


此处无“仓”胜有“仓”
我们知道,早期数据库并不区分 TP 和 AP,所有任务都在一个数据库中完成。做 TP 业务时,要保证数据的一致性,而一致性要限定在一个范围内才有意义,这也就有了“库”的概念。数据入库是有门槛的,不符合约束的数据没法进来,数据在库内和库外有明显的区别,这个特性被称为封闭性。
封闭性除了保障数据一致性外,通过与数据库管理系统(DBMS)的配合还可以提供数据的安全性保障。
数据仓库是在数据库的基础上发展起来的,当数据库无法同时服务 OLTP 和 OLAP 业务时,将 AP 业务拆分到单独的数据库中就形成了数据仓库。数据仓库因此继承了数据库的很多特点,包括封闭性。继承了封闭性也就继承了“入库才能使用”“入库有门槛”等特点,顺便也就形成了数据仓库的“仓”的概念(house)。
那么这个封闭存储是必要的吗?
对 TP 业务是这样,但对以 AP 业务为主的数据仓库却未必。数据仓库虽然名字有“仓库”的字样,但实际它是一个以计算为主要作用的产品,即使可以像仓库一样能储存数据其实也是为计算服务的,毕竟数据只有使用(计算)才能发挥价值。现在市面上各类新型数据仓库 PK 的内容几乎全部是计算能力,特别是性能,还有计算完备性、函数丰富程度,但无一例外都是比拼计算能力。看来计算才是数据仓库的关键点,而不是存储。
如果主要目的是计算,是不是可以只提供丰富强大的计算引擎,不再绑定存储功能,也就是没有“仓”行不行?
对于大多数基于 SQL(关系代数)体系的数据仓库目前还不行,存储和计算绑定是数据库这个根子就要求的,改不了。
但新型无“仓”数据仓库—esProc SPL可以!
esProc 是一个开放的计算引擎,专门用于 AP 业务的数据处理。esProc 具备开放的计算能力,支持多种数据源连接,还可以进行多数据源混合计算。同时,esProc 还提供了自有的高性能文件存储保证计算性能。esProc 没有采用 SQL 作为形式化语言,而是使用了独创的 SPL(Structured Process Language)语言,相对 SQL 也更有优势。
这里所谓的无“仓”是指不会像传统数据仓库一样提供封闭自有的存储功能。
那数据放在哪呢?
我们下面来仔细回答这个问题以及相关的问题,同时看看无“仓”还能带来的更多好处(也就是克服有“仓”会带来问题)。
实时多样性数据源
其实,数据一旦产生就会存放在某个承载它的介质中,或数据库、或文件、或 WEB,从广义上来讲数据已经存储好了。既然已经存好了,那直接用不就可以?而且现在企业的数据源种类很多,经常会面对五花八门的数据来源和类型,这些数据源如果能够直接使用将非常方便。
esProc 直接提供了这种开放的多数据源支持能力。无论数据分布在哪里(RDB、NoSQL、File、Hadoop、RESTful 等),esProc 都可以直接读取计算。更重要的是,还可以针对数据源进行连接混合计算。

支持多样数据源(混算)以后,就突破“仓”的限制,不仅可以节约“入库”带来的开发与时间成本,多源实时计算还可以充分保证数据的实时性,继而实现数据分库后的 T+0 查询。同时,数据不再无脑入库,数据库的存储成本和压力也将大大降低,这在 esProc 应用初期(数据仓库与 esProc 并存)也很重要。
esProc 还可以充分保留各类数据源的优点,RDB 的计算能力较强,在很多场景下就可以让 RDB 先完成一部分计算后再由 esProc 接管;NoSQL 和文件的 IO 传输效率高 esProc 就可以直接读取计算;MongoDB 支持多层数据存储,esProc 直接使用会很方便…… 这些都是开放性带来的好处。
相比之下,封闭的数据仓库不能针对库外的数据开放其计算能力,就只能把外部数据先导入才能计算。这会增加一步 ETL 动作,增大工作量并加大数据库负担的同时,还丧失了数据的实时性。这些外部数据的格式常常不规范,导入进有强约束的数据库并不是一件很容易的事。而且,即使做 ETL 也要先把未整理的数据先入库才能利用数据仓库的计算能力,结果把 ETL 做成 ELT,加大数据仓库负担。
数据分布在哪里都能算,这是无“仓”esProc 的好处之一。
高性能
不过,esProc 对接多样性数据源时,虽然各类数据源在逻辑上是等同的,但由于各类数据源提供的接口访问效率不同,会导致读取性能(会反映到总计算时间上)差异,有的往往还很低(如 RDB 的 JDBC)。
开放的多样性数据源支持虽然方便,但性能可能很差怎么办?
