


8. 大数据游标基本使用
文件 RegisterSiteA.csv 中存储了某次考试的报名信息,数据量比较大,数据按照报名时间 REGTIME 排序。(1) 获取前 100 条报名信息;(2) 计算 2024 年 12 月 3 日有多少人报名;(3) 取出报名者中,ID 排名前 100 名的报名信息;(4) 如果不同的报名者,ID 各不相同,请判断是否有人重复报名。
参考答案:

解答:
| A | B | |
|---|---|---|
| 1 | =file(“RegisterSiteA.csv”).cursor@ct() | =A1.fetch(100) |
| 2 | >A1.reset() | 2024-12-3 |
| 3 | =A1.skip(;date(REGTIME)!=B2) | =A1.fetch@x(;date(REGTIME)) |
| 4 | =file(“RegisterSiteA.csv”).cursor@ct().sortx(ID) | =A4.fetch@x(100) |
| 5 | =file(“RegisterSiteA.csv”).cursor@ct() | =A5.skip() |
| 6 | >A5.reset() | =A5.groups(;icount(ID):IDS) |
| 7 | =B5>B6.IDS |
A1 用数据文件创建游标,由于使用逗号分隔的 csv 文件,且首行作为标题,因此添加 @ct 选项。B1 用 fetch 函数直接指定返回记录数,就能得到 (1) 的结果。由于游标是单次遍历的,因此需要查询其它数据时,需要在 A2 中用 cs.reset()将其回转。A3 用 cs.skip(;x)函数,在分号后的参数不是用来指定跳过记录的条数的,而是将将日期不符合需求的记录跳过;此时 B3 继续使用游标查询,就可以从当前位置起继续读取数据了,用 cs.fetch(;x)函数,读取数据一直到 x 发生变化,在这里就是日期有了变化为止。添加 @x 选项后,游标读取数据后将关闭。
A4 重新创建游标,由于文件中的数据是按照 REGTIME 排序的,而非 ID,因此需要用 cs.sortx() 函数,使得游标取数时在缓存中完成排序。此时再在 B4 中用 fetch 函数,取得的数据就是排序后的结果了。
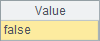
A5 再次新建了游标,B5 仅调用 skip 函数,此时会跳过所有记录,并返回实际跳过的记录数。A6 回转游标后,B6 用 groups 对游标中的数据分组汇总,这里未指定分组表达式,将对所有数据汇总,icount 计算非重复计数。B5 和 B6 中结果如下:


可以看到,前者为计算出的数值,而后者为单条记录的序表,两者相同说明没有人重复报名。


英文版