


开源 SPL 优化保险公司跑批从 2 小时到 17 分钟
【摘要】
新增保单关联历史保单的跑批任务非常耗时,点击了解开源 SPL 优化保险公司跑批从 2 小时到 17 分钟
问题描述
P保险公司的车险业务中,需要用往年历史保单来关联新的保单,在跑批中称为历史保单关联任务。在提醒老客户续保时需要计算指定时间段的往年保单,例如省级公司需要定期计算特定月份内可续保保单对应的历史保单。目前这类批量数据处理任务是由存储过程实现的,性能差、运行时间长,运行时间随着新增保单的天数成正比的增长。计算十天的新增保单关联历史保单,运行时间47分钟;三十天则需要112分钟,接近2小时;如果时间跨度更大,运行时间就会长的无法忍受,基本就变成不可能完成的任务了。
分析解决
第一步,理解计算任务特征。跑批的存储过程很长,有2000多行。用到的数据表包括:保单表和保单-车辆明细表。对于较大的省份,保单表和保单-车辆明细表都有几千万数据存量,每天新增保单的增量数据有一到两万条。两个表结构大体如下(因脱敏的需要,所有实际字段名均用xxxx替代,仅保留注释):
保单表
xxxx char(xx) not null ,--保单编码(主键)
xxxx char(xx),--保单号
xxxx datetime year to second,--开始日期
xxxx datetime year to second--结束日期
保单-车辆明细表
xxxx char(22) not null , --保单编码(主键)
xxxx decimal(x,x) not null ,--明细编码(主键)
xxxx varchar(xx),--牌照编码
xxxx char(x),--牌照种类
xxxx varchar(xx),--vin编码
xxxx varchar(xx)--车架编码
新旧保单的对照表:
xxxx char(xx) not null , --保单编码
xxxx char(xx) --上年保单编码