为了保障计算性能,esProc 提供了专门的二进制文件存储格式,提供了压缩、列存、有序、并行分段等机制来充分保证计算性能。
值得注意的是,esProc 提供的文件存储并非封闭在 esProc 内部(与数据仓库封闭存储完全不同),而是存放在文件系统下的文件,与其他文本、Excel 等文件地位是等同的,esProc 并不拥有这些文件,只是内部做了很多优化策略,访问效率更高。
相比之下,有“仓”的数据仓库性能往往不高。我们知道,数据仓库的计算效率取决于优化引擎的优化程度,好的数据库会根据 SQL 的计算目标(而非字面意思)选择更高效的执行方式。但这种自动优化机制仅对简单的情况下有效,一旦 SQL 变得稍复杂优化引擎就不起作用了,只能根据 SQL 的字面表达去执行,结果性能陡降。这时,如果能干预数据存储,将数据根据算法调整(如按主键有序)就可以获得更高性能。但数据仓库是封闭的,存储是私有的,我们无法干预也就没法获得高性能了。
esProc 提供的文件存储就很灵活了,可以根据任意算法来设计存储,既可以利用文件存储本身的优势,又可以根据算法调整,跑出高性能也就不奇怪了。
安全性与可靠性
开放能力以及使用文件存储又会带来一个问题,原来传统数据仓库的封闭性可以在体系内提供安全与可靠性保障,不再绑定存储的 esProc 如何解决这两个问题呢?
其实这个问题大可不必担心。原则上 esProc 并不管理数据,也不对数据的安全负责。一定程度上可以说,esProc 没有也没必要有安全机制。
持久化数据的安全性原则上数据源本身负责,如数据库提供的用户标识和鉴定、授权和检查机制、审计技术等安全机制。对于 esProc 格式的数据文件,很多文件系统或 VM 都提供了完善的安全机可以直接利用,如访问控制、身份验证、传输加密等机制。数据的可靠性也都可以借助数据源或专业存储技术自身的能力保障。
esProc 也支持从 S3 等对象存储服务上获取数据再计算,也可以利用它们的安全机制。而 S3 这些云存储技术在安全和可靠性方面更有优势,现在基本没有什么数据库提供的可靠性保障能超过 S3 这些专业技术了。所以,直接使用就好。
