


客群标签自动贴
客户信息标签化,即客户画像,是指通过收集客户的社会属性、消费习惯、偏好特征等各个维度的数据,进而对客户或者产品特征属性进行刻画,并对这些特征进行分析、统计,挖掘潜在价值信息,从而抽象出客户的信息全貌。
从对客户打标签的方式来看,一般分为3 种类型:①统计类标签;②规则类标签;③机器学习挖掘类标签(预测标签)。
1. 统计类标签
这类标签是最为基础也最为常见的标签类型,例如,对于某个客户来说,其性别、年龄、城市、星座、近7 日活跃时长、近 7 日活跃天数、近 7 日活跃次数等字段可以从客户注册数据、客户访问、消费数据中统计得出。该类标签构成了客户画像的基础。
2. 规则类标签
该类标签基于客户行为及确定的规则产生。例如,对平台上“消费活跃”客户这一口径的定义为“近 30 天交易次数≥2”。在实际开发画像的过程中,由于运营人员对业务更为熟悉,而数据人员对数据的结构、分布、特征更为熟悉,因此规则类标签的规则由运营人员和数据人员共同协商确定;
3. 机器学习挖掘类标签(预测标签)
该类标签通过机器学习挖掘产生,用于对客户的某些属性或某些行为进行预测判断。例如,根据一个客户的行为习惯判断该客户是男性还是女性、根据一个客户的消费习惯判断其对某商品的偏好程度。该类标签需要通过算法挖掘产生。
在实际工程中,一般统计类和规则类的标签较多,而机器学习标签由于开发周期较长,开发成本较高,因此开发所占比例较小。但随着流量红利的结束,企业和商家也从获客时代逐渐转向了拼服务的时代。如何通过对客户进行更精细化的管理,精准的服务,进而增加客户粘性,产生更多价值已成为新的发力点。很多场景简单的统计和规则产生的标签已不能满足需求,需要更精准的预测。例如,客户对价格的敏感程度,对颜色的偏好,对运动的喜好,以及该客户是文青屌丝、专家小白又或是IT 宅男,爱美宝妈。再比如还可以通过预测客户对种商品的购买意向、复购意向等,然后贴上不同的标签,实现对不同层次的客户进行不同方式的管理和营销;风控领域中,预测客户的风险等级,从而实现更精准的风险控制。总之随着精细管理和服务的需求,数据挖掘类标签发挥着越来越多的作用。
如上文所提,数据挖掘类标签由于开发成本高,周期长,难以得到普及。这是因为首先数据挖掘用到的算法原理,参数等都比较难,需要有数据科学家的参与,而数据科学家又少又贵;同时,建立一个数据挖掘的模型并不是一蹴而就的,需要数据专家根据自己的知识和经验反复的调试,一个模型少则几周多则数月。更别说模型是有生命周期的,数据变了还要重新开发模型。而在很多商业场景中,商品的销售是有窗口期的,比如夏季冷饮的销售就是短短的一两个月,等模型好不容易部署上线估计夏天已经快过去了。等到第二年消费模式发生变化,去年流行雪糕刺客,今年流行平价雪糕,模型又得重新开发。
但是令人期待的是技术一直在进步。这几年随着AI 技术的发展,自动化建模技术已经非常成熟。自动建模技术是将数据科学家的知识和经验融入到一些软件工具中,在工具的帮助下,客户不需要掌握复杂的算法原理,参数也能开发出模型。并且自动建模的效率也远高于人工,几万条的数据,几分钟就能建出一个模型。用自动建模技术,数据挖掘(预测)类标签贴起来不再麻烦,把整理好的数据丢进去就能自动建模,自动贴标签。无论是开发成本还是周期都大幅度下降。
