


SPL 和 Python 应用于结构化数据处理的对比
概述
SPL主要是为了解决SQL的困难(复杂任务很难写且跑得慢、跨源计算难、依赖存储过程等)而设计的,其应用场景也与SQL类似,一般会配合应用程序工作,且能支持大数据,包括高性能运算和并行运算。
Python同样可以辅助解决SQL复杂任务难写的问题,但它是从桌面程序语言发展过来的,与应用程序配合能力不强,大数据和并行计算能力也很弱。
不过,Python是AI界的明星,拥有丰富的第三方类库和算法,比如Sklearn、TensorFlow、PyTorch等,俨然成为AI第一语言。相比之下,SPL的AI能力比较薄弱,只有部分数学函数。
SPL和Python都能用于简化结构化数据运算的繁琐语法,但深究起来,还是有较大不同。SPL对结构化数据的理解更深刻,提供的运算能力也更完善,而且有较好的语法一致性。
对结构化数据的理解
数据表
SPL继承了SQL中表和记录的概念,记录是有属性(字段)的对象,表是相同结构的记录构成的集合。SPL对SQL还进行了扩展,允许记录游离于表之外,不同表的记录可以组成新集合参与运算。
Python没有明确的表和记录的概念,在Python中常用于表示结构化数据的DataFrame本质上是个带有行列索引的矩阵,列索引通常是字串可当作字段名。结构化数据也常常以二维表形式出现,粗看下来也像个矩阵。对于简单的基础运算,确实也差不多,但情况稍复杂一些,就会发生理解差异,导致不能按常规思路编写代码。
来看看简单的过滤运算。
现有员工数据如下:

问题一:取出R&D部门的员工。
Python代码是这样的:
import pandas as pd
data = pd.read_csv('Employees.csv')
#过滤
rd = data.loc[data['DEPT']=='R&D']
print(rd)
代码很简单,结果也没问题,但是用到的函数叫loc,是location(定位)的缩写,完全没有过滤的意思。事实上,这里的过滤通过定位(location)满足条件的行的索引来实现的,函数里面的data[‘DEPT’]==’R&D’会算出一个布尔值的Series(如下图,索引和data的索引相同,满足条件的行为True否则为False),然后loc 就是根据True的行索引取出数据,本质是个矩阵的运算。

布尔值Series
另外,过滤DataFrame不只可以使用loc函数过滤,还可以用query(…)等方法,但本质上都是定位到矩阵的行列索引,然后按行列索引取数据,大体上是这样的matrix.loc[row,col]。
SPL就是用函数从数据表中筛选出满足条件的记录:
A |
B |
|
1 |
=file(”Employees.csv”).import@tc() |
/读入数据 |
2 |
=A1.select(DEPT==”R&D”) |
/过滤出子集 |
符合集合运算的思维。
下面我们尝试对这个过滤后的子集做个简单的运算看看,比如修改子集中的数据。
问题二:将R&D部门员工的工资上调5%
自然的想法,只要过滤出R&D部门员工,然后对这些员工的工资进行修改就可以了。
按照这种逻辑写出Python代码:
import pandas as pd
#读取数据
data = pd.read_csv('Employees.csv')
#过滤R&D部门成员
rd = data.loc[data['DEPT']=='R&D']
#修改工资
rd['SALARY']=rd['SALARY']*1.05
print(data)
这段代码不仅触发了运行警告,而且也不会修改SALARY。
这是因为rd = data.loc[data['DEPT']=='R&D']是一个过滤后的矩阵,在对它修改SALARY时,其实是修改的子矩阵rd,并没有修改data这个最初的矩阵。
正确的代码怎么写呢?
