


人工智能中的“人工”
自从 AlphaGo 赢了之后,人工智能就变得非常热门了,ChatGPT的出现,更是将人工智能的热度推上了一个新高度。不过,大家在关注“智能”时,却很少把注意力放在“人工”上,似乎感觉上了人工智能之后,一切都能自动化了。其实,这份智能的背后有着大量的“人工”,还有相当多不能自动化的事情。
这里的人工主要体现在两个方面:
1. 数据准备
现代的人工智能技术,或者说机器学习,其基本方法和 N 多年前的数据挖掘并没有什么太大的不同,也还是将大量数据喂给计算机用于训练模型,模型生成之后就可以用于自动化处理,看起来就像有了智能。
然而,用于实际业务的机器学习项目,并不象 AlphaGo 那样可以自己生成数据来训练(其实 AlphaGo 的前期版本也用了大量现存的棋谱),必须使用实际发生过的数据才能训练模型。包括ChatGPT也是采用大量的书籍和互联网数据,来训练模型的。不同的数据训练出来的模型完全不同,数据的质量严重影响模型的效果。
但是,实际的数据五花八门,散落在各个应用系统甚至不同的网站中。想把它们整理出来供算法使用,并不是一件容易的事。机器学习需要的常常是比较规整的宽表数据,这还需要把各个应用系统中的关联数据拼接到一起;而各系统的数据编码规则可能不一样,这还需要先统一化;有些数据还是原始的文本(日志)形式,还需要事先从中抽取出结构化的信息;更不要说还有从互联网上扒出来的数据;…。
有经验的程序员都知道,一个人工智能项目中,用于数据准备的时间大约会占到 70%-80%,也就是说,绝大多数工作量都花在训练模型之前。
这其实就是我们常说的 ETL 工作了,这些事看起来没什么技术含量,似乎是个程序员就能做,人们也就不很关心,但成本却高得要命。
2. 数据科学家
ETL 整理好的数据,也仍然不是那么好用的。还需要数据科学家来进行进一步处理才能进入建模环节。比如有些数据有缺失的,那么需要有某种办法来补缺;数据的偏度太大,而很多统计学方法要假定数据分布要尽量满足正态分布,这就需要先做一遍纠偏;还需要根据业务情况生成衍生变量(比如从日期生成星期、节假日等);…。这些工作虽然也是建模前准备工作,但需要较专业的统计学知识,我们一般不把它算作为 ETL 的范围。
机器学习的建模算法有好几十种,各种算法都有各自的适用范围,还有大量的参数需要调节。如果用错了模型或调错了参数,那就会得到非常不智能的结果了。这时候又需要数据科学家们不断地尝试,计算并考察数据特征,选用合理的模型和参数,根据结果再反复迭代,经常较漫长的时间才能建一个实用的模型出来,短则二三周、长则二三月。
不过,近年来也出现一些完全自动迭代的手段(主要是神经网络),但计算时间很长,而且在许多领域(如金融风控)的效果并不太好,更有效的仍然是由数据科学家主导的方案,然而数据科学家们又少又贵….。
是不是觉得现在的技术还有点 low?人工智能的背后原来一点也不智能!