在应用访问方面,独立服务进程的 esProc 使用标准的 TCP/IP 和 HTTP 通信,可以被专业的网络安全产品监控和管理,具体安全措施也将由这些产品负责。esProc 专门用于数据计算,在非计算方面的理念是与其他专业产品配合。

其实,有“仓”时安全和可靠性反而会更差。数据库的权限管控往往不够细致,结果应用都是高权限用户,为了方便“算”而给了干预“存”的权限,比如编译存储过程这样的危险权限,安全性本身就得不到很好保障。而 esProc 不管“存”只管“算”,“算”只会在“存”的安全机制上工作,不会影响破坏它。可靠性则完全跟投入的成本成正比,即使采用成本极高的“两地三中心”建设,与现在专业的云存储比起来仍然还差很多。既然如此,那就把专业的事交给专业的人来做好了。
无“仓”可以比有“仓”更安全、更可靠。
实现 HTAP 需求
HTAP 近些年也是数据库的热点,但大多数产品在实现时仅仅在 TP 数据库的基础上附上一定的 AP 能力,或者通过其他方式将二者包装在一起。无论采用何种方式都会面临数据库迁移问题风险很大不说,原来数据仓库的封闭性和性能问题也解决不了。
其实 HTAP 的本质需求是分库后的 T+0 查询。如果能提供这种能力,原来的 TP 库可以不动(没有迁移风险)就能满足 HTAP 需求。
我们可以在原有独立 TP 和 AP 体系的基础上引入 esProc,借助其开放的跨源计算能力、高性能存储和计算能力、敏捷开发能力来实现 HTAP。
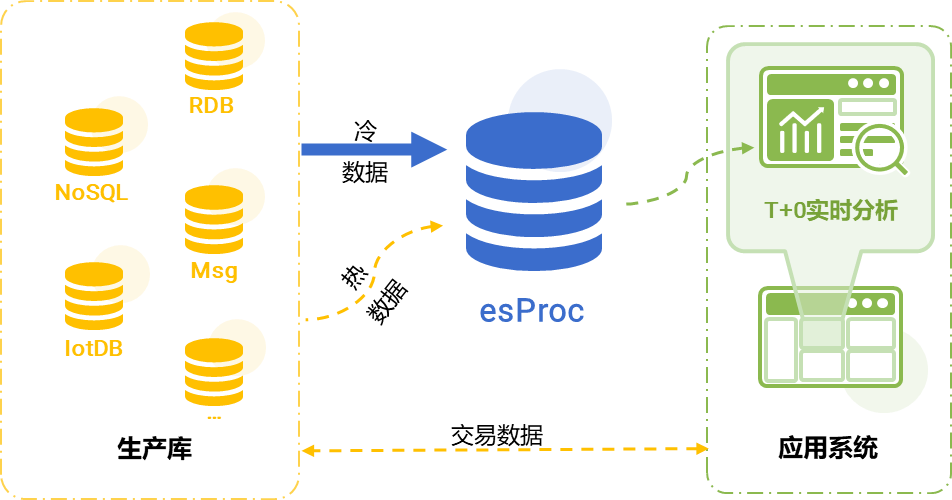
esProc 通过与现有系统融合的方式实现 HTAP,这样原有系统的改动很小,TP 部分几乎不动,甚至原有的 AP 数据源也可以继续工作,逐步使用 esProc 接管 AP 业务。esProc 部分或全部接管 AP 业务后,历史冷数据使用高性能文件存储,原来针对业务库到数据仓库的 ETL 过程可以直接移植到 esProc 上。冷数据量大且不再变化使用 esProc 高性能文件存储可以获得更高地计算性能;热数据量小仍然存放在原有 TP 数据源中,SPL 直接读取计算,由于热数据量并不大,直接基于 TP 数据源查询也不会对其造成太大影响,访问时间也不会太长。再利用 esProc 的冷热数据混合计算能力,就可以获得针对全量数据的 T+0 实时查询。我们只要定期将变冷的数据固化到 esProc 的高性能存储中,原数据源只需要保持少量近期新产生的热数据即可。这样不仅实现了 HTAP,而且还是高性能的 HTAP,且对应用架构冲击很小。
