


开源SPL提速银行贷款跑批任务150+倍
【摘要】
互联网贷款产品指标跑批任务耗时 7.9 小时,亟需优化!点击了解开源 SPL 提速银行贷款跑批任务 150+ 倍
问题说明
T银行通过某互联网渠道对客户发放贷款。放款、还款明细数据存放在Mysql中,每天都会增量增长。T银行经常需要执行跑批任务,统计汇总指定日期之前的所有历史数据。跑批任务由Mysql的SQL语句实现,运行总时间7.9小时,占用了过多的跑批时间,甚至影响了其他的跑批任务,必须优化。
从数据量来看,截止到2019-05-09,放款表(2千万条数据,9G);还款表(4千万条数据,16G),两个表每天都要增长几万条数据。跑批用的服务器内存只有16G,并不算大。
实际跑批动作由两句SQL构成,下面说明如下:
脱敏之后的SQL1语句:
select
'2019-05-09' AS 业务日期,
A.pcode AS 产品代码,
sum(A.eamt) AS 放款金额,
count(DISTINCT A.cust_no) AS 放款户数,
count(1) AS 放款笔数,
count(DISTINCT CASE WHEN B.con_no IS NULL THEN NULL ELSE A.cust_no END) AS 收回户数,
sum(CASE WHEN B.con_no IS NULL THEN 0 ELSE 1 END) AS 收回笔数,
sum(IFNULL(B.SXJE,0.00)) AS 收息金额,
sum(IFNULL(B.DCJE,0.00)) AS 代偿金额,
DATE(CURRENT_DATE()) AS 维护日期
from loan_detail A
LEFT JOIN
(SELECT X.con_no,sum(X.r_amt-X.p_amt-X.p1_amt) AS LXSR,
sum(IF(X.r_type='04' OR X.r_type='05',X.p1_amt+X.p1_amt,0.00)) AS DCJE
FROM repay_detail X
WHERE open_day<='2019-05-09' GROUP BY X.con_no ) as B ON A.con_no=B.con_no
where A.open_day <='2019-05-09'
GROUP BY A.p_code
SQL1语句的主表是放款明细表,过滤条件是日期小于2019-05-09,按照产品代码分组。主表左连接一个子查询,关联字段是合同号con_no。子查询的主表是还款明细表,过滤条件是日期小于2019-05-09,按照合同号分组。
SQL1计算的目的是统计各个互联网贷款产品的一些指标:放款金额、笔数、户数、收回户数、笔数等等。
脱敏之后的SQL2语句:
select t.p_code as 产品码,
CASE
when t.amtT = '01' then '1000元以下'
when t.amtT = '02' then '1000元-3000元'
when t.amtT = '03' then '3000元-5000元'
when t.amtT = '04' then '5000元-1万元'
when t.amtT = '05' then '1万元-5万元'