往年保单的计算输入参数是起始日期(istart)和结束日期(iend),计算目标是新旧保单的对照表,找不到旧保单的将被舍弃。
计算过程主体如下:
1、 从保单表中,找出开始日期在指定时间段(istart和iend之间)内的新增保单。
2、 用新增保单关联上一年的历史保单。关联的条件是:vin编码相同;或者车架编码相同;或者牌照种类、牌照编码同时相同。还要去掉旧的保险单号为null或者空字符串的数据,去掉新旧保险单相同的数据。
3、 在所有旧保险单中找到结束日期和新保单时间差在90天之内的,就是上年保单。
第二步,分析性能瓶颈。经过多次测试发现,原存储过程性能优化的关键在于四个关联计算。首先是新增保单表和保单-车辆明细表通过保险单编码关联来获得车辆信息,之后再与保单-车辆明细表分别通过vin码、车架号、车牌号(车牌种类)关联三次,来获取历史保单。十天的新增保单有10万多条,这四次关联的时间尚可忍受。而一个月的新增保单有四十多万条,这四次关联的时间就会达到1到2个小时。
第三步,设计优化方案。性能优化的重点是解决“四次关联(JOIN)运算”这个瓶颈。在关系数据库中,JOIN一般使用HASH算法,复杂度是SUM(Ni*Mi)。如果两个历史保单大表(保单和保单明细)的数据事先按关联字段(保单编码)排过序,就可以使用更低复杂度(M+N)的有序归并算法来提高JOIN的性能。而且,新增保单数量较小,可以全读入内存反复使用。数据量巨大的历史保单表进行有序归并后,可以在同一次遍历中把与新增保单表的其它三次关联全都完成,实现遍历复用,减少遍历次数,有效提速。这样做的好处在于,无论是十天还是一个月的新增保单,计算时间都不会明显延长。
第四步,设计实现方案。关系数据库建立在无序集合理论的基础上,没有办法把有序的结果事先保存起来。SQL也写不出遍历复用的语句。所以,上面的优化方案没有办法在数据库里实现,需要把数据外置到文件来自行处理。历史保单关联是典型的跑批任务,数据每天从生产数据库导入到跑批数据库。数据本来也要移动,我们可以在过程中同时将数据导出到文件,以实现上述的高性能算法。而且文件系统的IO性能更好,导出到文件会比导出到数据库更快,数据外置在工程上也是可行的。
