


开源SPL提升银行自助分析从5并发到100并发
【摘要】
B 银行自助分析系统只能支持 5 并发,造成大量业务人员长时间等待。如何破解?点击了解开源 SPL 提升银行自助分析从 5 并发到 100 并发
现状分析
B银行的电子银行自助分析系统,需要查询指定日期的客户交易明细。业务人员在界面上随意设置过滤条件,在每天几千万条数据中筛选查询。自助分析的结果可以用于找到目标客户,制定营销计划,评估活动效果等等。但是,现有的系统却只能支持5个并发访问,远远不能满足大量业务人员的访问需要。
究其原因,是因为自助分析系统后台无力支撑更大的并发数量。自助分析系统直接连接B银行中央数据仓库作为后台。而数据仓库是全行共有,并不专门为自助分析服务,还承担了包括跑批计算在内的其它应用任务。集群节点已达48个,几乎是该款数据仓库的上限了,无法再扩容。所以,数据仓库只能给自助分析系统开5个连接,想要再多的连接是不可能的。而且就算是这5个连接,也很难保证流畅地使用,一旦碰到数据仓库在执行其它重要任务,自助分析操作就会显得非常卡顿。
系统结构如下图:

既然数据仓库无法扩容,是否可以考虑换成其他数仓产品呢?这不可行。因为数据仓库涉及到很多部门的很多应用,换其他数据仓库的成本太高,还有稳定性隐患。而且真换了也不一定能更快,还需要大量的测试和优化。
一个容易想到的办法,是数据仓库之前再放一个前置数据库,用于承担自助分析的压力。但是,常规关系数据库却无法胜任。一方面,自助分析需要查询全量历史明细数据,前置数据库如果和数据仓库保持同样规模的数据,就需要建设同样规模的集群,行方无法容忍这个重复建设的成本。另一方面,常规的行存数据库也无法达到多并发下千万数据量秒级响应的速度。
解决办法
首先,分析业务和需求特征。自助分析的计算和数据是有规律可循的。自助分析系统提交的SQL比较简单,只包含select、from、where子句,没有复杂的窗口函数等。From子句针对的是一个宽表,没有表间关联Join。宽表字段有几十个,查询需要的字段一般都只有几个。Where条件中,日期是必选条件,即只能在一天范围内查询。其他过滤条件是客户自主选择和组合的。