import pandas as pd
data = pd.read_csv('Employees.csv')
#找到R&D部门的员工工资
rd_salary = data.loc[data['DEPT']=='R&D','SALARY']
#截取R&D部门的员工工资并修改
data.loc[data['DEPT']=='R&D','SALARY'] = rd_salary*1.05
print(data)
Python的子集是一个新矩阵,不能游离于原集合之外,所以要修改某个部门的工资,只能先取到它(rd_salary=…这句),想要上调5%还要从原矩阵中再截取它,再用拿到的数据来修改。这种写法要进行重复过滤,效率低也就罢了,实在是太绕了。
SPL把表理解成记录的集合,过滤就是取子集,接下来按正常思路修改子集数据即可,代码这样写:
A |
B |
|
1 |
=file(”Employees.csv”).import@tc() |
/读入数据 |
2 |
=A1.select(DEPT==”R&D”) |
/过滤出子集 |
3 |
=A2.run(SALARY=SALARY*1.05) |
/对子集修改 |
A2(R&D部门的员工)是A1(员工表)的子集,它只是A1的引用,所以修改A2时,原集合A1也会被修改。
运算
除了数据类型的理解不同,SPL和Python对运算的理解也有差异,比如常见的聚合运算。
Python和SQL一样,聚合运算的结果规定为单个值,如 sum、count、max、min等。但SPL不同,任何从一个大集合提炼出某些信息都可以看成是聚合运算,比如选出最值成员:
查看薪水最高的成员信息。
Python代码这样写:
import pandas as pd
#读取数据
emp = pd.read_csv('Employees.csv')
#选出最大值成员(1个成员)
#薪水最高成员索引
max_salary_idx=emp.SALARY.argmax()
#薪水最高成员
max_salary_emp=emp.loc[max_salary_idx]
print(max_salary_emp)
#选出最大值成员(多个成员)
#最高薪水
max_salary=emp["SALARY"].max()
#按最高薪水选出
max_salary_emp=emp[emp.SALARY==max_salary]
print(max_salary_emp)
Python没有把取出最大值所在成员作为聚合函数,这个任务就分两步,先用argmax()来得到目标值的索引,再按索引选出成员。而且,argmax()只能返回一个最大值所在成员的索引,如果要返回最大值所在的所有成员,需要遍历两遍数据(第一遍计算最大值,第二遍选出成员),这无疑要麻烦很多。
SPL则认为这类运算和sum、count等没什么区别,都属于聚合运算,都是从大集合中提炼信息,代码这样写:
A |
B |
|
1 |
=file(”Employees.csv”).import@tc() |
|
2 |
=A1.maxp(SALARY) |
/1个最大值的成员 |
3 |
=A1.maxp@a(SALARY) |
/所有最大值成员 |
聚合函数maxp()返回最大值所在成员,加@a选项返回全部目标值成员,和sum、count等常规聚合函数并没有本质区别,用法一致,写法简单。
SPL也提供类似argmax这样返回最大值所在序号的运算,仍然被作为聚合函数。
A |
B |
|
1 |
=file(”Employees.csv”).import@tc() |
|
2 |
=A2.pmax(SALARY) |
/1个最大值成员的位置 |
3 |
/所有最大值成员的位置 |
语法风格都一致。
类似的运算还有TOPN,Python不把 TOPN 运算看成是聚合,要先排序再取前 N 条。SPL提倡普遍集合,聚合运算的结果不一定是个集合,和sum、maxp类似,直接计算即可,不必先做排序。
还有很多SPL和Python理解不同的运算。比如连接,Python延用了SQL的理解,把连接定义为笛卡尔积后再过滤,适用范围很广泛,但会缺失一些关键特征,无法简化书写和性能优化。SPL则是把最常见的等值连接分类,并要求主键相关,剔除了多对多的情况,这种定义下的连接,能在代码中直接引用关联字段以简化书写,不会因漏写关联条件而产生错误逻辑,还能利用主键优化运算性能。
Python对数据表和运算的理解不如SPL深刻,导致自然算法思路不易实现,对于基础运算感觉不明显,但稍复杂的运算就会造成代码实现难度变高。
运算的完善度
