


写在格子里的程序语言
What?写在格子里的程序语言?!
是的!你没看错,写在格子里的程序语言 SPL(Structured Process Language),专门用于结构化数据处理。
我们知道,几乎所有编程语言都是写成文本的,那写在格子里的 SPL 是什么样子呢?写在格子里的代码又有哪些不同呢?我们先一睹 SPL 的编程环境。
格子里的代码
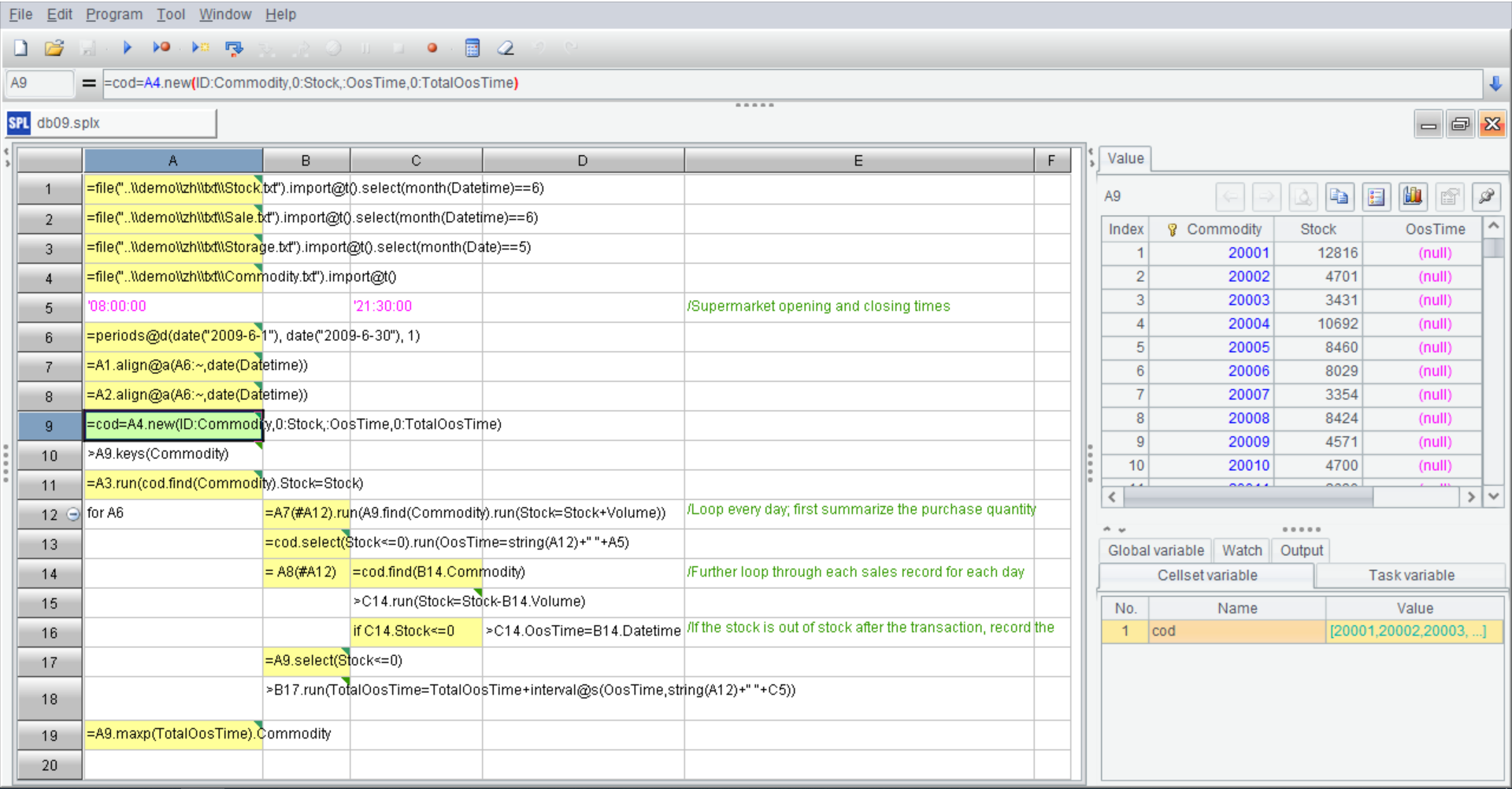
中间部分就是 SPL 的网格代码了。
把代码写到格子里有什么好处呢?