进一步分析,我们发现90%以上查询请求都集中在十几个日期:查询的前一日和连续13个月的月末最后一天。这个范围之外的数据,查询量不足10%。因此,我们可以将这个范围内的数据定义为热数据,其他数据定义为冷数据。
第二,设计优化方案并确定技术要求。根据实际情况和业务需求,我们还是决定采用前置计算层的方案,在前置层保存热数据并负责相应的查询,承担90%以上的计算量;而对冷数据的查询仍然放在中央数据仓库上,但计算量下降到原来的不足10%。这样,前置计算层只需要保持较少量的热数据,不会出现重复建设的情形。
这个方案的关键在于前置计算层的实施技术,它必须有足够的高性能以应对90%的查询量,同时还需要有路由能力。因为自助分析的前端是套装软件,只会通过JDBC接口对一个后台数据库发出SQL查询,因而需要这个前置计算层能根据SQL中的日期条件决定由自己做查询还是将查询分发给中央数据仓库。优化方案的结构如下图所示:
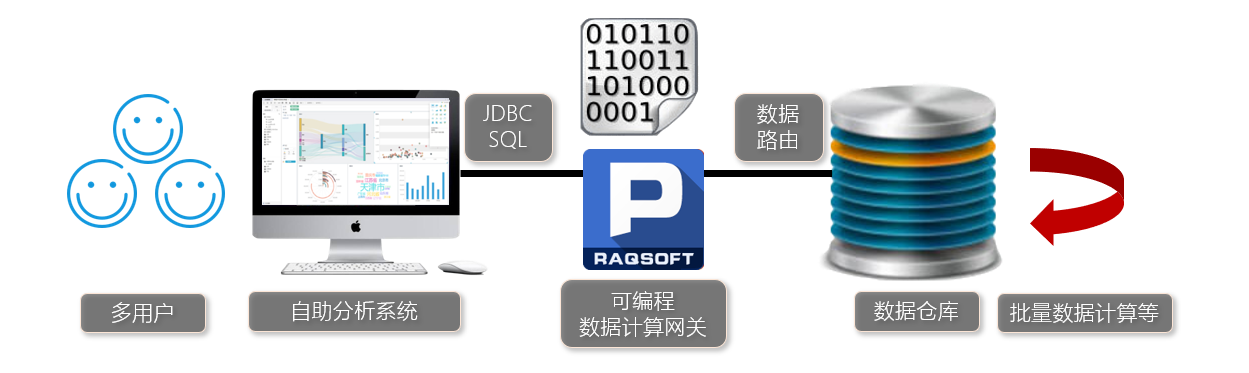
从图中可以看出,自助分析系统提交查询SQL后,前端计算层要判断其中的日期条件是否针对热数据,如果是,则直接查询数据,返回结果。如果不是,则将SQL转发给数据仓库,结果返回给自助分析系统。这相当于一个网关的作用,能实现数据计算的路径选择,我们称之为数据计算路由。
另外,B银行一般的服务器内存都是128G,十多天、每天千万数据量的数据,也没办法全内存计算。这个前置计算层需要采用高性能列存方案,才能提供千万数据量秒级并发的查询速度。
同时,前置计算层还要对自助分析系统提供标准JDBC接口,至少支持前面说的简单SQL语句,也就是需要有SQL的解析和执行能力。
第三,确定技术选型。有了优化方案,就要选择适用的工具来实现方案。经过最初的分析,我们已经知道无法使用常规关系数据库来搭建这个前置计算层。
