


这可能是最适合探索式数据分析的工具
数据分析需要探索式
对于数据分析,许多任务并非固定的查询,而是需要灵活的分析和判断。比如,电商数据中的用户行为分析、产品推荐、库存优化,或者金融行业的风险评估和客户分类等,都往往没有预先固定的查询路径。分析师需要根据数据表现逐步调整方向,以便深入挖掘潜在的规律和异常。这类动态的分析方式正是探索性数据分析的核心。
探索式数据分析的特点在于灵活的猜测—验证模式。与设定好流程的固定查询不同,探索分析是一个不断提出假设并验证的过程。分析师基于数据的初步观察,提出一个假设,然后通过数据验证来检查假设是否成立。每次验证结果都会影响分析的后续步骤:若验证成功,则可能进一步细化假设;若验证不成立,则需改变方向或寻找其他关联因素。例如,在分析电商平台的用户活跃度时,分析师可能最初猜测活跃度与促销活动相关,但在验证后发现这一相关性并不显著,于是转而研究其他因素,如浏览时间或优惠幅度。这种反复迭代的过程,有助于逐步揭示数据中的深层关系。
探索分析在数据分析中扮演着重要角色,分析师可以在没有预设框架的情况下,灵活调整路径来发现新模式和新规律。
Excel 是探索式数据分析工具,但是…
Excel 就是一款非常出色的探索性分析工具,凭借其便捷的操作和强大的可视化能力,使分析师可以快速查看每一步计算结果,并随时进行调整。在简单数据分析中,Excel 可以很好地实现灵活的“猜测—验证”过程,是一种非常直观的探索性数据分析工具。
然而,Excel 在计算能力上却显得捉襟见肘。它虽然能完成基本的表格计算和统计操作,但面对复杂的任务就显得力不从心。例如,以下这些计算在 Excel 中就很难完成:
• 找出每 7 天内至少 3 次点击相同类别产品的用户,以分析用户偏好;
• 计算用户在网站上每次操作间隔超过 15 分钟后的再次访问时间,用于分析用户活跃度;
• 确定某商品在一个月内库存量低于安全库存线超过 3 次的具体日期,以优化库存管理。
这些计算不仅涉及复杂的逻辑运算,还需要多步计算、条件筛选和时间序列处理,Excel 难以支撑。
那么,用编程语言来实现这些复杂运算可以吗?毕竟没有什么事是不能编程实现的。