我们编程时总要用到中间变量,也就要给变量起个名字,但在 SPL 中经常是不需要滴。后面步骤中可以直接使用前面单元格名(如 A1)以引用该格的计算结果,如:=A2.align@a(A6:~,date(Datetime)),这样可以避免绞尽脑汁地定义变量(要知道变量命名经常要起得有意义,也挺烦);当然 SPL 也支持定义变量,无需定义变量类型,随起随用,如:=cod=A4.new(ID:Commodity,0:Stock,:OosTime,0:TotalOosTime),也可以在表达式中临时定义变量并使用,如:= A1.group@o(a+=if(x,1,0))。
使用格子名作为变量名会有一个问题,插入或删除行列后格子的名称(位置)会变化,再使用原来的名称就不对了。别担心,这点 SPL IDE 早就考虑到了,插入删除行后格子名称会自动变迁。你看我插入了一行,下面的格子名就变了,方不方便?
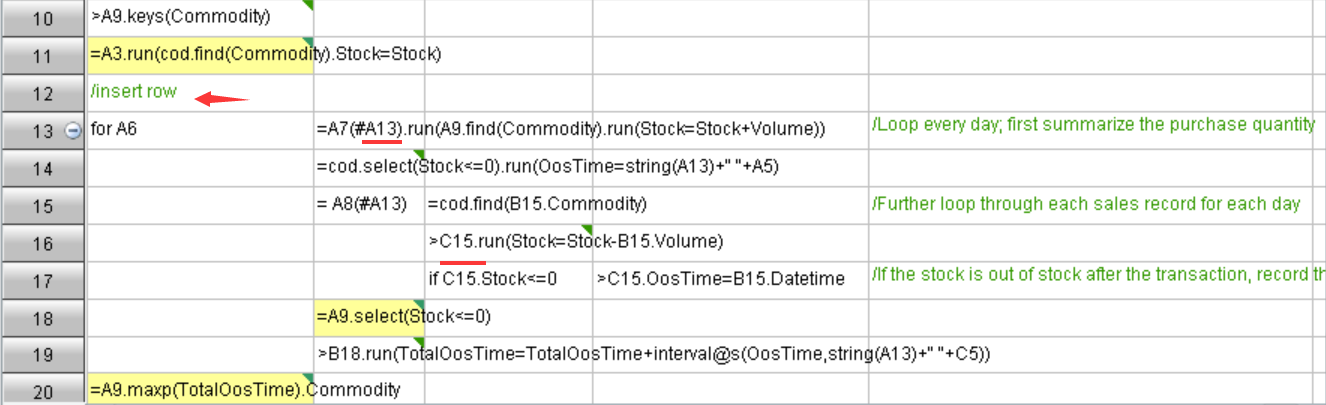
格子代码给人的感觉会非常规整,因为格子的原因,代码天然对齐。其中,代码块的标识采用了格子缩进的方式(A12 到 A18 的 for 循环),不需要使用任何修饰符,十分整齐直观。而且,当某格处理细碎任务的代码很长时,代码也只会占一个格子,不影响阅读整个代码的结构(不会让某个格子里太长的代码写出格子而影响到右边和下边的代码阅读)。相比之下文本代码就得全显示出来而没有这个好处了。
另外我们注意到,在 for 循环所在的行上还有折叠按钮可以收缩整个代码块,这个功能很多文本编程 IDE 也都提供,但作用在网格编程上会让代码更加齐整易读。

再有就是调试功能了。我们继续看一下这个编程环境,除了中间的代码区以外,上方工具栏提供了多种执行 / 调试按钮,执行、调试执行、执行到光标、单步执行,后面还有设置断点、计算当前格等功能,可以完全满足编辑调试程序的需要。每次一格,代码定位很清楚,不像文本式的代码同一行可能有多个动作不容易区分,有些句子太长时变成多行也不容易定位。

右侧还有一个结果面板也值得重点关注,由于 SPL 采用了网格式编程,在执行 / 调试后每步(格)的结果都被保留下来,程序员点击某个格子就可以实时查看该步(格)的计算结果,计算正确与否一目了然。不需要手动输出,每步结果实时查看,这进一步增强了调试的便利性。
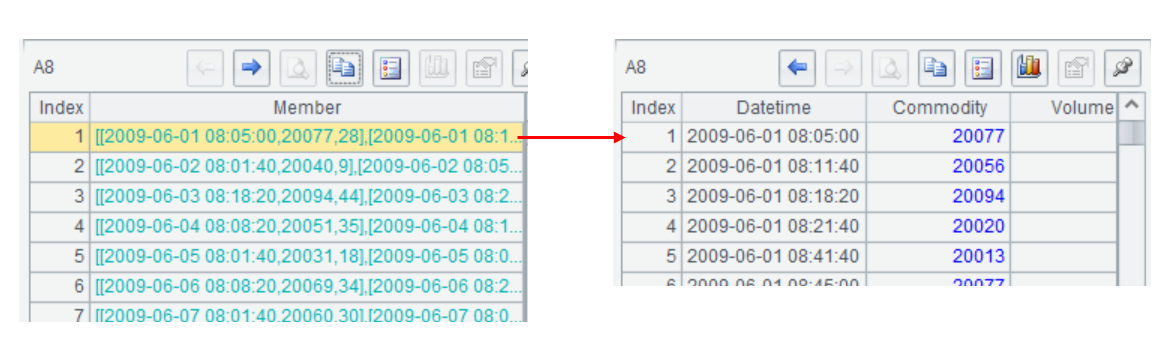
多层结果集
并不只是格子
代码写到格子会有编辑调试等方便之处,但并不会简化每句代码的书写。让我们回到 SPL 语法本身。
我们处理数据尤其是复杂场景一定会用到循环、分支,这是一个编程语言比较基础的部分,SPL 自然提供。除此以外,SPL 还有很多独有的特色,比如选项语法、多层参数以及进阶的 Lambda 语法。
函数选项
每种编程语言都会内置大量的库函数,库函数越丰富我们在功能实现上就越方便。函数会采用不同的名称或参数(以及参数类型)进行区分,但有时通过参数类型也无法区分时就要显示地再增加选项参数,以便告诉编译器或解释器你要实现的功能。比如 Java 在操作文件时有多个 OpenOption,当我们想要创建一个不存在的文件可以使用:
Files.write(path, DUMMY_TEXT.getBytes(), StandardOpenOption.CREATE_NEW);
但如果文件存在时打开,不存在时新建则需要使用:
Files.write(path, DUMMY_TEXT.getBytes(), StandardOpenOption.CREATE);
而向文件追加数据并保证系统崩溃时数据不会丢失需要使用:
Files.write(path,ANOTHER_DUMMY_TEXT.getBytes(), StandardOpenOption.APPEND, StandardOpenOption.WRITE, StandardOpenOption.SYNC)
