


使用频率较低的历史大数据该怎样存储和计算
年代久远的数据使用频率通常会变低,这时候怎么存储和计算就是个问题。
使用频率低并不等于完全不再使用。如果把这些数据都从数据库中归档出去,再查询统计时又要再次导入数据库,费时费力。经常会发生查询只要 3 分钟,导入却要用 3 小时的尴尬局面。
让这些数据一直占用着数据库空间也不行。很多企业会采用商用数据库,其实例和占用的空间都不便宜。即便是采用开源免费产品,运维一个(甚至多个)始终活着的数据库(可以停机,但不能卸载)也非常麻烦,入了库的数据就不能随意搬动,相应的数据库引擎也要一直与之绑定。无论如何,这都是个高成本的事情,而使用率却很低。
数据量小还好说,历史数据量积累到很大的时候,这就成为一个进退两难的问题。存进数据库不合适,不存进数据库也不合适。
造成这个结果的原因有两点:1. 应用中的计算能力目前主要由数据库提供,要计算数据就需要依赖于数据库;2. 数据库通常是个存算不分离的封闭体系,不能仅仅使用其计算能力随意计算指定的数据。
那么,要解决它也是从这两方面入手:1. 不依赖于数据库的计算引擎;2. 能够存算分离的计算机制。
使用存算分离的云数据仓库是一种解决方案。数据始终装入数据库,可以随时计算,低频使用时消耗计算资源少,费用也不高。不过,云数据仓库在逻辑上也还是封闭的,同一个库中管理太多历史数据时也容易造成混乱,而分拆到多个库的运维成本又会上升,还难以混合计算。有些场景因为安全原因也不方便把数据上搬到公有云上,而在企业内部建设一套存算分离的云数据库就会太沉重了。
esProc SPL 是个更好的轻量级解决方法,它同时能满足上述两个方面,即不依赖于数据库的计算能力以及天然的存算分离机制。
esProc SPL 是纯 Java 开发的开源计算引擎,能够无缝地嵌入进 Java 应用,提供不依赖于数据库的强大计算能力。
我们知道,文件是最便宜最方便的存储方案。历史数据通常不再变化,数据之间不再有约束性和一致性的耦合性问题,存成文件后很方便分目录管理,可以随意根据情况搬动位置。比如存储到网络文件系统或 HDFS 或是云存储中获得共享能力以及超强的可靠性。
esProc SPL 可以将把历史数据转储成文件,并提供文件上的计算能力。
esProc SPL 设计了高性能的二进制文件格式。支持压缩、列存、索引,以及大数据的游标及分段并行机制和特有的有序存储格式。SPL 中提供了丰富的结构化数据运算库和许多传统数据仓库没有的高性能算法,可以方便地写出性能高出数量级的代码,完全可以取代数据仓库的所有计算能力。
esProc SPL 计算的数据文件可以置于任何能被程序访问到的地方,无论是本地文件系统还是网络文件系统以及 HDFS,或是云存储(S3),只要开放了权限就都可以被 esProc SPL 计算。esProc SPL 本身就是个计算引擎,天然支持存算分离。基于这些成熟的第三方存储方案,可以充分利用这些技术带来的可靠性和安全性以及便利的可共享能力。
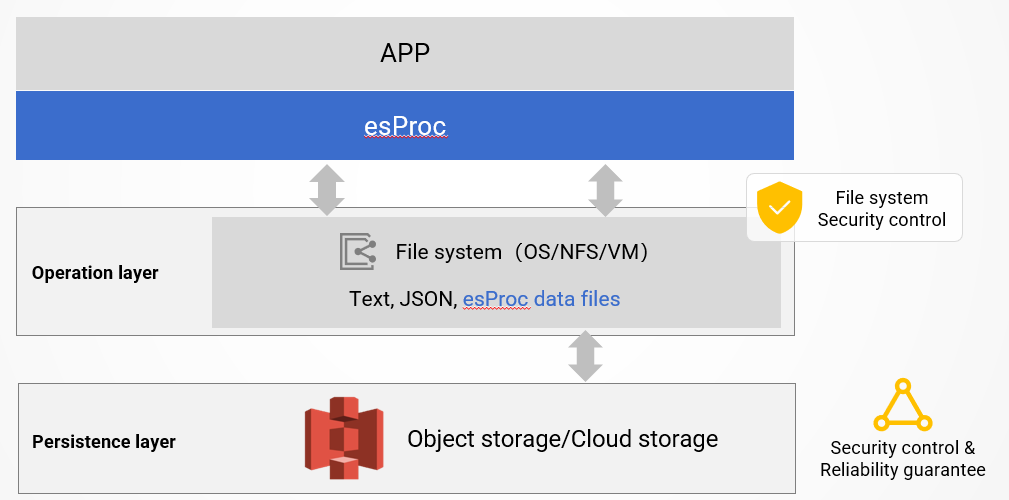
esProc SPL 还内置支持了非常丰富的外部数据源:

这样可以方便地实现 esProc 文件与外部数据源的数据交换,以及执行混合数据源的计算:
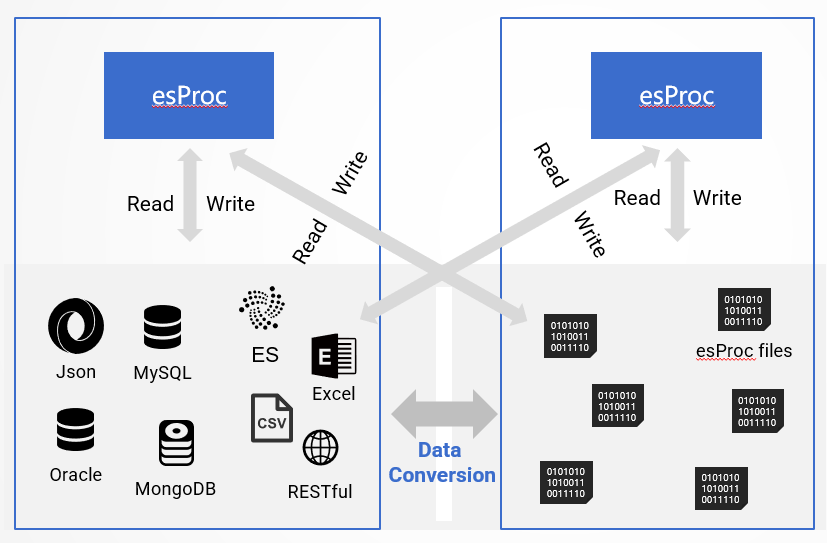
作为计算引擎,esProc SPL 并不像传统数据库那样“拥有”数据,所有可访问到的数据文件(或其它数据源)都可以被计算,都可以认为“属于”esProc。esProc 没有“库”的概念,数据也没有“库内”和“库外”的区分,当然也没有“入库”和“出库”的动作 此处无“仓”胜有“仓” 。
esProc SPL 可以被理解成是一个跑在文件系统上的数据仓库 跑在文件系统上的数据仓库 ,也是个非常轻量的大数据技术方案 轻量级的大数据处理技术 。基于 esProc 可以摒弃数据仓库,以更低成本更灵活的方式实现大数据计算。
非常特别地,SPL 代码写在格子里,这和通常写成文本的代码很不一样。独立的开发环境简洁易用,提供单步执行、设置断点、所见即所得的结果预览,调试开发也比传统数据库和 Java 更为方便。
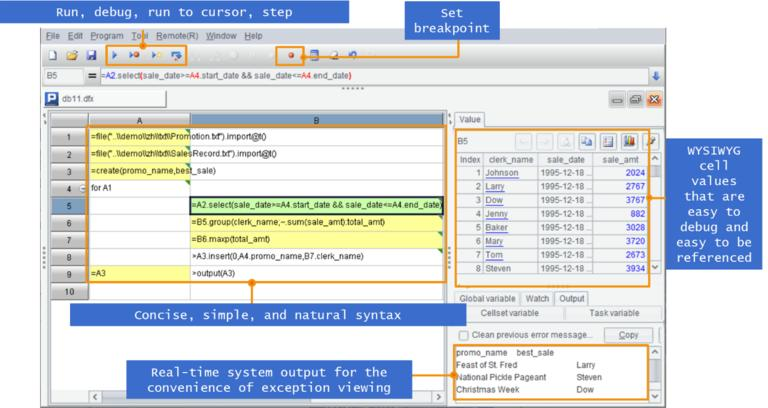
这里 写在格子里的程序语言 有对 SPL 有更详细的介绍。
最后,esProc 在这里 https://github.com/SPLWare/esProc 。


英文版