真正的湖仓一体
封闭的数据仓库构建不了真正的湖仓一体。数据湖应该像个垃圾场,不管什么数据先原汁原味地保存下来再说,没法预测某些数据将来是不是有用。数据的价值要通过计算才能产生,这就要借助数据仓库的计算能力。但数据仓库是封闭的,数据必须经过深度整理符合约束后才能入库,数据湖中大量的原始“垃圾”无法直接被计算,而整理数据局不仅意味着原始信息丢失,而且还会面临前面多样性数据源的问题,不仅数据的实时性无法保障,ETL 本身也要花费大量成本,时效性很差。
相对传统数据仓库实现的伪湖仓一体,esProc 由于具备足够的开放性,可以直接计算数据湖上未经整理的数据,也可以基于多种不同类型的数据源混合计算,同时借助高性能机制保证计算效率,因此可以实现真正的湖仓一体。
esProc 针对数据湖的原始数据直接计算,没有约束,无需入库。同时还提供了多样性数据源混合计算的能力,无论数据湖使用统一文件系统构建,还是基于多样性数据源(RDB、NoSQL、LocalFile、Webservice)使用 SPL 都可以直接混合计算,快速输出数据湖价值。此外,还可以使用 esProc 提供的高性能文件存储(数仓的存储功能),在 SPL 实施计算的同时,整理数据可以从容不迫地进行,将原始数据整理到 esProc 存储中可以获得更高性能。使用 esProc 存储整理后数据仍然存放在文件系统中,理论上可以与数据湖存放一处,这样就实现了真正意义的湖仓一体。
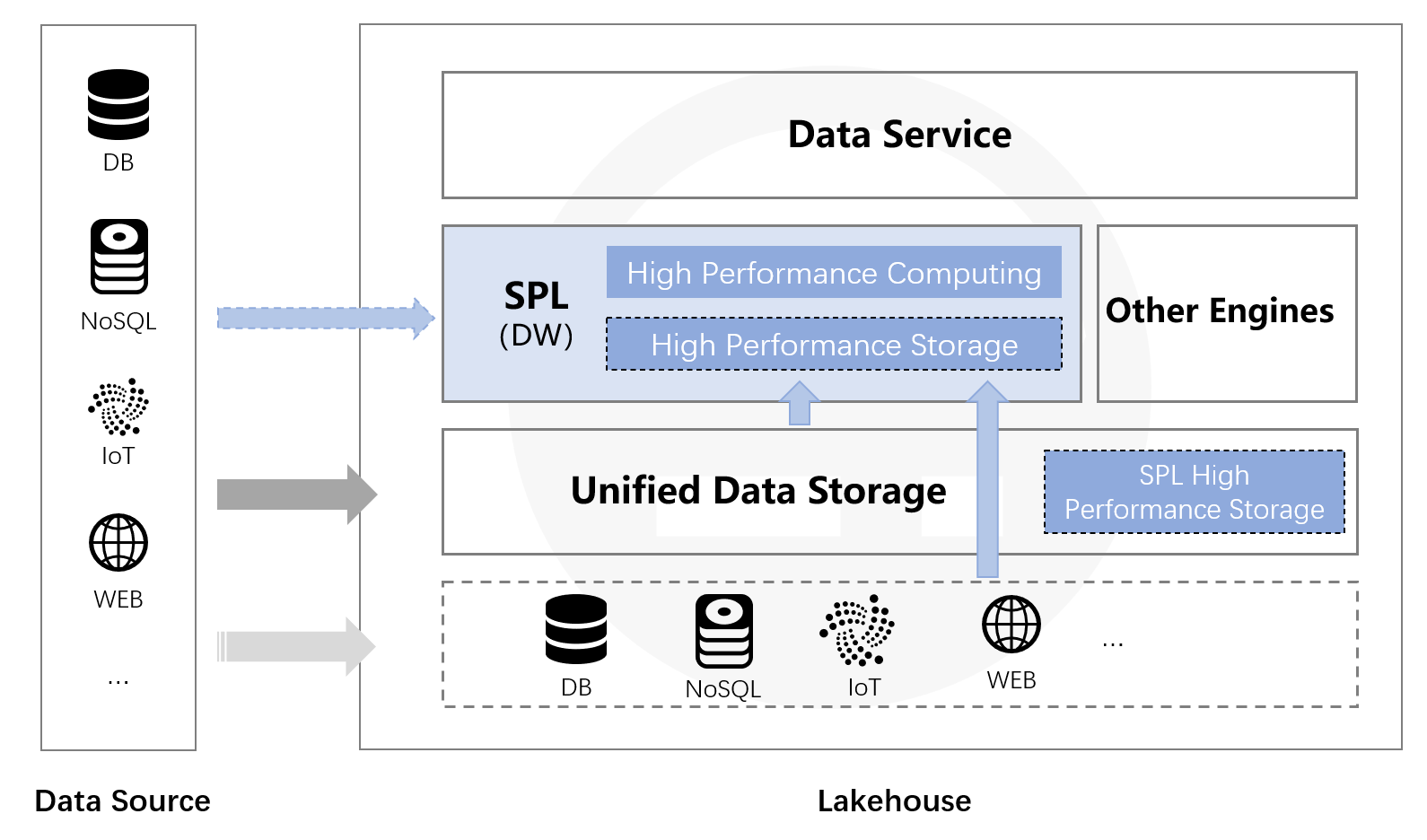
在 SPL 计算能力的支持下数据整理与数据使用可以同时进行,循序渐进地建设数据湖,逐步整理,有序建设。还在建设数据湖的过程中就完善了数据仓库,让数据湖也拥有强计算能力,这才是真正的湖仓一体。
从封闭到开放,这是技术在不断进步的表现,数据仓库自然也不能独善其身,有“仓”到无“仓”这是数据仓库演进的必然阶段,数据仓库也即将迎来无仓时代。esProc 或许并不完美,但在开放无仓的数据仓库能力上已经迈出了一大步,十分值得一试。


英文版