同一个函数实现不同功能需要用选项来控制,通常也就是把选项作为一个参数,这会造成了使用上的复杂度,经常搞不清这些参数的真实用途,对于某些参数数量不确定的函数还没有办法再用参数来表示选项了。
SPL 提供了非常独特的函数选项,使功能相似的函数可以共用一个函数名,然后函数选项区分差别,做到了把函数选项落到实处,在表现上更趋近一种二层结构,这样不管记忆还是使用都很方便。比如,pos 函数的功能是查找母串中子串的位置,如果从后往前查找可以使用选项 @z:
pos@z("abcdeffdef","def")
忽略带小写还可以使用 @c 选项:
pos@c("abcdef","Def")
两个选项还可以组合使用
pos@zc("abcdeffdef","Def")
有了函数选项,我们只需要熟悉更少的函数即可,当使用到同类但不同功能时再查找相应选项即可,相当于 SPL 给函数也做了层级划分,查找和使用更加方便。
层次参数
有些函数的参数很复杂,可能会分成多层。常规程序语言对此并没有特别的语法方案,只能生成多层结构数据对象再传入,非常麻烦。比如我们使用 Java 做 join 运算(对 Orders 表和 Employee 表进行内关联):
Map<Integer, Employee> EIds = Employees.collect(Collectors.toMap(Employee::EId, Function.identity()));
record OrderRelation(int OrderID, String Client, Employee SellerId, double Amount, Date OrderDate){}
Stream<OrderRelation> ORS=Orders.map(r -> {
Employee e=EIds.get(r.SellerId);
OrderRelation or=new OrderRelation(r.OrderID,r.Client,e,r.Amount,r.OrderDate);
return or;
}).filter(e->e.SellerId!=null);
可以看到实现关联计算时需要给 Map 传递一个多层(段)的参数,即使是读起来也很费劲,就更别提写了。我们再做多一点计算,因为关联完往往还会有其他计算,这里再对 Employee.Dept 进行分组,对 Orders.Amount 求和:
Map<String, DoubleSummaryStatistics> c=ORS.collect(Collectors.groupingBy(r->r.SellerId.Dept,Collectors.summarizingDouble(r->r.Amount)));
for(String dept:c.keySet()){
DoubleSummaryStatistics r =c.get(dept);
System.out.println("group(dept):"+dept+" sum(Amount):"+r.getSum());
}
这种函数的使用复杂度相信不用再多解释了,小伙伴们都有很深体会。相比之下,SQL 就直观简单多了。
select Dept,sum(Amount) from Orders r inner join Employee e on r.SellerId=e. SellerId group by Dept
SQL 使用了一些关键字(from、join 等)将计算的各个部分进行了分隔,分隔的各个部分也可以理解成多层参数,只不过伪装成英语会有更好的易读性。但这种做法的通用性差很多,要为每个语句选择专门的关键字,会使语句结构不统一。