比如数据分析师常用的 SQL 和 Python,都具有较强的计算能力,可以一定程度应对复杂的数据运算,满足分析过程中的计算需求。然而,它们的交互性却相对不足,难以实现探索分析要求的实时“对话”体验。SQL 必须整体执行,每次查询后才会返回最终结果,缺乏逐步反馈的能力,想要观察中间步骤时需要将查询层层拆分。Python 的交互性稍好一些,但分析师仍需通过 print 等方式主动输出中间结果,分析过程也较为麻烦,难以实现 Excel 那种流畅的探索体验。
不仅如此,有的任务用 SQL 和 Python 编程也不见得简单。比如股票分析中可能要计算每支股票的最长连涨天数。
SQL:
SELECT CODE, MAX(con_rise) AS longest_up_days
FROM (
SELECT CODE, COUNT(*) AS con_rise
FROM (
SELECT CODE, DT,
SUM(updown_flag) OVER (PARTITION BY CODE ORDER BY CODE, DT) AS no_up_days
FROM (
SELECT CODE, DT,
CASE WHEN CL > LAG(CL) OVER (PARTITION BY CODE ORDER BY CODE, DT) THEN 0
ELSE 1 END AS updown_flag
FROM stock
)
)
GROUP BY CODE, no_up_days
)
GROUP BY CODE
这种嵌套 SQL 恐怕 DBA 都不容易写出来,对数据分析师来说就更难了。
Python:
import pandas as pd
stock_file = "StockRecords.txt"
stock_info = pd.read_csv(stock_file,sep="\t")
stock_info.sort_values(by=['CODE','DT'],inplace=True)
stock_group = stock_info.groupby(by='CODE')