SPL对结构化数据运算的设计也比Python更丰富,我们以SQL不擅长的有序计算为例来说明。
SPL的集合是有序的,可以按序号引用集合成员。Python的DataFrame也是有序的,也可以用序号(行索引)访问成员,最基本的有序运算两者都能支持,而这是SQL缺乏的,导致有序运算在SQL中很难写,这也是SPL和Python能解决SQL难写的原因之一。
但对于复杂深入的场景,SPL就和Python拉出差距了。
相邻引用
相邻引用是常见的有序运算,比如计算某支股票每天的涨跌幅,需要遍历时引用到前一行数据。
Python没有提供获取相邻数据的功能,要用偏移矩阵索引的方法,用偏移后的数据与原数据来计算涨跌幅,代码写出来是这样的:
import pandas as pd
#读取数据
stock_62=pd.read_csv(“000062.csv”)
#偏移1行
stock_62s=stock_62["CLOSING"].shift(1)
#计算涨跌幅
stock_62["RATE"]=stock_62["CLOSING"]/stock_62s-1
print(stock_62)
SPL提供了[]符号获取相邻数据,代码非常简洁。
A |
B |
|
1 |
=file(“000062.csv”).import@tc() |
/读取数据 |
2 |
=A1.derive(if(#==1,null,CLOSING/CLOSING[-1]-1):RATE) |
/增加涨跌幅 |
有序分组
SQL中的分组只关心分组键值,不关心数据次序,但有些分组运算与次序相关,比如分组条件与相邻成员有关的分组,这是一个SQL比较头疼的问题。
比如给定一个由字母和数字构成的字符串abc1234wxyz56mn098pqrst,将其拆分成 abc,1234,wxyz,56,mn,098,pqrst 这几个小字符串。
Python和SQL一样,分组只关心键值,所以要自己烧脑造一个衍生列,绕到键值分组上,代码这样写:
import pandas as pd
s = "abc1234wxyz56mn098pqrst"
#创建Series
ss = pd.Series(list(s))
#判断是否是数字
st = ss.apply(lambda x:x.isdigit())
#衍生一个判断相邻数据是否相等的Series
sq=(st != st.shift()).cumsum()
#按衍生列分组
ns =ss.groupby(sq).apply(lambda x:"".join(x))
print(ns)
SPL为分组提供了@o选项,可以把相邻相同的数据分成一组,数据变化时开始新的一组。
A |
B |
|
1 |
abc1234wxyz56mn098pqrst |
|
2 |
=A1.split().group@o(isdigit(~)).(~.concat()) |
/值变化分组 |
定位计算
定位计算指计算逻辑与涉及数据及其所在集合的位置相关的运算,这也是数据分析时常见的运算,比如计算某支股票股价最高的三天的涨幅,这需要用到股价最高的三天(成员)的股价(数据本身),还要用到这三天的前一天(数据所在位置的运算)的股价才能计算出涨幅。
计算某支股票股价最高的三天的涨幅。
Python不可以在循环过程中针对数据的位置信息来计算,只能换一个思路,先找到股价最高的三天的索引,然后偏移数据,再拿股价最高三天的数据和偏移后的数据计算。
Python代码:
import pandas as pd
#获取000062股票信息
stock_62=pd.read_csv(“000062.csv”)
#排序后的位置
sort_pos=(-stock_62["CLOSING"]).argsort()
#股价最高的3天的位置
max3pos=sort_pos.iloc[:3]
#数据偏移
stock_62s=stock_62.shift(1)
#股价最高的3天的股价信息
max3CL=stock_62["CLOSING"].iloc[max3pos]
#股价最高的3天前一天的股价信息
max3CLs=stock_62s["CLOSING"].iloc[max3pos]
#涨跌幅
max3_rate=max3CL/max3CLs-1
print(max3_rate)
SPL提供了calc函数,使用[]符号获取相邻数据,利用成员的位置和相对位置完成计算。
A |
B |
|
1 |
=file(“000062.csv”).import@tc() |
|
2 |
=A1.psort@z(CLOSING) |
/股价排序位置 |
3 |
=A2.m(:3) |