SPL 没有采用 SQL 这种使用关键字进行分隔的方式,也没有像 Java 一样需要嵌套多层,而是创造性地发明了层次参数。约定支持三层参数,分别用分号、逗号和冒号来分隔。分号是第一级,分号隔开的参数是一组,这个组内如果还有下一层参数则用逗号分隔,再下一层参数则用冒号分隔。前面的关联计算用 SPL 来写是这样:
join(Orders:o,SellerId ; Employees:e,EId).groups(e.Dept;sum(o.Amount))
简单明了,没有嵌套,也不会出现语句结构不统一的情况。实践表明,三层基本够用了,很少用这种写法还无法描述清楚的参数关系了。
增强 Lambda 语法
我们知道,Lambda 语法可以简化编码,一些编程语言已经开始支持。比如 Java8 以后统计空字符串数量可以这样来写:
List<String>strings = Arrays.asList("abc", "", "bc", "efg", "abcd","", "jkl");
long count = strings.stream().filter(string -> string.isEmpty()).count();
这种“(参数)-> 函数体 " 的 Lambda 表达式可以简化匿名函数的定义,使用时很简洁。
不过,完成一些稍微复杂计算就要长一些了,比如基于两个字段的分组汇总:
Calendar cal=Calendar.getInstance();
Map<Object, DoubleSummaryStatistics> c=Orders.collect(Collectors.groupingBy(
r->{
cal.setTime(r.OrderDate);
return cal.get(Calendar.YEAR)+"_"+r.SellerId;
},
Collectors.summarizingDouble(r->{
return r.Amount;
})
)
);
for(Object sellerid:c.keySet()){
DoubleSummaryStatistics r =c.get(sellerid);
String year_sellerid[]=((String)sellerid).split("_");
System.out.println("group is (year):"+year_sellerid[0\]+"\t (sellerid):"+year_sellerid[1]+"\t sum is:"+r.getSum()+"\t count is:"+r.getCount());
}
上面代码中,所有出现字段名的地方,都要先写上表名,即 "表名. 字段名",而不能省略表名。匿名函数语法复杂,随着代码量的增加,复杂度迅速增长。两个匿名函数形成嵌套,代码更难解读。实现一个分组汇总功能要用多个函数和类,包括 groupingBy、collect、Collectors、summarizingDouble、DoubleSummaryStatistics 等,复杂程度很高。
SPL 也提供了 Lambda 语法,并且相对 Java 这些语言的支持更加彻底,上面的例子用 SPL 来写。
计算空串数量:
=["abc", "", "bc", "efg", "abcd","", "jkl"].count(~=="")
SPL 直接把 A.(x).count()简化成 A.count(x),使用起来更加方便。不过看起来与 Java 相差似乎并不大,我们再来看分组汇总的实现:
=Orders.groups(year(OrderDate),Client; sum(Amount),count(1))
看出区别了吗?SPL 对双字段进行分组或汇总时,也不需要事先定义数据结构。整体代码没有多余的函数,sum 和 count 用法简洁易懂,甚至很难觉察这是嵌套的匿名函数。
我们再来看个例子:
集合中存储了某公司 1 到 12 月的销售额,我们可以做下面这样的计算:
A |
|
1 |