也不尽然,虽然有很多人工无法避免,但是却可以通过选用一些工具和技术来提高效率,减少一些人工。
事实上为了减少这些“人工”,市场上也出现了五花八门的工具和平台,但是质量却参差不齐,其中不少更是噱头。不过也不乏有做的还不错的。比如SPL就很好用。
SPL全称Structured Process Language,是一款开源的,轻量级工具,专门用于结构化数据处理,用它来做数据准备工作很方便。同时它还有自动建模的功能,可以减少一部分数据科学家的工作。
SPL 提效数据准备
(1)语法设计科学,无需在各种数据类型之间转来转去
数据准备工作的内容基本都是结构化数据的各种操作和计算,而SPL正是擅长于结构化数据计算的语言,与常用的Python相比有更科学和统一的设计。比如,使用 Python 时,经常用到 Python 的原生类库和多个第三方类库里的数据对象,比如 Set(数学集合)、List(可重复集合)、Tuple(不可变的可重复集合)、Dict(键值对集合)、Array(数组)、Series、DataFrame等,不同库之间的数据对象极易发生混淆,互相转化困难,对初学者造成了不少困扰。甚至即使是同一种库的数据对象也会混淆,比如Series 与自家分组后的集合 DataFrameGroupBy。
这些都说明各种第三方类库, 没有参与 Python 的统一设计,也无法获得 Python 的底层支持,导致语言的整体性不佳,基础数据类型尤其是结构化数据对象(DataFrame)的专业性不强,影响编码效率和计算效率。
而SPL则有着科学统一的设计,只有两种集合,序列(类似 List)和序表,前者是后者的基础,后者是有结构的前者,序表分组后的集合是序列,两者关系清楚泾渭分明转化容易,学习和编码的成本都很低。
(2)丰富的计算函数
SPL有丰富的计算函数,包括:遍历循环.()、过滤select、排序sort、唯一值id、分组group、聚合max\min\avg\count\median\top\icount\iterate、关联join、合并conj、转置pivot。
并且SPL对记录集合的集合运算支持较好,针对来源于同一集合的子集,可使用高性能集合运算函数,包括交集isect、并集union、差集diff。对于来源不同的集合,可用merge函数搭配选项进行集合运算,包括交集@i、并集@u、差集@d。而在Python则没有专门的函数进行记录集合的交、并、差等运算,只能间接实现,代码比较繁琐。
除了集合运算,SPL还有其独有的运算函数:分组汇总groups、外键切换switch、有序关联joinx、有序归并merge、迭代循环iterate、枚举分组enum、对齐分组align、计算序号pselect\psort\ptop\pmax\pmin。在Python中没有直接提供这些函数,需要硬编码实现。
在进行单个函数的基础计算时,使用Python和SPL没多大区别,但当做有一定复杂度的工作时,SPL就比较有优势了。而实际业务中的数据准备工作通常会有一定的复杂度。
比如有一份销售数据,我们希望先按年、月分组,统计每个月的销售额,然后再计算每个月比去年同月份的销售额的增长率。
Python实现:
sales['y']=sales['ORDERDATE'].dt.year
sales['m']=sales['ORDERDATE'].dt.month