第五步,数据导出。从数据库中导出保单表和保单车辆明细表,按照保单编码排序之后,存放到高性能文件中。这里的排序很重要,是后续实现有序归并的前提条件。因为数据库JDBC性能较差,所以第一次导出全部历史数据的时候速度会比较慢。但是以后每天导出新增数据,增量更新高性能存储文件就很快了。
第六步,编写新的算法代码,实现性能优化。一天的新增保单1到2万条,三十天的新增保单30到60万条,这个量级的数据可以直接存放在内存中,再对历史保单完成三种方式的关联计算,得到新旧保单对照表。
用保单编码关联两个游标。如前所述,两个文件都已经按照保单编码排序了,所以这里的关联是采用有序归并的方式,两个表都只需要遍历一次,如下图:
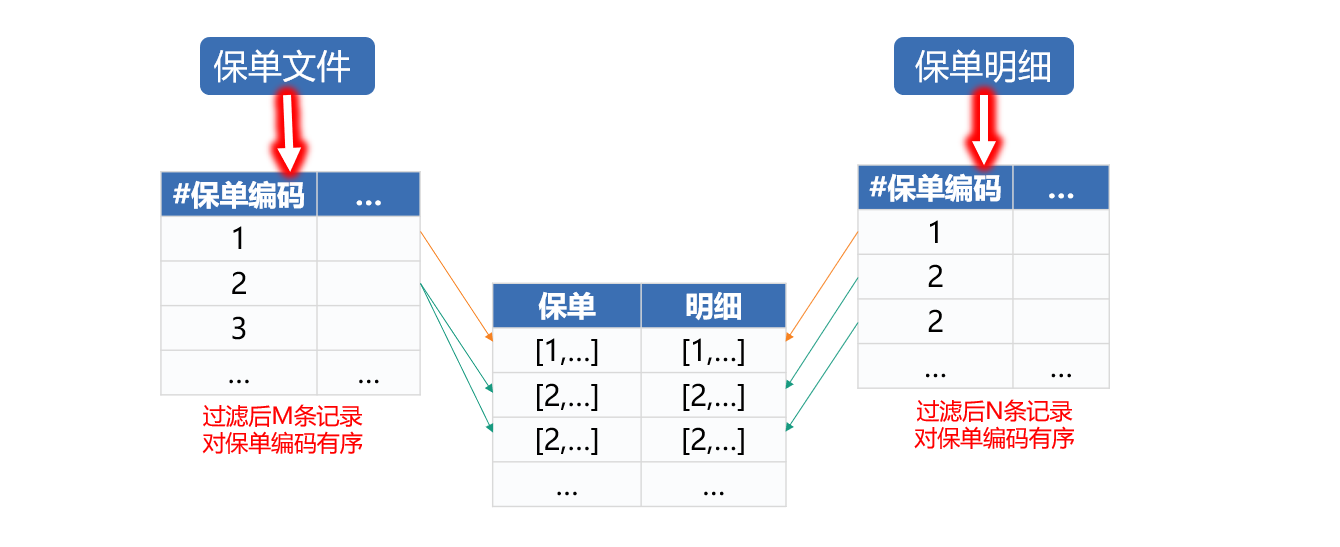
两文件关联之后,循环遍历,每次取出一部分数据和内存中的新增保单先后通过vin码、车架编号、车牌号(车牌种类)三种方式分别关联,结果合并之后生成新的数据文件。如下图:
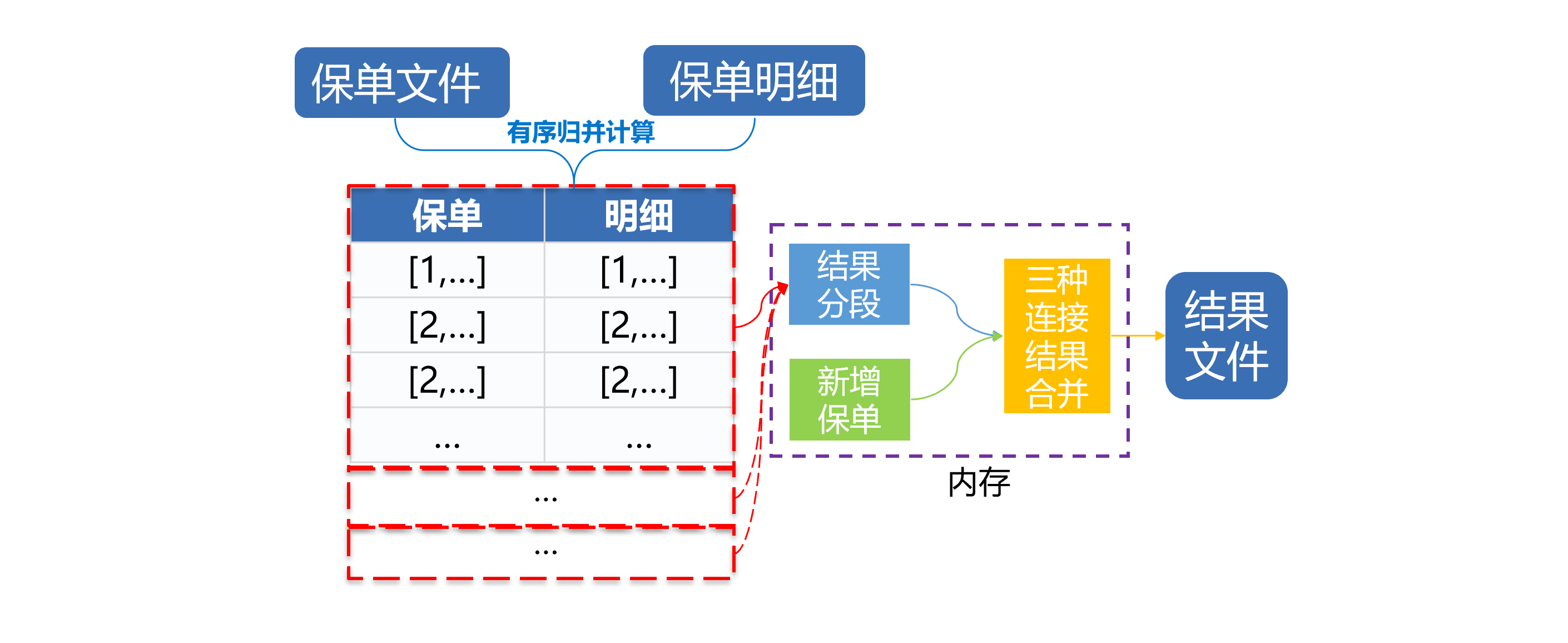
图中可以看到,一次遍历实现了四个关联计算,不必遍历四次、也无需生成多个中间结果。减少了遍历次数,减少了读写硬盘的时间。性能提升明显。
实际效果
根据计算特征拟定了优化方案后,需要选择合适的工具来实现计算性能优化。SQL已经在分析过程中就被否决了。使用Java或C++等高级语言可以实现这个算法,但编码量过大,实现周期过长,容易出现代码错误隐患,也很难调试和维护。开源集算器的SPL语言提供上述所有的算法支持,包括高性能文件、文件游标、有序归并分段取出、内存关联、遍历复用等机制,能够让我们用较少的代码量快速实现这种个性化的计算。