/取前3个位置 |
4 |
=A1.calc(A3,if(#==1,null,CLOSING/CLOSING[-1]-1)) |
/按位置算涨幅 |
这里计算股价最高3天的位置信息还可以用ptop(…)函数,同样返回股价最高的3天位置,这是之前提到过的TOPN运算,不过top返回成员,ptop返回成员位置,他们都属于聚合运算。这样的话,A2就不需要了,A3=A1.ptop(-3,CLOSING),A4正常算。
非等值分组
有序运算只是一个方面,SPL比Python还有更多运算设计得更完善,比如对非等值分组的支持。
分组运算的本意是将一个大集合按某种规则拆成若干个子集合,SPL就是这种很自然的思维,既有等值分组(完全划分),也有非等值分组(不完全划分)。Python只能进行等值分组,非等值分组只能自己想办法绕到等值分组上。
来看一个非等值分组的例子:
统计公司指定的部门['Administration', 'HR', 'Marketing', 'Sales']的男员工人数。
因为部门可能不止案例中列出的4个(可能有成员未被分到任何一组),也可能有的部门没有男员工(可能有组是空集),而Python只能进行等值分组,所以要多绕一步,借助merge函数对齐后再分组。代码是这样的:
import pandas as pd
#自定义对齐分组函数
def align_group(g,l,by):
d = pd.DataFrame(l,columns=[by])
m = pd.merge(d,g,on=by,how='left')
return m.groupby(by,sort=False)
file="D:\data\EMPLOYEE.csv"
#读取数据
emp = pd.read_csv(file)
#筛选男员工
emp_f=emp.query('GENDER=="M"')
sub_dept = ['Administration', 'HR', 'Marketing', 'Sales']
#对齐分组
res = align_group(emp_f,sub_dept,'DEPT').EID.count()
print(res)
SPL就要聪明很多,它提供了对齐分组函数,按指定部门对齐分组即可。
A |
B |
|
1 |
D:\data\EMPLOYEE.csv |
|
2 |
=file(A1).import@tc() |
|
3 |
=A2.select(GENDER=="M") |
/选出 |
4 |
[Administration, HR, Marketing, Sales] |
/指定部门 |
5 |
=A3.align@a(A4,DEPT).new(A4(#):DEPT,~.len():NUM) |
/对齐分组聚合 |
这个例子只介绍了非等值分组的两个特点(1.可能有成员未被分到任何一组;2. 可能有组是空集),还有成员被分到不同组的情况,这对于Python来说就更绕了,而SPL很简单,只要通过enum@r()函数完成计算即可,详细的例子介绍请关注这篇文档《Python 和 SPL 对比 7——对齐与枚举分组》。
Python提供的运算完善度不足,虽然使用基础运算(索引偏移、分组、获取位置等)都能完成以上任务,但计算思路绕来绕去,代码复杂度较高。SPL的运算相对比较完善,计算思路简单直接,关键代码只要一两行。
语法一致性
作为一门程序语言,处理相似问题应该有一套系统的方法,这样才容易举一反三,发挥出这门语言的最大作用。Python在这方面做的不好,前面介绍聚合函数时已经提到过,返回一个最大值成员和多个时语法差异较大(这还可以解释为运算理解不同造成的完善度问题),我们再来看一些更直接的例子。
之前介绍了相邻引用的问题,Python是用shift()函数来完成运算的,这里再来看一个类似的问题:
计算某支股票连续 5 个交易日的移动平均值。
这个问题和之前算当天的涨跌幅是类似的,都是获取相邻数据完成计算,区别只是获取一行还是多行数据。
Python代码这样写
import pandas as pd
#读取数据
stock_62=pd.read_csv(“000062.csv”)
#偏移1行
stock_62["MAVG"]=stock_62["CLOSING"].rolling(5,min_periods=1).mean()
print(stock_62)
Python虽不能获取相邻成员,但它应该延用之前shift()函数来完成,可是并没有,而是通过一个新的函数rolling()来完成,这种处理方式像是“一题一解”,令人费解。
SPL就要好很多,它延用[]的形式,只是原来是取相邻1行数据,现在是相邻4行数据。
