


9. 游标归并计算
文件 RegisterSiteA.csv,RegisterSiteB.csv 和 RegisterSiteC.csv 中存储了某次考试的报名信息,数据量比较大,数据分别按照报名时间 REGTIME 排序。(1) 查询报名时间排名在 101~200 名的人员信息;(2) 返回 ID 在 24110001~24110100 范围内人员的报名信息;(3) 请计算实际有多少人报名,并列出重复报名人员的报名信息
参考答案:
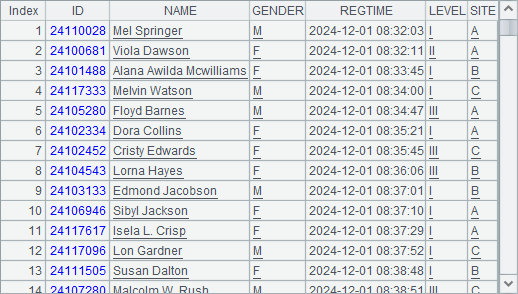
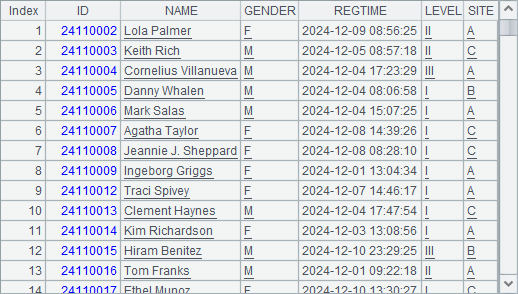

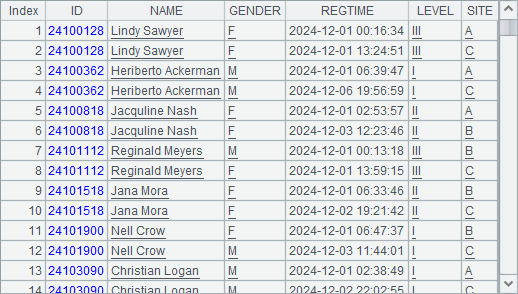
解答:
| A | B | C | |
|---|---|---|---|
| 1 | RegisterSiteA.csv | RegisterSiteB.csv | RegisterSiteC.csv |
| 2 | =[A1:C1].(file(~).cursor@ct()) | ||
| 3 | =A2.merge(REGTIME) | =A3.skip(100) | =A3.fetch(100) |
| 4 | >A2.(~.reset()) | ||
| 5 | =A2.(~.sortx(ID)).merge@u(ID) | =A5.skip(;between(ID, 24110001:24110100)) | =A5.fetch@x(;ID>24110100) |
| 6 | >A2.(~.reset()) | =A2.merge(REGTIME).groups(; count(~):Count,icount(ID):ICount) | |
| 7 | >A2.(~.reset()) | ||
| 8 | =A2.(~.sortx(ID)).merge(ID) | =A8.select(ID==ID[-1] || ID==ID[1]) | =B8.fetch() |
A2 用文件生成游标序列。A3 用 CS.merge() 函数将游标序列归并,归并后的游标类似于单独游标的使用,如 skip 和 fetch 等,B3 跳过前 100 条记录后,C3 获取到 101~200 的报名记录,从结果中可以看到,数据来源于各个报名点 SITE,但获取到的数据是按报名时间排序的。
查询后,如果继续执行后续的查询,需要将使用到的文件游标回转,如 A4 中的处理。如果需要按照 ID 查找人员信息,需要在游标归并前先将各个游标用 cs.sortx()处理排序,如 A5 中的处理,另外 CS.merge() 中添加了 @u 选项,使得 ID 相同的数据不重复出现。B5 中执行 cs.skip(;x),跳过不满足数据区间要求的数据后,在 C5 中用 cs.fetch(;x) 可以从游标中取数,一直到 x 为 true,即可查到所需 ID 范围的报名信息。
B6 中仍然用归并游标查询数据,但直接对全部数据做了汇总计算,通过对比,可以了解其中确实存在个别人员重复报名。
A8 中仍然按 ID 将游标归并,B8 中通过跨行比较,选出 ID 与其前后数据相同的数据,C8 中用 fetch 即可列出哪些报名信息是重复的。在比较时仅比较 ID 是否一致,而不考虑其它数据。


英文版