=[820,459,636,639,873,839,139,334,242,145,603,932] |
2 |
=A1.select(#%2==0) |
3 |
=A1.(if(#>1,~-~[-1],0)) |
A2 是筛选偶数月份的数据,A3 则计算每月销售额的增长值。
这里例子中使用了 #和 [-1] 这样的写法,前者表示当前序号,后者则是在引用上一个成员,同理如果想比较下一个成员则可以使用 [1] 的写法。再加上前面用到的 ~(当前成员)符号,这些都是 SPL 在强化 Lambda 语法上提供的比较特殊的方面。有了这些符号,不需要再增加参数定义就可以完成所有计算,描述能力变强了,书写上和理解上也更简单。
函数选项、多层参数、增强的 Lambda 语法是 SPL 与众不同的另一方面。
比肩 SQL 的结构化数据计算能力
SPL 的网格编码和代码特色(函数语法、多层参数、Lambda 语法),这些特点让 SPL 看起来很好玩。但发明 SPL 并不是为了好玩,SPL 的目标是高效处理数据,为此 SPL 提供了专业的结构化数据对象序表(记录),并在序表的基础上提供了丰富的计算类库。SPL 支持动态数据结构,这使得 SPL 与 SQL 一样,具备了完善的结构化数据处理能力。
相比之下,Java 作为编译型语言由于缺少必要的结构化数据对象使得数据计算十分繁琐,不支持动态数据结构无法完成在计算过程中动态生成而必须事先定义,即使在 Stream 出现以后仍然改善不大,这都是由于缺少来自 Java 底层的支持导致的。
SPL 提供了十分丰富的计算函数,可以很方便地完成结构化数据计算。包括但不限于:
=Orders.sort(Amount) // 排序
=Orders.select(Amount*Quantity>3000 && like(Client,"*S*")) // 过滤
=Orders.groups(Client; sum(Amount)) // 分组
=Orders.id(Client) // 去重
=join(Orders:o,SellerId ; Employees:e,EId) // 连接
再比如双字段排序:
A |
|
1 |
=file("Orders.txt").import@t() |
2 |
=A1.sort(-Client, Amount) |
上面的 @t 表示首行读为字段名,后续可以脱离数据对象,直接用字段名进行计算,其中 -Client 表示逆序。
不影响阅读的情况下,代码也可以写在一行,这样更加简短:
=file("Orders.txt").import@t().sort(-Client, Amount)
我们再回忆上一节的例子,Java 在实现双字段分组汇总时需要写嵌套两层的冗长代码,这会增加学习和使用成本。而同样的计算 SPL 像 SQL 一样,无论是单字段还多字段分组,写法都一样:
=Orders.groups(year(OrderDate),Client; sum(Amount))
类似地,内连接计算(再汇总),SPL 相对其他高级语言代码也简单多了:
=join(Orders:o,SellerId ; Employees:e,EId).groups(e.Dept; sum(o.Amount))
类似 SQL,只需稍作改动就可以切换关联类型,而无需改动其他代码,比如 join@1 表示左连接,join@f 表示全连接。
具备丰富的数据对象及类库以后,SPL 不仅拥有了类似 SQL 的数据处理能力,而且还能继承高级语言的一些优良特性(如过程化),使得 SPL 处理数据很方便。
超越 SQL
前面的内容从好玩的格子编程到选项语法等特性,再到完善的结构化数据对象和类库,这些看起来 SPL 提供了类似 SQL 的结构化数据处理能力,让程序员在没有数据库的时候也能做很多结构化数据处理和计算。
那么 SPL 就是一个不用数据库的“SQL”吗?