when t.amtT = '06' then '5万元-10万元'
when t.amtT = '07' then '10万元-20万元'
when t.amtT = '08' then '20万元-30万元'
else '30万元以上'
end as 维度,
SUM(e_amt) as 发放金额,
COUNT(DISTINCT cust_no) as 客户数
from
(SELECT p_code,
case
when e_amt > 0 and e_amt <= 1000 then '01'
when e_amt > 1000 and e_amt <= 3000 then '02'
when e_amt > 3000 and e_amt <= 5000 then '03'
when e_amt > 5000 and e_amt <= 1*10000 then '04'
when e_amt > 1*10000 and e_amt <= 5*10000 then '05'
when e_amt > 5*10000 and e_amt <= 10*10000 then '06'
when e_amt > 10*10000 and e_amt <= 20*10000 then '07'
when e_amt > 20*10000 and e_amt <= 30*10000 then '08'
else '09'
end as amtT,
e_amt,
cust_no
FROM loan_detail AS X1
left join (select distinct loan_no from loan_detail where open_day <= '2019-05-09' and e_amt <0.00) AS X2 on X2.loan_no=X1.loan_no
WHERE open_day <= '2019-05-09' and X2.loan_no is null
) t GROUP BY t.amtT,t.p_code
SQL2语句的最外层是按照产品代码和金额段分组汇总。中间层是给每行记录计算出对应的金额分段号。X2子查询是找出所有放款数据中冲正的记录。冲正是指交易之后,撤销的时候要增加一条贷款号loan_no相同,金额为负数的记录。X1与X2的关联,目的是:贷款号loan_no和冲正记录相同的所有记录都不参加统计。
SQL1性能优化
第一步,理解计算任务特征。放款表和还款表是一对多关系,一个合同号对应一条放款记录,对应多条还款记录。我们可以把两表看作主子表关系。还款表按照合同号分组之后,就和放款表是一一对应的同维表关系了,也就是都以合同号为主键了。每个合同号对应的还款记录是多条,但是并不是很多。产品代码总数只有两个,未来也不会很多。
第二步,分析性能瓶颈。经过分析和测试发现,SQL性能差的主要原因是两个大表先分组再关联计算太慢。4千万条数据的还款表在硬盘上占用16G空间,按照合同号分组,分组结果也有2千万左右。数据库计算时内存不够,要不断读写硬盘缓存文件。分组的结果还要和2千万数据的放款表关联(JOIN)。数据库的JOIN一般采用HASH算法,复杂度是SUM(Ni*Mi),所以大表分组、关联要几个小时才能算完。