服务器内存不大,无法装入全部数据,无法使用全内存计算技术(包括各种内存数据库)。采用现成的列存数据库大体能达到性能要求,但一方面造价太高,另一方面列存数据库仍然是关系数据库体系,无法实现路由功能,因此也不可行。使用Java或C++等高级语言可以实现上述算法,但编码量过大,实现周期过长,容易出现代码错误隐患,也很难调试和维护。
开源的集算器SPL语言提供上述所有的算法支持,包括高性能列存文件、JDBC和SQL执行、并提供SQL语句解析和转换的基本函数以实现数据计算路由,能够让我们用较少的代码量快速实现这种个性化的计算。
集算器SPL语言提供强大的脚本功能,可以用来定义和调整数据计算路由规则。这样,还能记录路由日志,用来分析热数据的时间和空间分布,不断优化路由规则。
第四,实现前置计算层及网关方案。前置计算层初始化时,要将十多天的热数据从数据仓库中导出,缓存到本地高性能列存文件中。按照优化前的方式,每天用ETL工具将生产数据库推送来的,前一日的最新数据导入到中央数据仓库。优化之后,同时将推送来的数据在集算器中保存成文件。数据本来就是推送过来的,因此并没有增加生产库导出的负担。
自助分析系统中,数据仓库的JDBC驱动,要换成集算器的JDBC驱动,数据连接参数也要相应调整。其他不需要改动,最大程度兼容自助分析系统。
集算器接收到自助分析系统提交的查询请求后,先进行SQL解析,拆分出各个SQL子句,根据where子句中的日期条件,决定计算路径。如果是热数据,则访问缓存好的本地高性能列存文件。如果是冷数据,要将标准SQL转换为数据仓库的SQL语句,转发给数据仓库执行,结果返回给自助分析系统。同时,记录数据路由的日志。
为了并行访问时分担负载,集算器采用两个节点集群部署。这样做,还可以避免单点故障,实现高可用性。最终用集算器搭建的系统如下图:
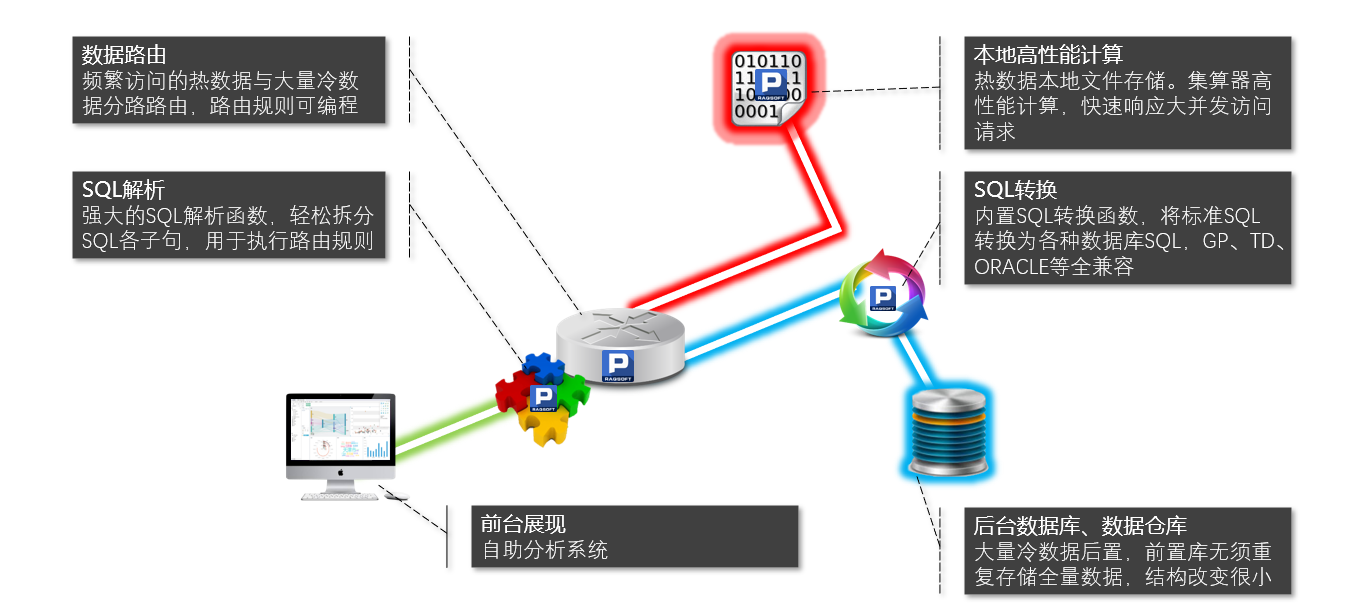
实际效果
系统优化之后已经在线正式运行了,实际效果也非常显著。