并不是!SPL 并没有止步于此,事实上,对于结构化数据,SPL 还有很多强于 SQL 的地方。
其实我们在实际业务中,我们经常发现很多 SQL 并不好写,嵌套 N 层、长达上千行的情况随处可见,这种 SQL 不仅难写,想修改维护也不容易,可谓又长又臭。
为什么会出现这种情况?
这是由于 SQL 对某些特性支持不够甚至根本不支持导致的。这里我们具体来看几个例子,并对比一下 SPL 的解决方式。
有序计算
根据股票交易记录表计算:某支股票最长连续涨了多少交易日
SQL 的写法:
select max(continuousDays)-1
from (select count(*) continuousDays
from (select sum(changeSign) over(order by tradeDate) unRiseDays
from (select tradeDate,
case when closePrice>lag(closePrice) over(order by tradeDate)
then 0 else 1 end changeSign
from stock) )
group by unRiseDays)
这句 SQL 嵌套了 3 层,先通过窗口函数制造涨跌标记(注意上涨记为 0, 不涨标记为 1),再按照日期做累加就得到了上涨标记相同的区间(不涨则数值不同),然后按照标记分组计数求最大值就得到了最长连续上涨天数。
感觉怎么样,是不是很绕?看懂是不是都得一会?这还不是很复杂的情况,写 / 看起来就如此费劲。这是因为 SQL 的集合是无序的,无法通过序号(或相对位置)访问成员,也没有有序分组运算,虽然一些数据库支持窗口函数可以在一定程度上支持序运算,但还远远不够(比如这个例子)。
其实这个计算按照日期排序后只需要比较和上一天的价格(序运算),上涨就加 1,否则就清 0,最后求一个最大值就行了。
SPL 直接提供了有序的支持,天然支持序运算,这样就可以按照自然思路写出代码:
A |
|
1 |
=stock.sort(tradeDate) |
2 |
=0 |
3 |
=A1.max(A2=if(closePrice>closePrice[-1],A2+1,0)) |
在有序计算和过程化(Java 的优点)的支持下表达起来很简洁,好写又好懂。
上面 SQL 思路的解法用 SPL 写也更简单:
stock.sort(trade_date).group@i(close_price<close_price [-1]).max(~.len())
仍然利用有序的特性,符合条件(不涨)时就会产生新的分组,这样就能将每个上涨区间分别分到不同组,最后计算最大分组成员数就可以了。与 SQL 思路虽然一致,但表达的简洁程度却完全不同了。
分组理解
根据用户登录表,列出每个用户最近一次登录间隔。
SQL 写法:
WITH TT AS
(SELECT RANK() OVER(PARTITION BY uid ORDER BY logtime DESC) rk, T.* FROM t_loginT)
SELECT uid,(SELECT TT.logtime FROM TT where TT.uid=TTT.uid and TT.rk=1)
-(SELET TT.logtim FROM TT WHERE TT.uid=TTT.uid and TT.rk=2) interval
FROM t_login TTT GROUP BY uid
这里需要根据用户最近两次登录记录计算登录间隔,本质上是组内 TOPN 的问题,但 SQL 分组之后强制聚合,所以要采用自关联的方式变相实现。
我们再来看一下 SPL 的写法:
A |
||
1 |
=t_login.groups(uid;top(2,-logtime)) |
最后2个登录记录 |
2 |
=A1.new(uid,#2(1).logtime-#2(2).logtime:interval) |
计算间隔 |