stock_info['label'] = stock_info.groupby('CODE')['CL'].diff().fillna(0).le(0).astype(int).cumsum()
max_increase_days = {}
for code, group in stock_info.groupby('CODE'):
max_increase_days[code] = group.groupby('label').size().max() – 1
max_rise_df = pd.DataFrame(list(max_increase_days.items()), columns=['CODE', 'max_increase_days'])
Python 简单一些,但还要循环来做,整体仍然繁琐。
这个任务用 Excel 反而很简单。第一步按照股票代码、日期排序;第二步填写公式计算连续上涨天数;第三步分组汇总计算最长连续上涨天数;第四步收缩显示。很直观地四步搞定。
从这个意义讲,SQL 和 Python 的计算能力也并不是很便捷,有时还不如 Excel 顺手。
实施探索分析时,计算能力和交互性不可偏废——既要强大的计算能力支持复杂运算,又要足够的交互性来实现随时调整、随时反馈的分析过程,而强计算还能简化复杂运算,即用更简单的办法实现计算目标。
SPL 是更适合探索式数据分析的工具
同时具备交互性和强计算能力的数据分析编程语言 SPL(Structured Process Language)可能是最佳选择。
强交互能力
SPL 与其他编程语言的一个显著区别在于其拥有良好的交互性。使用 SPL 不仅可以分步来做,还能实时查看每步的计算结果,交互性体验跟 Excel 非常相似。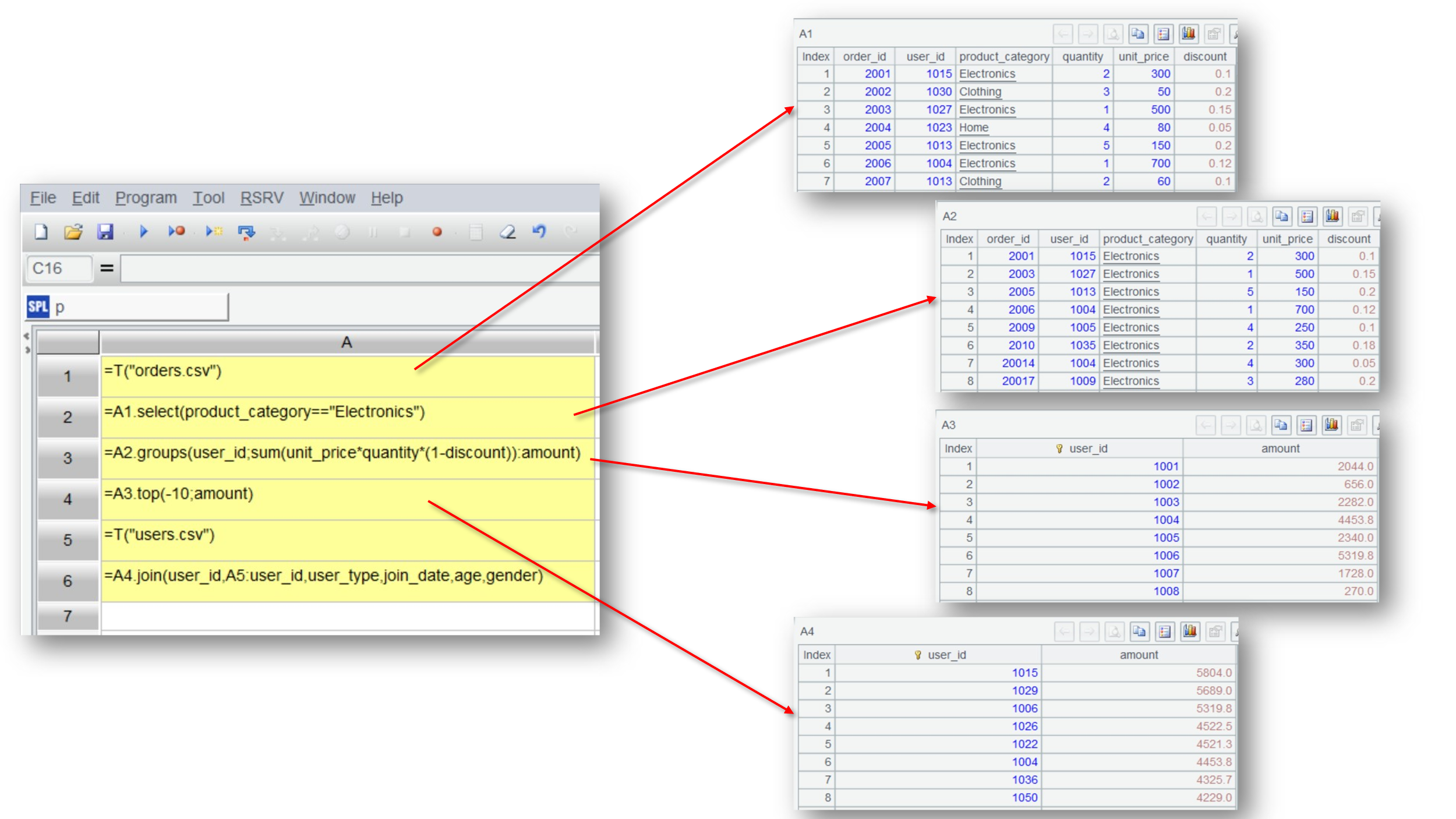
SPL 的代码写在网格里,多个步骤落在不同格子里,格子之间通过单元格名来相互引用结果。点选单元格就能查看每步的计算结果,发现有错可以立即修改,然后根据已计算结果决定下一步的操作,跟 Excel 的操作方式几乎一致。