sales_g = sales[['y','m','AMOUNT']].groupby(by=['y','m'],as_index=False)
amount_df = sales_g.sum().sort_values(['m','y'])
yoy = np.zeros(amount_df.values.shape[0])
yoy=(amount_df['AMOUNT']-amount_df['AMOUNT'].shift(1))/amount_df['AMOUNT'].shift(1)
yoy[amount_df['m'].shift(1)!=amount_df['m']]=np.nan
amount_df['yoy']=yoy
在分组汇总时,Python不能够边计算边分组,通常要先追加计算列再分组,这导致代码变复杂。计算同期比时,Python用 shift 函数进行整体移行,从而间接达到访问“上一条记录”的目的,再加上要处理零和空值等问题,整体代码就更长了。
SPL代码:
A |
|
2 |
=sales.groups(year(ORDERDATE):y,month(ORDERDATE):m;sum(AMOUNT):x) |
3 |
=A2.sort(m) |
4 |
=A3.derive(if(m==m[-1],x/x[-1] -1,null):yoy) |
分组汇总时,SPL 可以边计算边分组,灵活的语法带来简练的代码。计算同期比时,SPL 直接用 [-1] 表示“上一条记录”,且可自动处理数组越界和被零除等问题,整体代码较短。
关于SPL简洁计算的例子还有很多,可参阅数据准备脚本:Python Pandas OR esProc SPL? - 乾学院 (raqsoft.com.cn),SPL 和 Python 应用于结构化数据处理的对比 - 乾学院 (raqsoft.com.cn)
(3)优秀的大数据运算能力
SPL拥有完善的游标机制,用它可以轻松处理大数据,而且多数游标函数的用法和内存函数没有什么区别,对用户很友好。并且SPL还具备并行能力,支持游标的遍历复用。在大数据常用的聚合,过滤,排序,分组汇总、关联、交集等计算上,SPL表现都很优秀,代码简单,运算高效。计算案例可参阅数据准备脚本:Python Pandas OR esProc SPL? - 乾学院 (raqsoft.com.cn),SPL 和 Python 应用于结构化数据处理的对比 - 乾学院 (raqsoft.com.cn)
(4)直观友好的编程环境
在编程方式上,几乎所有编程语言都是写成文本式的,每一个变量命一个名字,每查看一次结果就print一次。如果是做编程开发这并没有什么问题,但是用来做数据准备即ETL就很不方便了。虽然也有像Notebook这样的交互式工具,但用起来也不尽人意。而SPL就好用多了。
SPL 采用了独特的网格式编程,在每一步的计算结果都被保留下来,点击某个单元格就可以实时查看该步(格)的计算结果,计算正确与否一目了然。不需要手动输出,每步结果实时查看,这对于ETL工作非常友好。并且它可以像excel一样以单元格名(如 A1)的形式来引用该单元格内的计算结果(中间变量),省去了绞尽脑汁为各种中间表格和变量起一堆名字。
(5)简单易学