SPL 对聚合运算有新的理解,聚合结果除了常见的单值 SUM、COUNT、MAX、MIN 等之外,也可以是个集合。比如常常出现的 TOPN 计算,SPL 也看作和 SUM、COUNT 一样的聚合计算,既可以针对全集也可以针对分组子集(如本例)。
SQL 没有把 TOPN 运算看成是聚合,针对全集的 TOPN 只能在输出结果集时排序后取前 N 条,而针对分组子集则很难做到 TOPN,需要转变思路拼出序号才能完成。SPL 把 TOPN 理解成聚合运算后,再结合有序特性就很容易实现诸如本例中的计算,而且这种方式在工程实现时还可以避免全量数据的排序,获得更高性能。
更进一步,SPL 的分组不仅可以聚合,还能保留分组结果(分组子集),即集合的集合,从而能进行分组成员间的运算。
与 SPL 相比,SQL 没有显式的集合数据类型,无法返回集合的集合这类数据,不能实现独立的分组,就只能强迫分组和聚合作为一个整体来计算了。
通过这两个例子我们可以看到 SPL 在有序和分组计算上的优势。其实 SPL 还有很多特性都是建立在结构化数据处理的深刻理解上,离散性可以让构成数据表的记录游离于数据表外独立反复使用;普遍集合支持任何数据构成的集合并参与运算;连接运算区分了三种不同连接类型可以因材施教;而游标的支持让 SPL 拥有了大数据处理能力;……。有了这些特性以后,我们再处理数据就会更加简单、高效。
更多参考: 新手如何理解 SPL 运算
竟然还是数据仓库
SPL 同时支持内外存两种类型的计算意味着 SPL 也可以用于大数据处理,并且相对传统技术的性能更高。SPL 提供了几十种“更低复杂度”的高性能算法来保证计算性能,包括:
内存计算类的二分法、序号定位、位置索引、哈希索引、多层序号定位、……
外存查找类的二分法、哈希索引、排序索引、带值索引、全文检索、……
遍历计算类的延迟游标、遍历复用、多路并行游标、有序分组汇总、序号分组、……
外键关联类的外键地址化、外键序号化、索引复用、对位序列、单边分堆、……
归并与连接类的有序归并、分段归并、关联定位、附表、……
多维分析类的部分预汇总、时间段预汇总、冗余排序、布尔维序列、标签位维度、……
集群计算类的集群复组表、复写维表、分段维表、冗余与备胎容错、负载均衡、……

可以看到 SPL 提供了非常多的算法(有很多还是业界首创),针对不同的计算场景都有对应的机制保障,作为编程语言提供了数据库才有的能力,而且更加丰富,足以保证计算性能。
除了这些算法(函数),还要提到存储,有些高性能算法必须将数据存储成指定形式才能实施,比如上面提到的单边分堆、有序归并都要求数据有序才能使用。SPL 为了保障计算性能设计了专门的二进制文件存储,采用压缩编码、列存以及并行分段等存储机制,再利用有序、索引等方法,就可以最大限度发挥高性能算法的效力,从而实现更高计算性能。
有了计算和存储后,SPL 就拥有了数据仓库的全部关键能力,以更低成本更高效率来替代传统关系型数据仓库以及 Hadoop 等大数据平台就毫无压力了。
在实际应用中,SPL 用作数据仓库时也的确也表现出与传统方案不一样的效果。比如,在某电商漏斗分析场景中 SPL 在使用更差硬件的情况下比 Snowflake 快了近 20 倍,而在国家天文台星体聚类计算场景下使用单台服务器比某头部分布式数据库的集群还快了 2000 倍。类似的场景还有很多,基本上能够提速几倍到几十倍,性能表现十分突出。
总结一下,SPL 作为专门的数据处理语言采用了十分“另类”的网格编程方式,这会带来诸如格式、调试等方便的便利(当然习惯文本编程的同学要适应一下),而且在语法方面还加入了选项、多层参数、Lambda 语法等新特性,这让 SPL 看起来很有趣,但这些特性实则都在为数据计算服务,这源于 SPL 对结构化数据计算的深层理解(相对 SQL 更深入更完善)。有了这些理解才产生了这些“好玩”的特性,有了这些特性让数据处理更加简单方便,而且更快。更简单、更快是 SPL 要实现的目标,在这个过程中还会带来应用结构的改善(这里不再细说)。
总之,SPL 是一个非常值得一试的编程语言。