A |
B |
|
1 |
=file(“000062.csv”).import@tc() |
/读取数据 |
2 |
=A2.derive(CLOSING[-4:0].avg():DAY5) |
/移动平均 |
类似的还有之前介绍定位计算时提到过的获取排序后成员位置的函数,当时排序的键只有一个,用的是 argsort()函数,当多列键按不同顺序排序获取位置信息时,argsort()就不能用了,需要另一个函数lexsort()。
计算按股票代码升序、股价降序排序后的位置/索引。
Python代码
import pandas as pd
stock_file="D:/data/STOCKS.csv"
#读取数据
stock_data=pd.read_csv(stock_file,dtype={'STOCKID':'object'})
import numpy as np
#获取位置信息
sort2key_pos=np.lexsort((-stock_data["CLOSING"],stock_data["STOCKID"]))
print(sort2key_pos)
Python的lexsort()函数并不是pandas中的,而是numpy库中的,且这个函数不能逆序排序,只能用负号“-”来表示逆序,但是Python又不支持字符串用负号。这个问题如果是按STOKID降序,CLOSING升序来排序,lexsort()函数就用不了了,不得不另想办法。
SPL就简单得多,仍然用psort()函数即可。
SPL代码:
A |
B |
|
1 |
D:\data\STOCKS.csv |
|
2 |
=file(A1).import@tc(#1:string,#2,#3) |
/读取数据 |
3 |
=A2.psort(STOCKID,-CLOSING) |
/多列不同方向排序位置/索引 |
无论是单列还是多列,无论是逆序还是顺序,psort()都可以完成,而且SPL支持字符串取负号(-STOCKID就是逆序排序)。
在数据结构方面,原生Python和第三方库都设计了不同的数据结构,就拿集合来说,Python就有数种形式,列表(list),集合(set),数组(array),Series,DataFrame,每一种数据结构都有其擅长的场景,虽说可以相互转换,但语法规则的不一致也给用户带来不少烦恼。SPL就要好很多,它的集合只有两种,序列和序表,严格说就只有一种,即序列,也就是有序集合,序表只是由记录组成的序列。在计算时,只要掌握序列的计算规则,就可以举一反三,用相似的方法解决相似的问题。
Python就像野蛮生长的植物,虽然适应能力强,总可以找到方法解决问题,但有些时候太绕,而且不容易举一反三,不仅计算效率低,而且用户体验还不好。
相比之下,SPL是精心设计的,语法一致性更好,更容易举一反三,完成各种计算任务。
Lambda 语法
基本程序逻辑方面,Python和SPL都拥有完备的分支流程、循环流程、子程序等功能。这是强于SQL的地方,也是另一个适合用于解决SQL复杂问题的原因。
Python和SPL都是动态语言,都有循环函数的概念,可以使用Lambda语法,以避免编写繁琐的循环语句,比如计算前100整数的平方和。
Python代码:
import pandas as pd
#1到100
l=[i for i in range(1,101)]
#创建Series
s=pd.Series(l)
#平方和
odd_sum=s.apply(Lambda x:x*x).sum()
print(odd_sum)
Python的Lambda语法比较常规,循环时设置一个参数(x)表示循环时的当前成员,然后对参数(x)执行需要的运算。
SPL没有定义 Lambda语法中用的参数变量,代之以~这种固定符号,这种写法形式简单,不需要定义变量。
SPL代码:
A |
B |
|
1 |
=to(100) |
/生成序列 |
2 |
=A1.sum(~*~) |
/用 ~ 表示当前元素 |
用固定符号~,写法固然简洁,但也会遇到麻烦,比如嵌套循环时,符号~的识别会混淆。这时还是要定义变量,区别各层循环的变量。
比如计算前100个数的两两距离。
A |
B |
|
1 |
=to(100) |
/生成序列 |
2 |
=A1.((v=~,A1.(abs(v-~)))) |
/两两算距离 |
SPL规定符号~只表示最内层循环的成员,外层成员要另外设置变量来标记。
上边的例子中Python是对Series计算,SPL是对序列计算,那如果是有结构的Dataframe和序表呢?