第三步,设计优化方案。跑批优化的重点是解决“两个大表先分组再关联”这个瓶颈。如果将放款表和还款表按照合同号有序存放,那么还款表按照合同号分组,就可以合并相邻并且相等的合同号即可,一次遍历就可以完成分组。而且,分组之后的结果也是对合同号有序的,可以和放款表有序归并,复杂度是M+N,性能会比HASH算法要好很多。如果我们利用有序游标,将大表分组、分组后归并用一次遍历完成,性能提升就可能非常明显。
第四步,设计实现方案。关系数据库建立在无序集合理论的基础上,没有办法把有序的结果事先保存起来。所以,上面的优化方案没有办法在数据库里实现,需要把数据外置到文件来自行处理。这个SQL是典型的跑批任务,新增数据每天生产库导出到跑批库,数据本来就要移动,我们可以在过程中同时将数据同时写出到文件,以实现上述的高性能算法。文件系统的IO性能更好,写入到文件会比写入到数据库更快,数据外置在工程上也是可行的。
第五步,数据导出。从数据库中导出放款表和还款表,按照合同号排序之后,存放到高性能文件中。这里的排序很重要,是后续实现大分组和有序归并的前提条件。因为数据库JDBC性能较差,所以第一次导出全部历史数据的时候速度会比较慢。但是以后每天导出新增数据,增量更新高性能存储文件就很快了。
第六步,编写新的算法代码,实现性能优化。先按照合同号对放款文件定义有序分组计算,这里仅是定义了文件游标,并没有实际计算。分组之后的游标,再定义和放款文件有序归并的计算。最后,将文件游标分批读入内存,边读边计算分组、关联、再按照产品号汇总,一次遍历完成三个步骤的计算。由于产品号很少,因此可以在内存中直接按照产品号汇总得到结果。如下图:
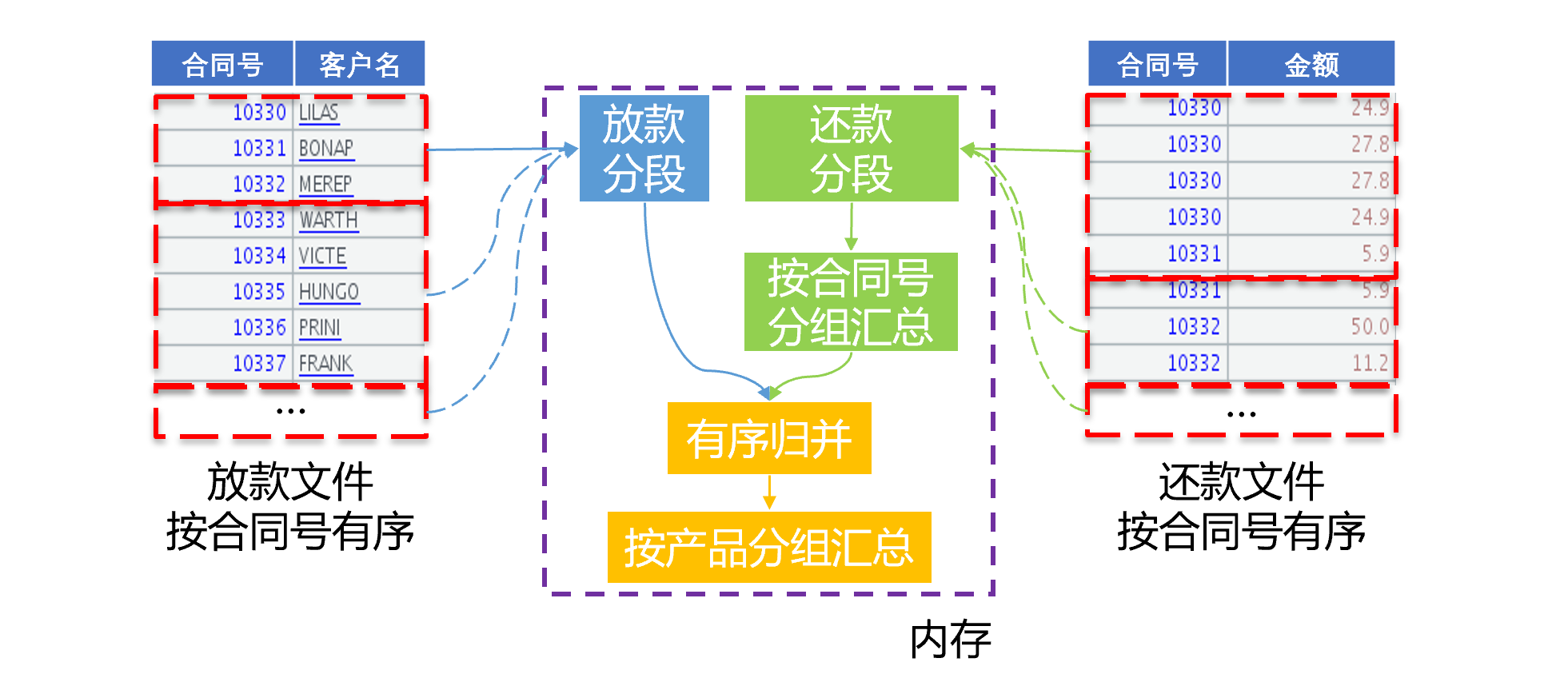
图中可以看出,两个大表的一次遍历完成了分组、关联、再分组汇总计算,只需要遍历一次,也无需生成中间结果,缩短了读写硬盘的时间,性能提升明显。这种游标上定义多步骤计算,只用一次遍历把所有步骤都计算出来的算法,我们称为延迟游标。
SQL2性能优化
第一步,理解计算任务特征,分析性能瓶颈。放款数据量很大,过滤冲正数据时,需要计算大表自关联,速度比较慢。去掉冲正数据之后,还有两千万放款记录。按照金额分段,两个CASE WHEN语句理论上都会一个个条件依次判断,平均每条记录会判断8次,计算效率不高。
第二步,设计优化方案。放款数据中的冲正数据量不大,可以提前算好内存存放,用来过滤放款数据。这样可以将大表自关联转化为大表和小表的关联。冲正表单独存放,每次计算的时候就不必在放款表中过滤取出,可以有效提高性能。每天更新贷款新数据时,同时计算更新冲正表数据。关联之后按照金额和产品分段汇总,分段数只有9个,产品代码只有两个,可以采用内存分组。按照金额分段计算,我们采用二分法,比较计算的次数会减少很多。我们还要对存放在高性能文件中的放款数据采用多线程并行计算,利用多核CPU的计算能力进一步提速。
第三步,设计实现方案。金额分段计算中,要采用二分法,分段必须是有序的。比较简单的SQL写不出这样的语句,一定要用SQL实现二分法,代码会复杂到性能更差的地步。有些数据库也许会自动优化那个分段的CASE WHEN语句,但从本次任务的测试结果来说,Mysql并不会。由于SQL1已经要在外置文件数据上进行优化,SQL2也需要基于文件数据来做,正好更容易实现这个算法。放款表和冲正数据,通过贷款号关联,仅仅是用来过滤放款表。而且冲正数据很少,可以全内存存放,因此放款表不必一定要按照贷款号有序。
