


开源SPL提速银行用户画像客群交集计算200+倍
【摘要】
X 银行把上亿客户划分为几千个客群,要计算任意几个客群的交集,还要按照维度过滤,还要秒级响应?点击了解开源 SPL 提速银行用户画像客群交集计算 200+ 倍
问题描述
X银行用户画像应用中,需要完成客群交集计算。客群数量多达数千个,每个客群包含的客户数量不等,从几十万到上亿都有。要计算出任意N(一般是2-10)个客群共同的客户。例如:滴滴出行客群有几百万客户,手机银行客群有几千万客户,需要求出滴滴出行和手机银行共同的客户数量。
对客群交集计算的结果,还要进行维度筛选。比如:滴滴出行和手机银行共同的客户,要对性别、年龄段和地域维度进行筛选,最终计算出满足各个维度条件的客户数量。
为了从时间维度做分析,每次要计算一年的结果,因此要保存十二个月的历史数据,每个月一套。针对十二个月的明细数据进行客户交集运算称为一个单任务。
X银行基于Hadoop体系某知名OLAP Server产品来实现客群交集计算,发现性能很差。动用了100个CPU(核)的虚拟机集群,完成一个单任务平均也要2分钟左右。而期望的性能指标是要在10秒内并发完成10-20个单任务,差距过于巨大。
采用该OLAP Server产品推荐的预计算方式可以满足性能要求。即预先计算好客群交集,把结果保存下来,再在结果基础上计算维度筛选。但是,几千个客群,仅仅考虑任意两个客群交集的组合就会上千万种,这勉强还可以存储下来,更多个客群交集想事先保存下来是个不可能完成的任务。
解决过程
第一步,深入理解数据和计算特征,分析性能瓶颈。
客户的每个维度的取值都是唯一的,每个客户一条记录即可存储,一亿个客户是一亿条记录。
维度没有层次关系,维度的属性一般是几个到几十个。比如:性别的属性是两个,年龄段的属性是十几个。参与过滤的维度总数是十到二十个。
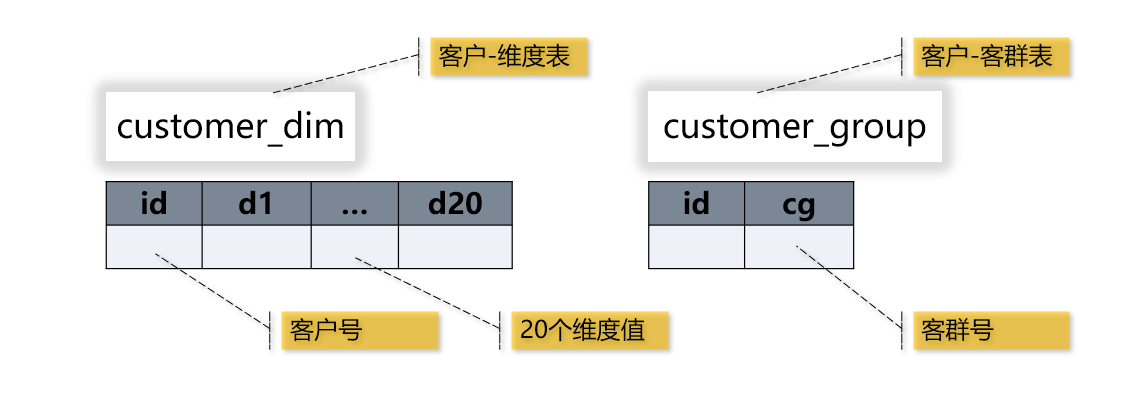
一个客户平均属于10个客群,如果用数据库表来存储的话,客户-客群表就有十亿多条记录。表结构如下图:
客群交叉和维度过滤的SQL语句,经过简化后如下:
select count(*) from (
select count(g.cg) from customer_group g
left join customer_dim d on g.id=d.id
where g.cg in ('18','25')
and d.d2 in ('2','4')
and d.d4 in ('8','10','11')
group by g.id
having count(g.cg)=2
)
这个SQL中有个JOIN可能拖累计算性能,但如果把两个大表行JOIN成一个宽表,那么相同的维度值会出现十倍以上的冗余,查询速度还会更慢。如果将多个客群号用逗号分隔字符串存入一个字段cg中,虽然可以避免维度值冗余,但是要做字符串拆分的计算,数据量大时,还是很慢。例如:cg为“18,25,157”表示这个客户属于三个客群,算交集时要用字符子串比较,计算量仍然很大。经过一些实验后发现,在当前的技术环境下,继续使用这个表结构和该SQL语句的性能还是最好的。这个JOIN虽然涉及大表,但都有过滤条件,过滤之后会变成小表内存JOIN,性能损失不算很严重,更重要的运算瓶颈就在过滤条件中的IN条件上,IN是一种计算效率很差的集合运算,且和IN的枚举值个数有关,枚举值越多,性能就越差。
第二步,确定优化方案。
每个月都保存完整数据,X银行标配的虚拟机是16G内存,一个月的数据都存不下,无法实施全内存计算。从外存读取数据并计算,首先要考虑减少数据存储量和访问量。如果继续使用两个表的方式,那么需要分别读取并做关联,会加大访问量和计算量。因此我们考虑将两个表合并成一个,每个客户一行数据,同时存储维度属性和所属客群。这样,全部数据量就等于客户数量。特别地,维度属性要用整数存储,存储量和计算量都比字符串小。
客群有几千个,用整数保存的话数据量太大,而客群是个标签属性,只有是否两种状态,只需要一个bit(位)就能保存。一个小整型的二进制表示有16位,每一位都可以表示一个客群。为了计算方便,我们把一个小整型的15个bit用于保存客群标签,600个小整数就可以保存9000个客群标签。
在数据表中用600个字段c1到c600,每个字段表示15个客群的位置。0表示不属于这个客群,1表示属于这个客群。做两个客群的交叉时,取其中的最多2列即可;做n个客群交叉,取其中最多n列即可。我们采用列式存储,在n小于10的时候,能大量减少读取数量。
维度字段d1到d20,不再保存相应维度值,而是保存维度值在维度列表中的顺序号。例如:d2为年龄维度,客户001的年龄段是20-30岁,在年龄维度列表中对应的枚举值序号是3,那么就将这个客户的d1字段设置为3。
做维度过滤的时候,输入的年龄段条件计算成布尔序列,序列的长度是年龄段维度属性的个数。如果条件是20到30岁,就要将序列第3个成员设置为true,其他设置为false。
对新存储文件条件过滤的时候,遍历到客户001这一行,取得d1的值是3,找布尔序列第3个元素是true,所以客户001符合过滤条件。
这种算法我们称为布尔维序列,每个客户的维度取值,只用一行数据中的20个整数即可存储。布尔维序列的好处是在查询时不用判断IN。如上所述,IN的性能很差并和枚举值数量有关,而布尔维序列判断是常数时间。
按照新的思路,算法的主体是对大列存数据表做按位计算和布尔维序列的过滤遍历。AND关系的过滤条件有很多,涉及多个字段。可以考虑遍历时,排在前面的条件对应字段先读取计算。如果满足条件,再读取后序条件对应字段;如果不满足,就不再读取后面的字段了。这种算法称为游标前过滤,可以有效减少数据的读取量。
第三步,选择技术路线。
只有个别商用数据库的SQL能支持位运算,但又和整个技术体系不相配,强行采用会导致非常繁琐的架构。在当前平台的SQL增加UDF实现位运算,其代码复杂度很高。继续基于平台的SQL体系完成这次优化的成本过高。
使用Java或C++等高级语言当然可以实现上述算法,但和使用UDF类似,代码依然非常复杂。上述的计算方法都要用几百上千行代码实现。过大的编码量会导致实现周期过长,还容易出现代码错误隐患,也很难调试和维护。
例如,Java从硬盘读取数据需要对象化。而Java生成对象很慢,如果不采用上面提到的游标前过滤,就要把很多列都读入内存再判断,会生成很多没有用的对象,对性能影响较大。如果用Java从无到有的编写代码实现游标前过滤算法,是非常费时费力的。
开源的集算器SPL语言提供上述所有的算法支持,包括高性能压缩列存、布尔维、按位计算、小整数对象、游标前过滤等机制,能够让我们用较少的代码快速实现这种个性化的计算。
第四步,执行优化方案。用集算器SPL编写代码,将数据中客户的维度属性和所属客群合并,按照新的存储结构存入集算器高性能二进制列存文件。以后每个月的月初,将新增数据抽取出来同样存放。
再编写查询的SPL代码,将输入条件(维度属性和求交集的客群)转化为布尔维和按位计算需要的格式,对新的存储结构做游标前过滤、计数。
集算器对外提供JDBC接口,前端应用可以像调用数据库存储过程一样调用集算器的方法,输入参数,获取查询结果。
实际效果
经过两周左右的编码和测试,实际优化效果非常明显。12CPU(核)的虚拟机执行12个月的查询,只需要4秒。而原先100CPU(核)的虚拟机执行同样的查询需要120秒,性能提高了250倍(100CPU*120秒÷12CPU*4秒)。要进一步达到期望的性能目标,也就是10秒内并发完成10-20个单任务,资源消耗完全可以控制在100CPU(核)之内。
这个方案是不需要预计算的,直接在明细数据上查询,非常灵活。任意N个客群交集都是这个计算速度,彻底解决了客群交集的性能问题。
从开发难度来看,SPL做了大量封装,提供了丰富的函数,内置了上述优化方案需要的基本算法。上述算法对应的SPL代码也只有二十行:

写在最后
解决性能优化难题,最重要的是设计出高性能的计算方案,有效降低计算复杂度,最终把速度提上去。因此,一方面要充分理解计算和数据的特征,另一方面也要熟知常见的高性能算法,才能因地制宜地设计出合理的优化方案。本次工作中用到的基本高性能算法,都可以从下面这门课程中找到:点击这里学习性能优化课程,有兴趣的同学可以参考。
很遗憾的是,当前业界主流大数据体系仍以关系数据库为基础,无论是传统的 MPP 还是 HADOOP 体系以及新的一些技术,都在努力将编程接口向 SQL 靠拢。兼容 SQL 确实能让用户更容易上手,但受制于理论限制的 SQL 却无法实现大多数高性能算法,眼睁睁地看着硬件资源被浪费,还没有办法改进。SQL 不应是大数据计算的未来。
有了优化方案后,还要用好的程序语言来高效地实现这个算法。虽然常见的高级语言能够实现大多数优化算法,但代码过于冗长,开发效率过低,会严重影响程序的可维护性。开源的集算器 SPL 是个很好的选择,它有足够的算法底层支持,代码能做到很简洁,还提供了友好的可视化调试机制,能有效提高开发效率,以及降低维护成本。
正在为 SQL 性能优化头疼的同学们,可以和我们一起探讨:http://www.raqsoft.com.cn/wx/Query-run-batch-ad.html
更多相关案例:


用分布式列存分析数据库啊,starrocks、apache doris、clickhouse 等,用 bitmap 和物化识图,轻松搞定,哪那么复杂。
这个问题其实只要有 bit 机制的列式数据库,看起来就有可能搞得定,但结果竟然就是没搞定 😂 。
不过,说的这些办法感觉也没有更轻松,都挺沉重,不容易嵌到用户的技术体系中。SPL 要轻得多,可以完全无缝嵌入,
英文版