再整体看一下 SPL 的编程环境(IDE),除了上面提到的特点,SPL 还能单独执行某一步计算,这样可以避免重复执行带来的时间浪费。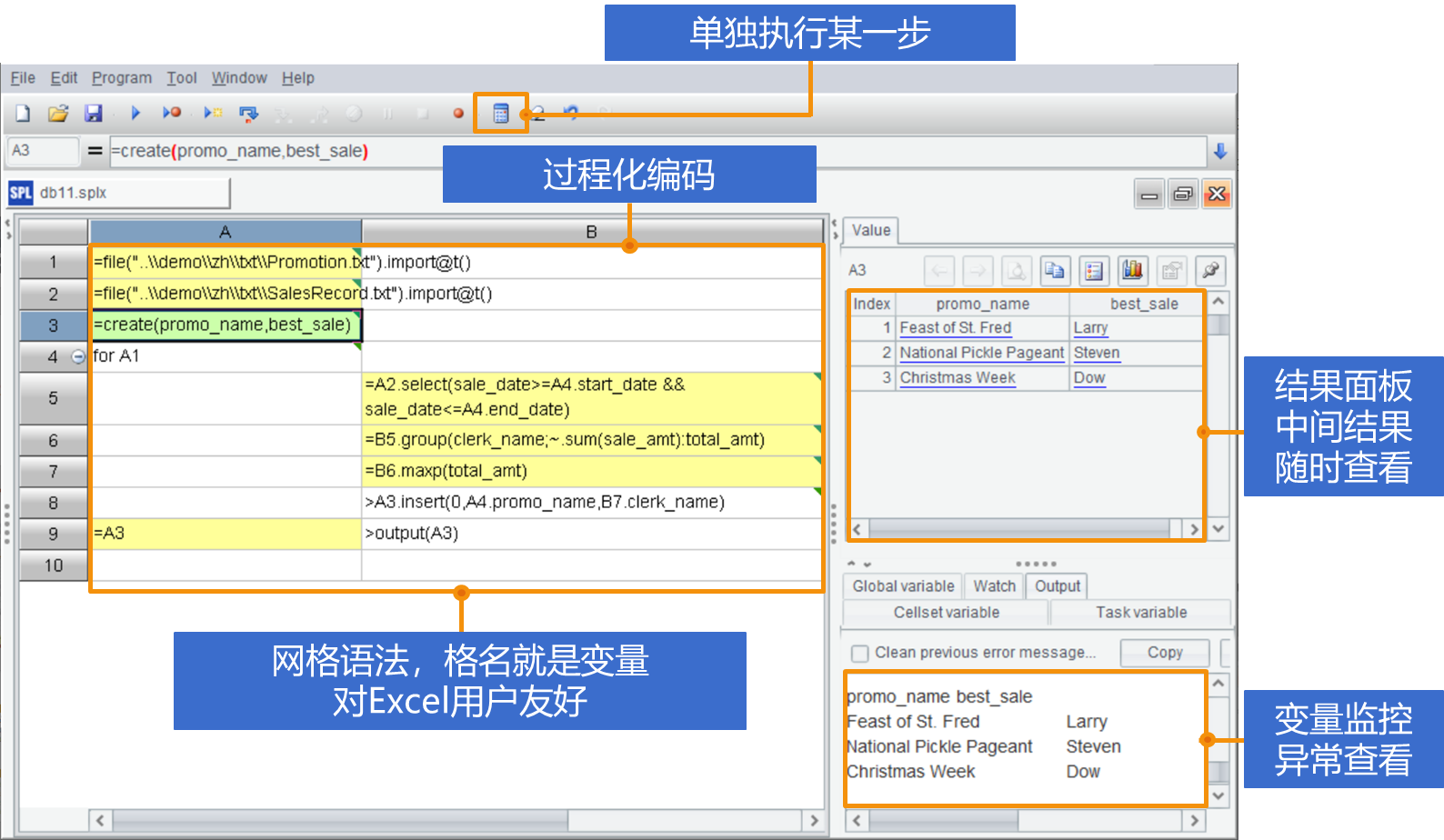
有了过程化的分步支持、网格语法与格名引用机制,以及可以观察每步结果的可视面板,SPL 天然适合完成探索分析。
强计算能力
在计算能力方面,SPL 提供了大量表格数据计算类库和数据对象,尤其擅长集合有序运算。比如上面计算股票连涨天数的例子,用 SQL 和 Python 都没 Excel 简单,但用 SPL 来做就只需要三行,非常简洁:
A |
|
1 |
StockRecords.xlsx |
2 |
=T(A1).sort(DT) |
3 |
=A2.group(CODE;~.group@i(CL<CL[-1]).max(~.len()):max_increase_days) |
SPL 的强计算能力还表现在处理 Excel 不擅长的运算上。比如在下面的数据中找出每个月都能进 top10 的明星产品。
Excel 做交集很麻烦,用 SPL 来做很简单
A |
|
1 |
=file("product.xlsx").xlsimport@w() |
2 |
=transpose(A1).m(2:).isect() |
Excel 插件
SPL 还提供了 XLL 插件,用户可以在熟悉的 Excel 环境中,利用 SPL 强计算能力,在 Excel 内直接写 SPL 公式,同时发挥 SPL 和 Excel 优势。
上面做交集的运算在 Excel 内直接写 SPL 代码会更简洁:
总体来看,SPL 以强大的计算能力和灵活的交互性,成为探索式数据分析的理想工具。不仅能简化复杂的数据处理逻辑,还支持逐步查看和调整分析过程,提供了与 Excel 类似的实时反馈体验。相较于 SQL 和 Python 的编码方式,SPL 能够帮助分析师在过程中迅速获取反馈、随时调整策略,真正实现探索分析。SPL 结合了编程语言的运算能力与 Excel 的交互性,或许正是数据分析领域中探索任务的最佳选择。


英文版