把前100个数整理成Dataframe就可以了,字段名命名为value,Python代码是这样的:
import pandas as pd
#1到100
l=[i for i in range(1,101)]
#创建Series
df=pd.DataFrame(l,columns=["value"])
#平方和
odd_sum=df.apply(lambda x:x.value*x.value,axis=1).sum()
print(odd_sum)
从代码可以看出,Python的lambda语法可以针对Dataframe来做,但不能直接引用字段,还要用符号”.”来获取,这对于字段众多的结构化数据运算来讲较为繁琐。
SPL和SQL一样,在Lamba语法中可以直接引用字段。
SPL代码:
A |
B |
|
1 |
=100.new(~:value) |
/生成序表 |
2 |
=A1.sum(value*value) |
/用字段名计算 |
单纯看上边的例子,Python和SPL的Lambda语法的区别仅仅是形式不同,本质上没区别。其实SPL的Lambda语法更丰富一些,它不仅可以获取当前循环成员,还可以获取当前循环成员索引和相邻成员。
比如现有某公司一年中每个月的销售额如下:
[123,345,321,345,546,542,874,234,543,983,434,897]
要计算出最大的月增长额。
SPL用#号表示当前成员序号,规定第一个月的增长额是0,[]获取相邻成员数据,计算后续每个月的增长额,代码这样写:
A |
B |
|
1 |
[123,345,321,345,546,542,874,234,543,983,434,897] |
/月销售额 |
2 |
=A1.(if(#==1,0,~-~[-1])).max() |
/最大月增长额 |
Python的Lambda语法无法获得当前成员序号和相邻成员数据,所以只能放弃lambda语法,用其他方法来做了。
Python代码:
import pandas as pd
amt = [123,345,321,345,546,542,874,234,543,983,434,897]
s = pd.Series(amt)
ss = s.shift()
ma = (s-ss).fillna(0).max()
print(ma)
这个例子还可以用原生Python的for循环来写,也不麻烦,但那就不是lambda语法了,这里不再介绍。
我们在对比相邻引用时已经用过#和[]了,提供这些符号使Lambda语法更加便捷,也使SPL的运算更加完善。