第四步,编写新的算法代码,实现性能优化。跑批服务器内存16G,无法装入放款明细数据,不能进行全内存计算,因此,要将放款数据从高性能文件中用游标分批取出。再用内存中的冲正数据,比较放款号,过滤放款数据。过滤后,用二分法计算金额分段,如下图:
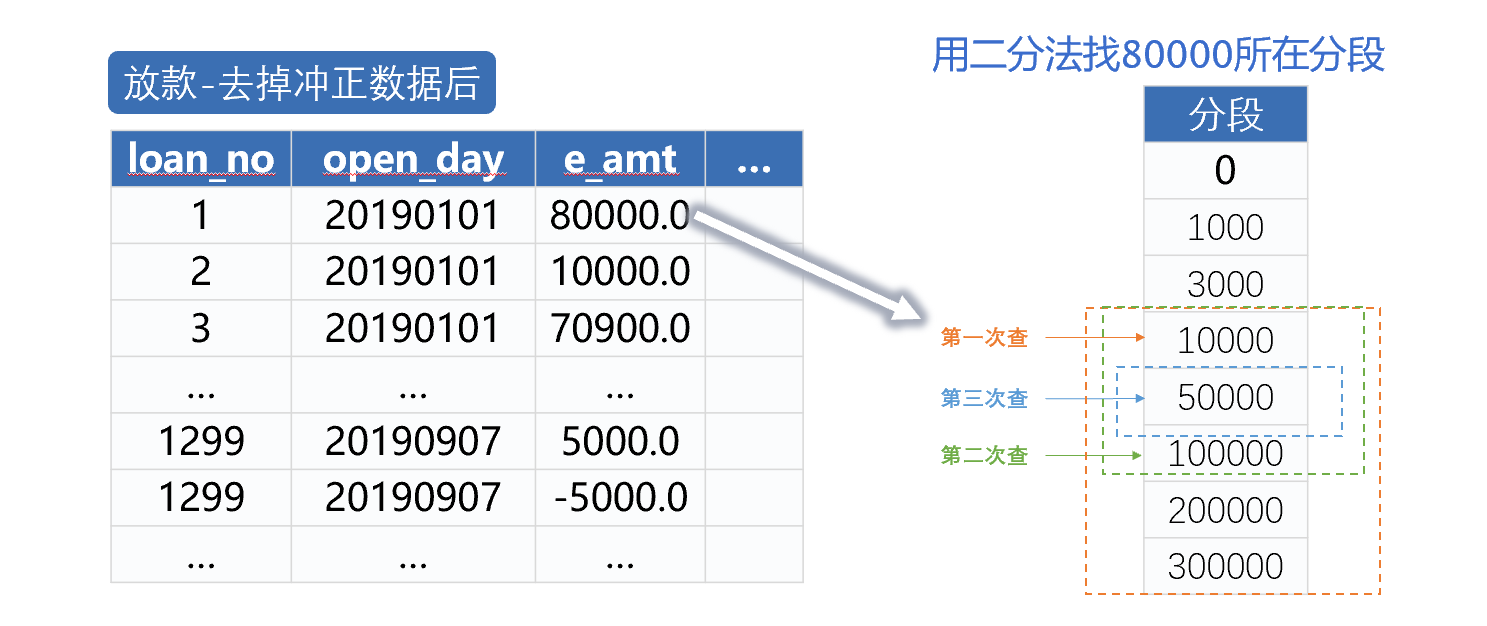
从图中可以看到,普通方法计算分段,最少计算2个数值比较表达式,最多计算16个,图中80000要计算10个表达式,而二分法查找只需要计算3个表达式。冲正过滤和金额分段都可以采用多线程并行计算方式。
性能优化效果
确定了优化方案和实现方案后,还要选择适用的工具来实现方案。关系数据库和SQL已经在分析过程中就被否决了。服务器内存不大,无法装入全部数据,也无法实施全内存计算技术(包括某些被优化过的内存数据库)。使用Java或C++等高级语言可以实现上述算法,但编码量过大,实现周期过长,容易出现代码错误隐患,也很难调试和维护。开源集算器的SPL语言提供上述所有的算法支持,包括高性能文件、文件游标、有序分组、有序关联、延迟游标、二分法等机制,能够让我们用较少的代码量快速实现这种个性化的计算。
经过几天时间的编程、调试和测试,我们完成了性能优化的验证,性能提升非常明显。优化前,用数据库执行SQL1需要7.8小时,优化之后单线程需180秒,2线程仅需137秒;用数据库执行SQL2需要249秒,优化之后单线程需50秒,2线程仅需要25秒。两个任务总的速度提高174倍。
在编程难度方面,SPL做了大量封装,提供了丰富的函数,内置了上述优化方案需要的基本算法和存储机制。上面描述的算法并不太简单,但实际编写的代码并不长,和原来的SQL相比差不多,开发效率很高。
上述SQL1对应的计算代码如下图:

SQL2对应的计算代码如下:

后记
解决性能优化难题,最重要的是设计出高性能的计算方案,有效降低计算复杂度,最终把速度提上去。因此,一方面要充分理解计算和数据的特征,另一方面也要熟知常见的高性能算法,才能因地制宜地设计出合理的优化方案。本次工作中用到的基本高性能算法,都可以从下面这门课程中找到:点击这里学习性能优化课程,有兴趣的同学可以参考。
很遗憾的是,当前业界主流大数据体系仍以关系数据库为基础,无论是传统的MPP还是HADOOP体系以及新的一些技术,都在努力将编程接口向SQL靠拢。兼容SQL确实能让用户更容易上手,但受制于理论限制的SQL却无法实现大多数高性能算法,眼睁睁地看着硬件资源被浪费,还没有办法改进。SQL不应是大数据计算的未来。
有了优化方案后,还要用好的程序语言来高效地实现这个算法。虽然常见的高级语言能够实现大多数优化算法,但代码过于冗长,开发效率过低,会严重影响程序的可维护性。SPL是个很好的选择,它有足够的算法底层支持,代码能做到很简洁,还提供了友好的可视化调试机制,能有效提高开发效率,以及降低维护成本。
更多相关案例:


可以把 spl 源程序都贴出来吗?想学习一下