比如,SPL 就很好用,它有一个非常专业的自动建模库 Ymodel。在SPL 里,通过简单的函数调用,就能实现自动建模。
例如,某平台有一些客户的基本信息(性别,年龄,职业,收入等),历史消费数据,登陆浏览等行为数据,以及对某产品的历史购买信息数据,可以用这些数据来建模预测出客户对该产品的购买意愿。SPL 代码如下:
A |
||
1 |
=file("train.csv").import@tc() |
|
2 |
=ym_env() |
初始化环境 |
3 |
=ym_model(A2,A1) |
载入建模数据 |
4 |
=ym_target(A3,"y") |
设置预测目标 |
5 |
=ym_build_model(A3) |
执行建模 |
查看模型表现:
A |
||
... |
||
6 |
=ym_present(A5) |
查看模型信息 |
7 |
=ym_performance(A5) |
查看模型表现 |
8 |
=ym_importance(A5) |
查看变量重要度 |
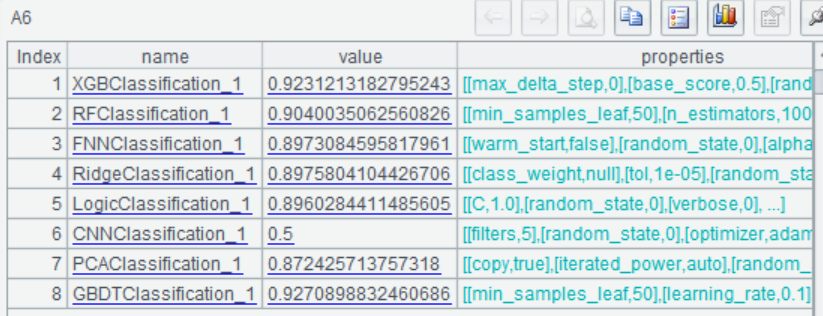
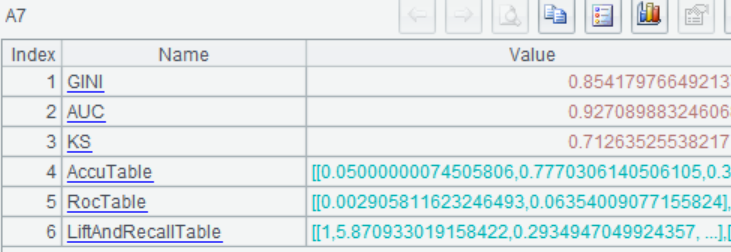
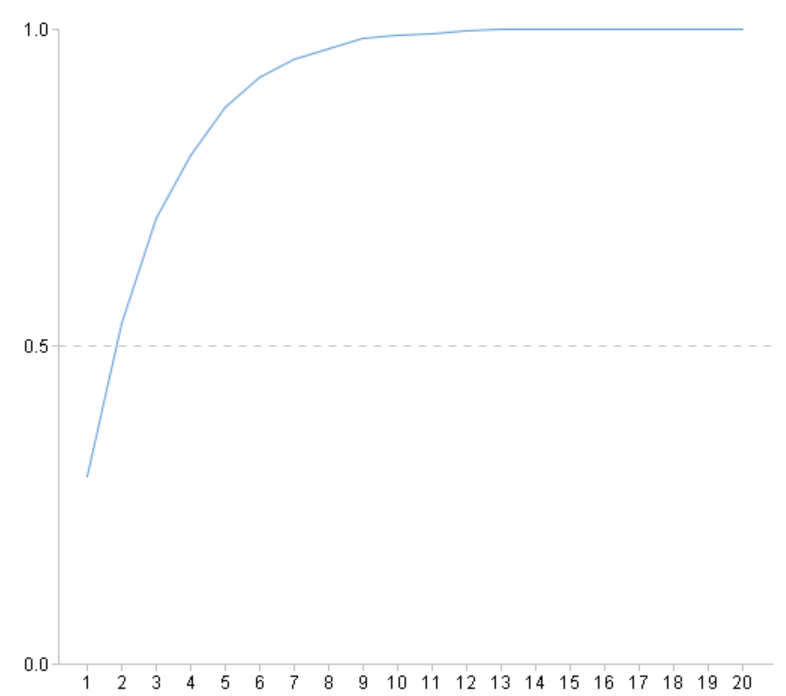
使用模型进行预测,预测出每个客户购买该产品的概率:
A |
||
... |
||
9 |
=ym_predict(A5,A1) |
执行预测 |
10 |
=ym_result(A9) |
获取预测结果 |
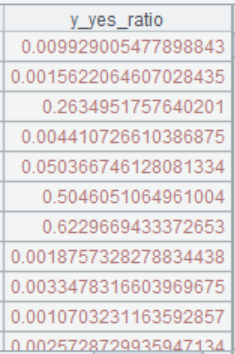
预测结果是一个0-1 之间的概率值,概率越大表示越可能购买该产品。根据值的大小就可以给用户贴标签了,可以划分高低两档,也可以划分高中低多档。然后业务人员根据不同标签的客户进行有针对性的营销策略,比如可以对摇摆不定的中低档客户增加推广活动,提高其购买率。用算法预测出来标签,考虑的维度更多,比简单的统计或规则也要精准的多。
当然有很多标签也是生命周期的,比如用户前几个月还是在校学生,毕业季一过就成为了职场白领。因此一般隔一段时间就需要重新建模来更新标签。有SPL 自动建模,模型迭代就容易多了,只要设置好触发条件,(如定时一个月或模型准确度下降到某个值)到时候模型就自动跑好了,直接省去了重新再开发模型的成本。
更加完整的数据挖掘过程可以参考:用 SPL 做数据挖掘建模预测 - 乾学院 (raqsoft.com.cn)
SPL 除了可以帮助贴算法预测类标签外,它本身还是一个擅长结构化数据计算的工具,有着丰富计算函数,优秀的大数据运算能力,用它来做统计和规则类标签更是不在话下,并且在很多复杂场景的计算有着独特的优势。详情可参考SPL 提效数据准备。


英文版