大数据能力
外存计算
Python的大数据处理能力很弱,几乎没有提供大数据运算的方法,想要完成一些很简单的任务也要自己硬编码。SPL拥有完善的游标机制,用它可以轻松处理大数据,而且多数游标函数的用法和内存函数没有什么区别,对用户很友好。
以大数据的分组汇总运算为例来介绍两者的区别。
现有某公司在美国各州的订单数据(数据量很大,单机内存放不下),请汇总各州的订单销售额。
计算思路:按照州分组后汇总销售额即可。
SPL为订单数据创建游标,之后对游标进行分组汇总运算,代码这样写:
A |
B |
|
1 |
D:\data\orders.txt |
|
2 |
=file(A1).cursor@t() |
/创建游标 |
3 |
=A2.groups(state;sum(amount):amount) |
/分组汇总 |
单纯看A3的代码并不能区分是内存计算还是游标计算,因为它和内存计算时的代码一模一样,但游标还是有特殊之处,比如我们想再按另一个字段(比如产地)再分组,如果是内存,那再写一句 groups 就行了,但如果是游标就不能再次使用了,它已经因遍历结束而取不出记录了,这时候需要重新创建一个新游标再做 groups。
Python想要完成这个分组汇总任务,需要分段读取,对每一段分组汇总,最后再将分组汇总的结果再分组汇总,这还要考虑分段的长度,否则可能分的段都读不进内存或者分组汇总的结果内存也放不下,听起来就很烦,用Python写起来更烦。这还只是分组后汇总的例子,不需要重写分组的过程,某些时候需要用Python来写分组的过程,其中涉及哈希分组的硬编码,代码的复杂程度即使是高级工程师也不轻松。
并行
Python的并行只是模拟并行的方法,但对于CPU来说也只是单核运行,所以本质上Python没有并行能力。
SPL提供了完善的并行能力,还支持游标的遍历复用。
还是刚才的订单数据,汇总各州销售额的同时统计各个州销售额大于50万美元的订单数量。
SPL代码
A |
B |
|
1 |
=file("D:\data\orders.txt").cursor@tm(area,amount;4) |
|
2 |
cursor A1 |
=A2.groups(state;sum(amount):amount) |
3 |
cursor |
=A3.select(amount>=50).groups(state;count(1):quantity) |
