码
后记
解决性能优化难题,最重要的是设计出高性能的计算方案,有效降低计算复杂度,最终把速度提上去。因此,一方面要充分理解计算和数据的特征,另一方面也要熟知常见的高性能算法,才能因地制宜地设计出合理的优化方案。本次工作中用到的基本高性能算法,都可以从下面这门课程中找到:点击这里学习性能优化课程,有兴趣的同学可以参考。
很遗憾的是,当前业界主流大数据体系仍以关系数据库为基础,无论是传统的MPP还是HADOOP体系以及新的一些技术,都在努力将编程接口向SQL靠拢。兼容SQL确实能让用户更容易上手,但受制于理论限制的SQL却无法实现大多数高性能算法,眼睁睁地看着硬件资源被浪费,还没有办法改进。SQL不应是大数据计算的未来。
有了优化方案后,还要用好的程序语言来高效地实现这个算法。虽然常见的高级语言能够实现大多数优化算法,但代码过于冗长,开发效率过低,会严重影响程序的可维护性。开源的集算器SPL是个很好的选择,它有足够的算法底层支持,代码能做到很简洁,还提供了友好的可视化调试机制,能有效提高开发效率,以及降低维护成本。
正在为 SQL 性能优化头疼的同学们,可以和我们一起探讨:http://www.raqsoft.com.cn/wx/Query-run-batch-ad.html
更多相关案例:

英文版