


开源SPL提速银行POS机交易报表30+倍
看看问题
S银行POS交易情况报表很慢,业务人员要等待一个多小时(3700秒)才能看到结果,严重影响业务。报表表样如下:

解决步骤
首先,要理解业务和计算特征。POS交易情况表连接数据库取数,定义了4个数据集,分别对应4个SQL。
以POS1 数据集为例,脱敏之后的 SQL 语句如下:
SELECT C_M,
SUM(CASE
WHEN C_FLAG = '0' AND C1_FLG != '1' THEN
1
ELSE
0
END) AS CNT1,
SUM(CASE
WHEN CR_FLAG = '1' AND C1_FLG != '1' THEN
1
ELSE
0
END) AS CNT2,
…
SUM(AMT) AS AMT
FROM SHOP_DETAIL
WHERE
T_CODE not in ('03')
AND DAY_ID >= ?
AND DAY_ID <= ?
AND C_M in (SELECT C_CODE
FROM ORG_LEVEL
WHERE C_M_B = ?
AND CTYPE = '6')
GROUP BY C_M
报表的设计界面如下图:
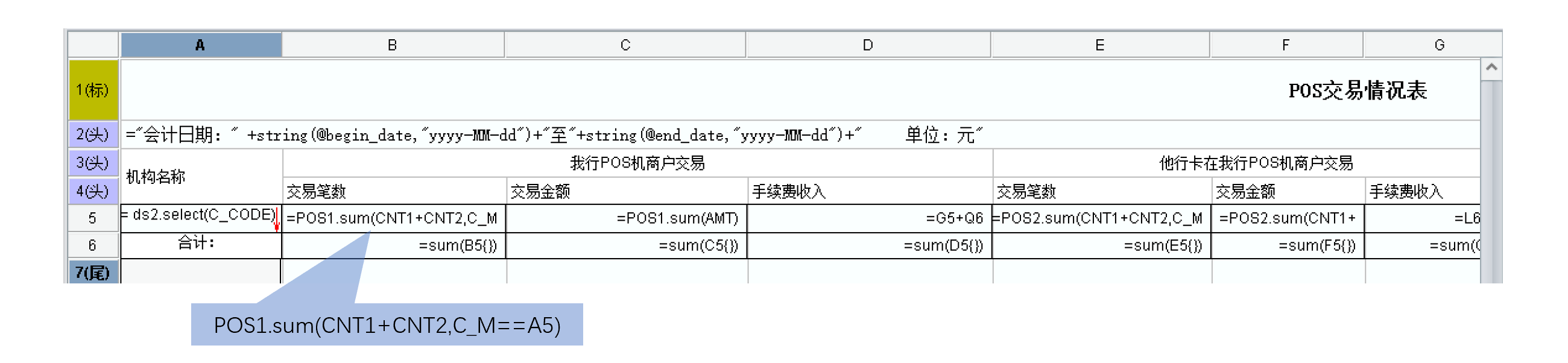
报表工具对于多个数据集是顺序计算的,即先后执行ds1、ds2、POS1、POS2,总时间是4个SQL的执行时间之和。然后再将4个结果集在报表单元格中进行格间计算,完成关联、汇总,最后呈现出结果报表。例如,上图中的B5单元格,POS1数据集就要与A5中的ds2关联。
第二,找到性能瓶颈,确定优化思路。数据集ds1、ds2、POS1、POS2结果条数都不是很多,但是需要关联多次。
报表工具只能用单元格运算来描述多个数据集的关联关系,也只能用遍历的方式实现计算,复杂度高、性能差。要想办法降低复杂度才能提高性能。可以将4个数据集的关联计算从报表中移出,放在数据准备阶段进行。这样做,就可以针对整体数据集执行HASH关联算法,效率要高得多。提前计算的时候,还可以采用内存指针引用的方式做HASH关联,进一步提高计算性能。
四个数据集执行时间都比较长,顺序执行时4个SQL加起来时间就更长了。我们发现,后台数据库比较空闲,如果能采用并行提交SQL执行的方式,总的执行时间会减少很多,后台数据库负载压力增加也在可接受范围内。
第三,确定技术选型和实施方案。报表单元格中的关联计算要在数据准备阶段提前完成,最常见的做法是合并SQL,由数据库完成关联计算。但是,我们无法用SQL写出4个结果集全内存指针引用关联的脚本,也没办法实现子查询并行执行。实际测试结果也证明,合并起来的SQL执行时间还会超过4个SQL依次执行的时间之和。而且,报表数据集对应的SQL都有几十行,如果将4个SQL合并成一个,会有上百行,很难阅读和维护。所以,将4个SQL合并,由数据库完成关联计算的办法无法有效提高性能,也不利于后期维护。
使用Java为报表开发自定义数据集接口,当然可以实现上述算法,但这些运算在Java中非常难写,仅一个HASH关联就要数百行代码,而且还不通用。过大的编码量会导致实现周期过长,还容易出现代码错误隐患,也很难调试和维护。
开源集算器的SPL语言提供封装好的函数,支持上述所有的算法,包括并行提交SQL和全内存指针引用方式关联,能够让我们用较少的代码快速实现个性化的计算。
第四,实现优化方案。编写SPL脚本,先用4个线程并行连接数据库,执行4个SQL。并行执行的总时间,是最慢那个SQL的执行时间,基本上是原来4个SQL依次执行总时间的四分之一。最后返回结果。
在报表工具中,连接数据库的4个数据集全部删掉,而使用 SPL 作为自定义数据集,调用编写好的SPL脚本,返回一个结果集ds1,相当于原来的ds1、ds2、POS1、POS2。SPL 提供有标准JDBC接口,报表工具可以象调用存储过程一样调用SPL脚本,向报表工具返回关联好的结果集。
之后,报表工具就只需要对关联好的结果集进行汇总即可,避免了单元格中的关联计算。修改后报表设计界面如下图:

效果如何
经过几天时间的修改、测试,报表计算呈现的时间由原来的3700秒缩短为105秒,速度提高了35倍,效果非常明显。
从开发难度来看,SPL做了大量封装,提供了丰富的函数,内置了上述优化方案需要的基本算法。上述算法对应的SPL代码也只有十几行:
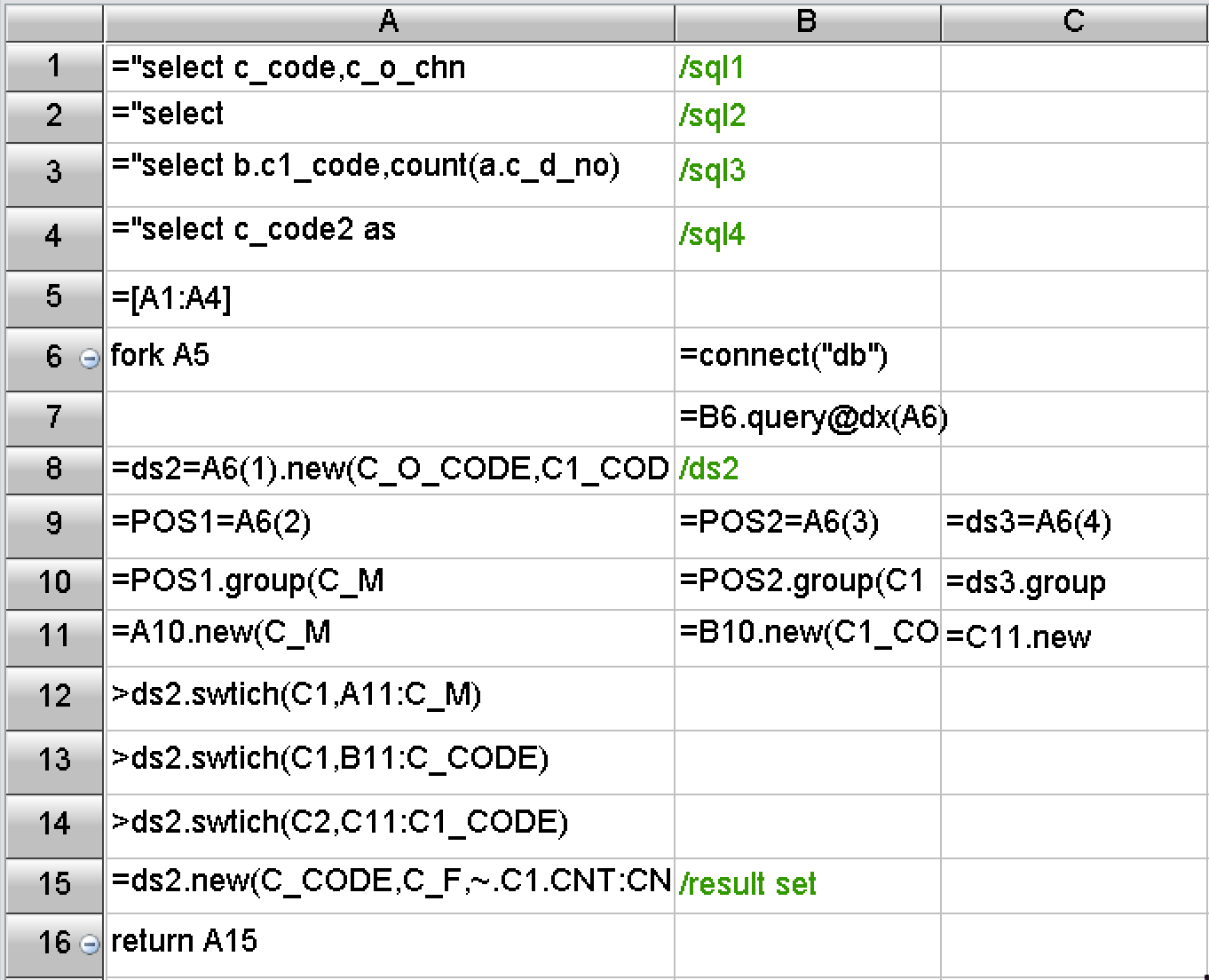
相比上百行的复杂SQL来说,SPL代码短很多,结构清楚、容易阅读,也更容易编写和修改。
后记
解决性能优化难题,最重要的是设计出高性能的计算方案,有效降低计算复杂度,最终把速度提上去。因此,一方面要充分理解计算和数据的特征,另一方面也要熟知常见的高性能算法,才能因地制宜地设计出合理的优化方案。本次工作中用到的基本高性能算法,都可以从下面这门课程中找到:点击这里学习性能优化课程,有兴趣的同学可以参考。
有了优化方案后,还要用好的程序语言来高效地实现这个算法。虽然常见的高级语言能够实现大多数优化算法,但代码过于冗长,开发效率过低,会严重影响程序的可维护性。SPL 是个很好的选择,它有足够的算法底层支持,代码能做到很简洁,还提供了友好的可视化调试机制,能有效提高开发效率,以及降低维护成本。