使用 @m 选项即可创建多路并行游标,SPL 会自动并行并得到正确结果,通过管道实现遍历复用,不仅充分利用了多核CPU的优势,也减少了遍历次数。
这里仅仅以分组汇总为例介绍游标系统,其他的运算(如汇总、关联等)SPL的游标系统都可以并行完成,这是Python所不能的。
二进制存储
文本文件具有很好的通用性,但解析复杂,性能很差,而且信息还会有歧义(比如电话号码通常是字符串,但可能会被识别成数值)。涉及数据量较大时,使用文本格式的读取时间很可能超过计算时间。
SPL提供了高性能的二进制文件格式,其中已经存储了数据类型,无须再解析,还提供了压缩列存等机制以进一步减少硬盘的读取量,采用这些格式存储较大数据,能有效减少读取时间。Python没有应用较广泛的二进制的文件格式(可能某些第三方类库支持),一般仍然只能使用文本格式,大数据量时读取性能就就会较差。
AI 能力
在数学AI方面,Python作为人工智能第一语言,拥有强大的统计学、图计算、自然语言处理、机器学习、深度学习能力。相较于Python,SPL在这方面还是小学生,只有部分数学和机器学习功能,未来还有很长的路要走。
集成性与数据源
在应用集成方面,SPL提供了标准 JDBC 接口,Java 应用可以直接无缝集成调用。对于.net/Python 等非 Java 应用则可以通过 ODBC/Restful 接口调用。
Python的集成性则相对较弱,经常要和主流Java及C#等语言编写的主程序跑成两个进程,调用性能和稳定性都不好。
在数据源接口方面,两者差别不大,都能访问常见的数据源(txt、csv、xls、json、xml等),而且都能访问各类数据库,完成读取、计算、写入等操作。
开发环境与调试
Python的IDE太多了,常用的有Pycharm、Eclipse、Jupyter Notebook等等,它们之间本身也各有优劣,但Python最常用的调试还是print大法(把想看的变量值打印出来),比较麻烦,调试完以后还要删掉。断点的设置、执行等都是正常设置,对调试bug很有用,值得一提的是Python的多数IDE都提供了变量和函数补全功能,写代码时可以节省不少时间。
SPL是网格式编程,可以随时查看网格值和变量值,相较于 print 大法要方便太多太多了,断点的设置和使用和Python的IDE区别不大,需要优化的是函数名、变量名的补齐功能。
Pycharm的IDE:
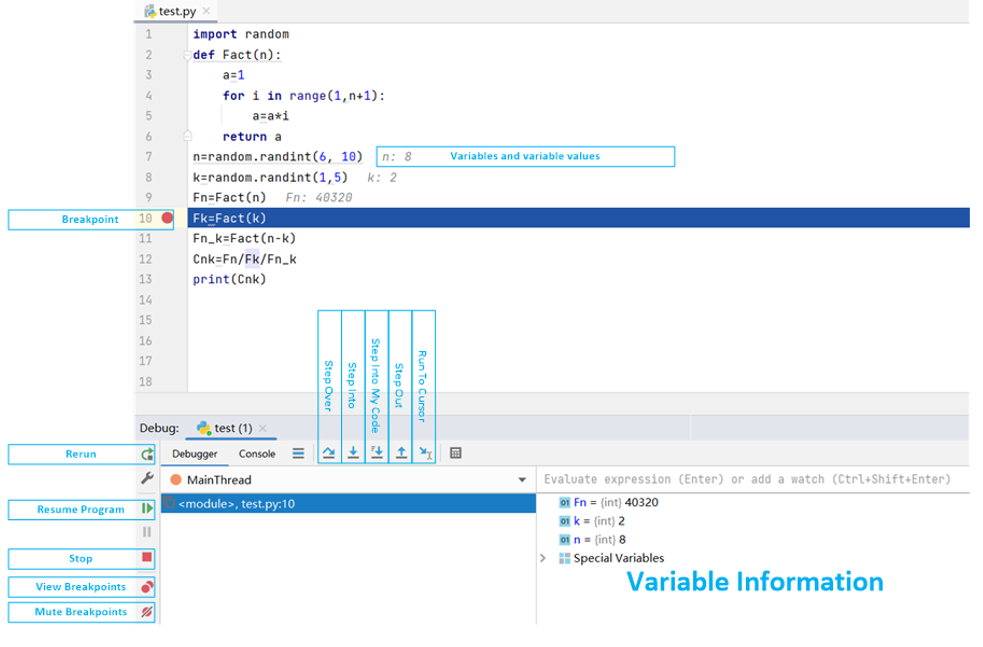
SPL的IDE:
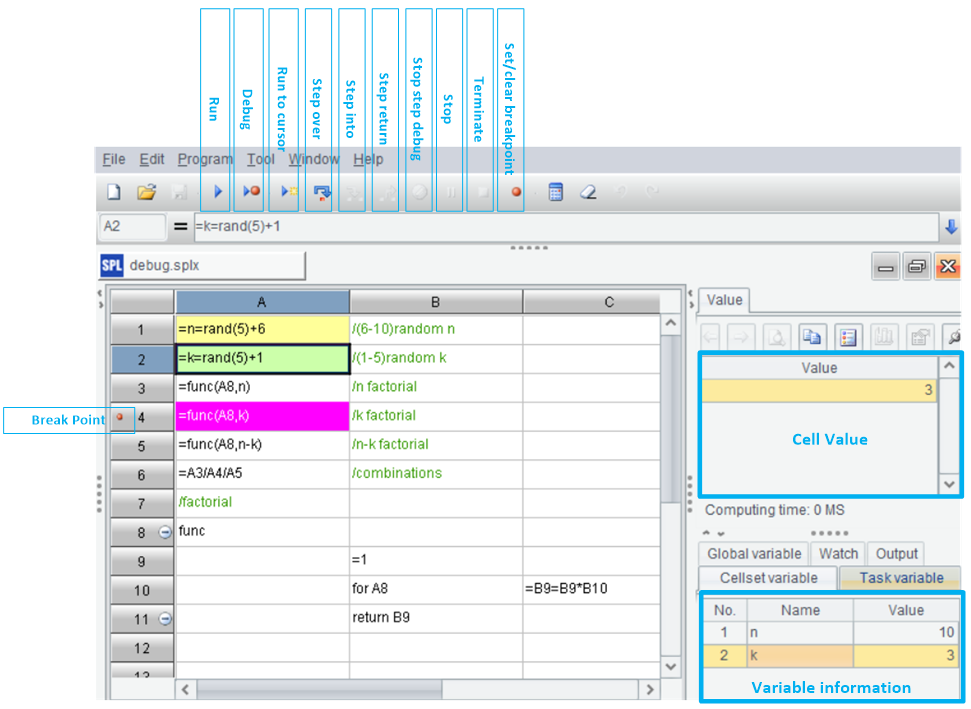


英文版