SPL学起来也很简单,函数的语法根据自然思维方式而开发,很容易做到融会贯通,举一反三。入门难度要小于Python,和SQL差不多。
SPL 实现自动建模
SPL除了可以用来高效的准备数据,更方便的是它还有可以全自动化建模的库,配置好建模外部库,然后通过简单的函数调用,就能实现自动建模。对于程序员来说,不需要去学习如何预处理数据,也不需要学习各种复杂的算法原理和参数用途,只要对数据挖掘有一个概念的了解就能建出优质模型。对于数据科学家来说,则不必整日沉浸在反反复复处理数据,调试模型的工作中,很大程度上减少了人工的工作量,提高了工作效率。
以经典的泰坦尼克生存预测数据为例,通过简单的几句代码就可以建好模型:
A |
|
1 |
=file("titanic.csv").import@qtc() |
2 |
=ym_env() |
3 |
=ym_model(A2,A1) |
4 |
=ym_target(A3,"Survived") |
5 |
=ym_build_model(A3) |
查看模型表现:
A |
|
... |
|
6 |
=ym_present(A5) |
7 |
=ym_performance(A5) |
8 |
=ym_importance(A5) |
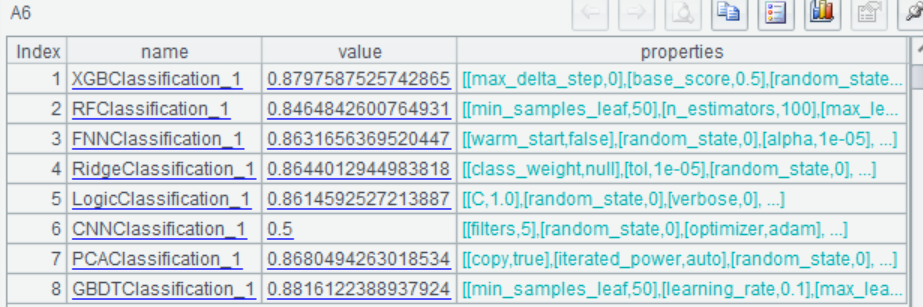
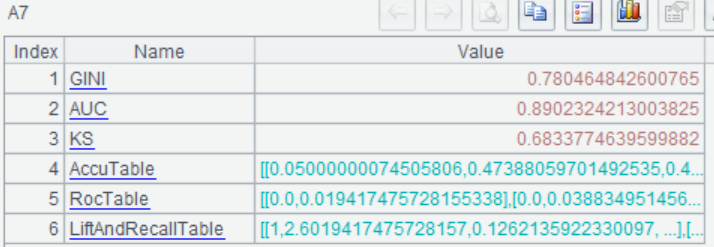
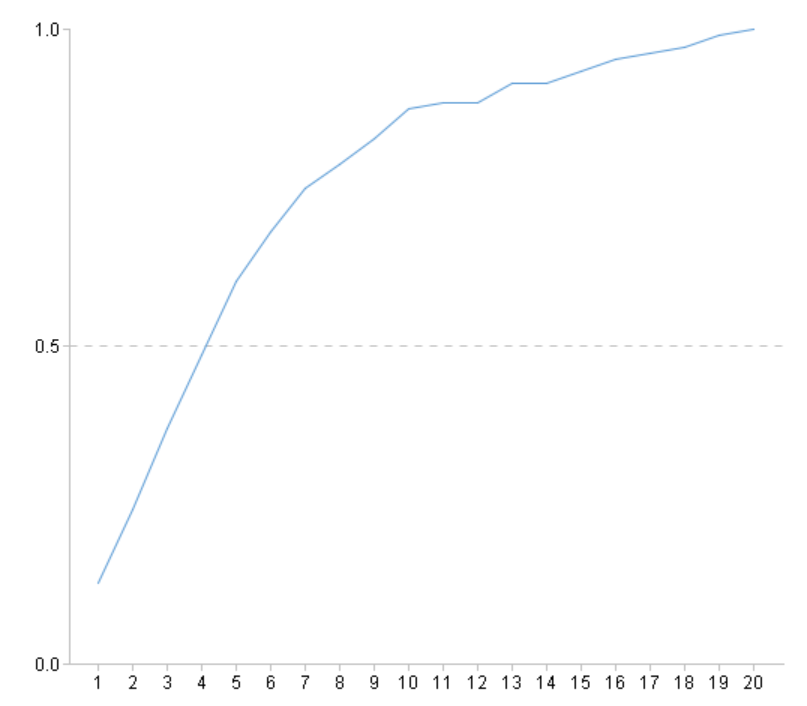
使用模型进行预测,预测出每位乘客存活的概率:
A |
|
... |
|
9 |
=ym_predict(A5,A1) |
10 |
=ym_result(A9) |
完整过程可以参考:用 SPL 做数据挖掘建模预测 - 乾学院 (raqsoft.com.cn)
SPL的自动建模功能可以自动识别数据中存在的问题并进行预处理,比如数据缺失,异常,非正态分布,时间日期变量,高基数变量......。预处理完成后,就会进行自动建模和调参,然后模型评估,输出优质模型。整个过程是完全自动的进行的,无需人工参与。
借助自动建模,可以省去数据科学家处理数据和调试模型的人工,同时又可以降低数据挖掘的门槛非专家也能建模。而且在实际的工作的场景很多时候要建多个甚至很多模型,自动化的建模方式就更有优势。
例如,银行有多种金融产品比如存款,贵金属,理财,分期贷款......,也有多个重点客户群体,比如代发工资群体,车主群体......,银行需要挖掘潜力客户清单,推荐金融产品组合包,对目标客户进行多产品组合同步营销。这个案例中有多种产品,多个客户群体,为了实现目标需要建立很多个(几十甚至上百个)模型,如果全部用人工来一个一个建模,则需要耗费大量的人力和时间,几乎可以说是一个庞大的任务。但使用自动建模技术,就容易多了,数据准备好以后,放进 SPL 里跑,很快就完成了。并且模型的效果也不错,使用模型后日均增长额提高了 70 多倍。
因此,虽然人工智能的背后还有很多“人工”要完成的工作,但是借助合适的工具也可以在一定程度上减轻工作量提高提高工作效率。SPL 一方面可以高效的准备数据,一方面又可以实现自动化建模,是机器学习的必备工具。而且 SPL 是非常轻量级的工具,无论是独立安装还是集成到企业系统也都很方便。


英文版