从单查询请求测试来看,单日明细数据三千万行,集算器和专业数据仓库执行同样的条件查询。集算器仅用2秒完成,数据仓库执行了5秒。数据仓库环境是5个节点集群,每个节点是2*6核CPU,96G内存的实体机;而集算器所在的服务器仅是1*2核CPU,16G内存的虚拟机。
从并发请求来看,每台前置服务器支持50并发,全部在5秒之内返回完毕。两台服务器集群支持几百用户访问毫无压力。也就是仅仅增加了两个低端PC服务器就把并发量提高了10倍以上,而且全程操作流畅。
从开发难度来看,SPL做了大量封装,提供了丰富的函数,内置了上述优化方案需要的基本算法和存储机制。上面所说的数据计算路由对应的SPL代码如下图:
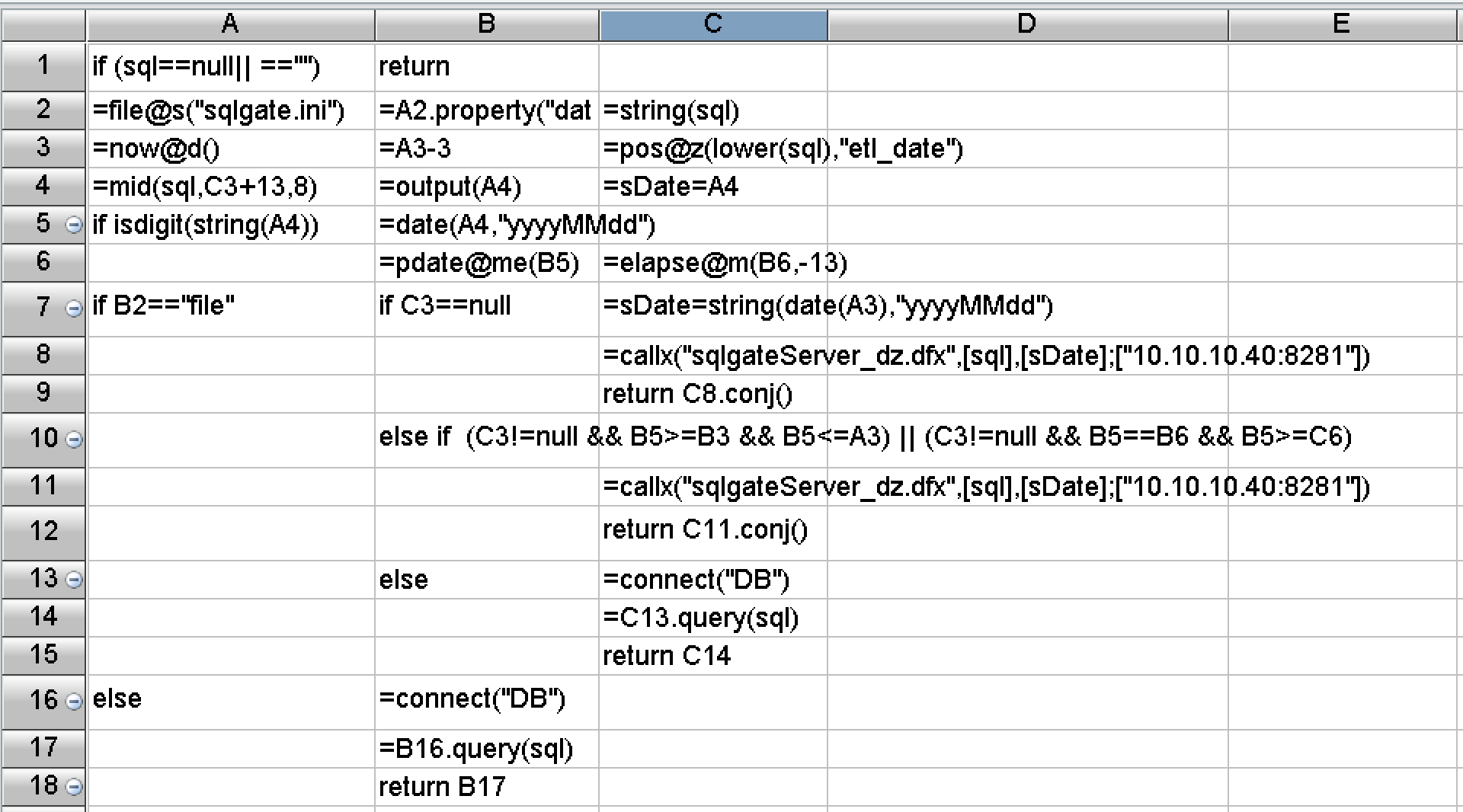
后记
解决性能优化难题,最重要的是设计出高性能的计算方案,有效降低计算复杂度,最终把速度提上去。因此,一方面要充分理解计算和数据的特征,另一方面也要熟知常见的高性能算法,才能因地制宜地设计出合理的优化方案。本次工作中用到的基本高性能算法,都可以从下面这门课程中找到:点击这里学习性能优化课程,有兴趣的同学可以参考。
很遗憾的是,当前业界主流大数据体系仍以关系数据库为基础,无论是传统的MPP还是HADOOP体系以及新的一些技术,都在努力将编程接口向SQL靠拢。兼容SQL确实能让用户更容易上手,但受制于理论限制的SQL却无法实现大多数高性能算法,眼睁睁地看着硬件资源被浪费,还没有办法改进。SQL不应是大数据计算的未来。
有了优化方案后,还要用好的程序语言来高效地实现这个算法。虽然常见的高级语言能够实现大多数优化算法,但代码过于冗长,开发效率过低,会严重影响程序的可维护性。开源SPL是个很好的选择,它有足够的算法底层支持,代码能做到很简洁,还提供了友好的可视化调试机制,能有效提高开发效率,以及降低维护成本。
正在为 SQL 性能优化头疼的同学们,可以和我们一起探讨:http://www.raqsoft.com.cn/wx/Query-run-batch-ad.html
更多相关案例:


英文版