经过几天时间的编程、调试和测试,我们完成了性能优化的验证,性能提升非常明显。优化前,用数据库存储过程跑批,计算10天新增保单关联历史保单,需要47分钟,优化之后需要13分钟;优化前计算30天新增保单,需要2个小时,优化后只需要17分钟,速度提高了近7倍。而且,可以看到新算法执行的时间增长并不是很大,并没有像存储过程那样随着新增保单的天数成正比的增长。
在编程难度方面,SPL做了大量封装,提供了丰富的函数,内置了上述优化方案需要的基本算法和存储机制。实际编写的代码很短,开发效率很高。上述跑批的四次关联计算代码如下图:
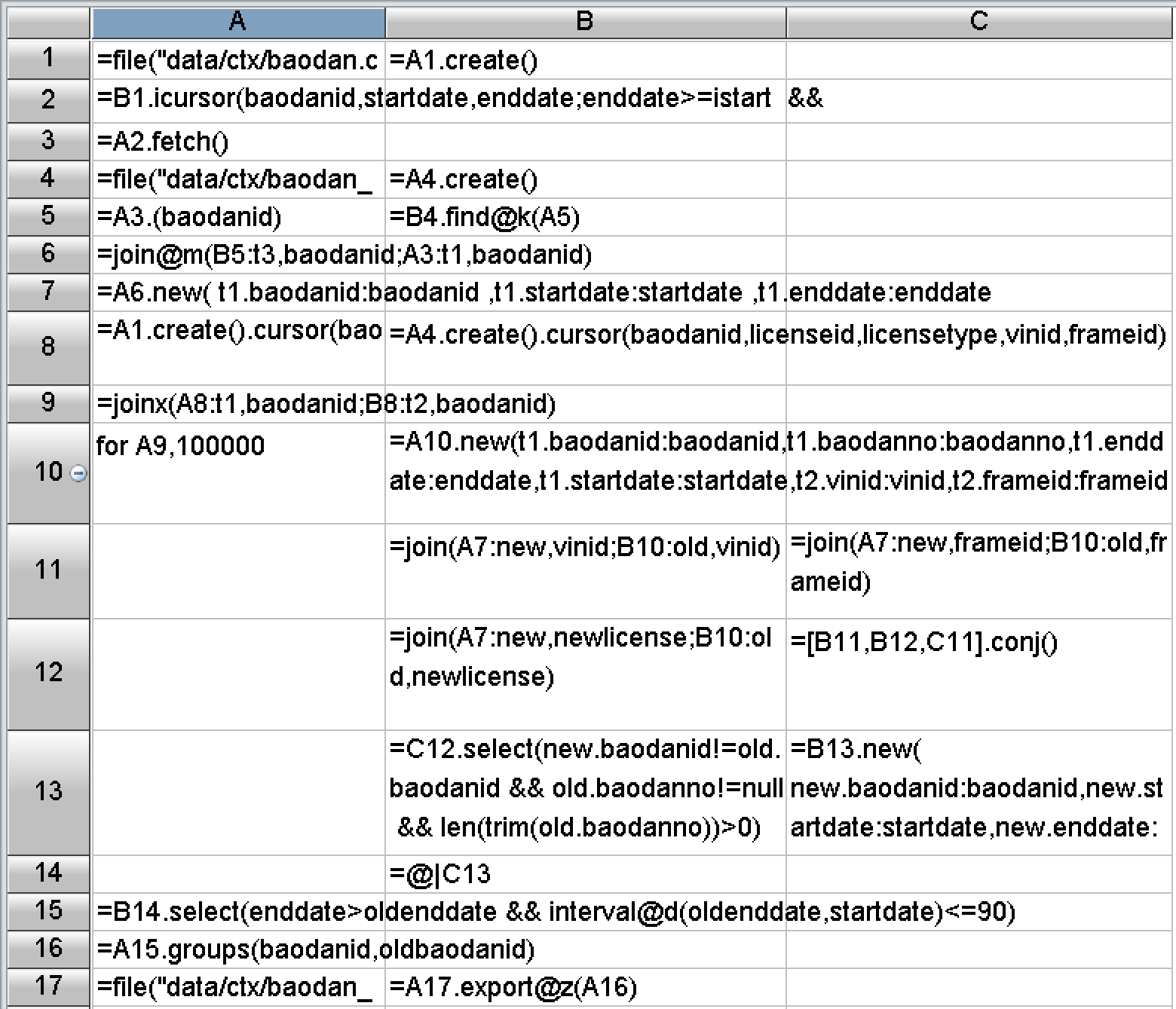
从代码总量来看,原来存储过程有2000行代码,去掉注释后还有1800多行,而SPL的全部代码只有不到500格,不到原来的1/3。
后记
解决性能优化难题,最重要的是设计出高性能的计算方案,有效降低计算复杂度,最终把速度提上去。因此,一方面要充分理解计算和数据的特征,另一方面也要熟知常见的高性能算法,才能因地制宜地设计出合理的优化方案。本次工作中用到的基本高性能算法,都可以从下面这门课程中找到:点击这里学习性能优化课程,有兴趣的同学可以参考。
很遗憾的是,当前业界主流大数据体系仍以关系数据库为基础,无论是传统的MPP还是HADOOP体系以及新的一些技术,都在努力将编程接口向SQL靠拢。兼容SQL确实能让用户更容易上手,但受制于理论限制的SQL却无法实现大多数高性能算法,眼睁睁地看着硬件资源被浪费,还没有办法改进。SQL不应是大数据计算的未来。
有了优化方案后,还要用好的程序语言来高效地实现这个算法。虽然常见的高级语言能够实现大多数优化算法,但代码过于冗长,开发效率过低,会严重影响程序的可维护性。SPL是个很好的选择,它有足够的算法底层支持,代码能做到很简洁,还提供了友好的可视化调试机制,能有效提高开发效率,以及降低维护成本。
更多相关案例:


英文版
可以把 spl 源程序都贴出来吗?想学习一下
抱歉,这种实际案例的代码涉及甲方关键信息,发布出来时都做了脱敏处理,原始代码更不能发布。
学习性能优化技术还有其它很多资料。