


玩不起大模型,小模型也不错
今年以来最热门的的话题,莫过于ChatGPT,它吹响了AI大模型的号角,多家企业和机构以加速度扎堆冲入被ChatGPT轰炸出来的大模型赛道。然而这终究是属于科技巨头们的竞赛,开发大模型需要具备大算力、大数据和强算法等核心能力,技术门槛高,投入资金大。
以GPT-3为例,它的参数达1750亿,具有超过28.5万个CPU核心、1万个GPU和400GB/s的GPU服务器网络传输带宽。训练一次GPT-3模型所需花费的算力成本超过460万美元,即使是基于开源大模型的fine-tuning成本也依然很高。
除了强大的算力,还有数据本身也是一项不小的投入,据统计GPT-3使用了3,000亿单词、超过40T的大规模、高质量数据进行训练。这些投入,对于广大的中小企业或个人来说都是不可逾越的挑战,大模型玩不起。
不过,在惊叹于大模型能力的同时,也有越来越多的小模型出现在了我们的视野中。这些小模型可能并没有像大模型那样复杂,但是它们同样具有着非常广泛的应用场景,且在计算资源和运行效率的消耗方面较小,需要的数据量也不大。因此,即便你玩不起那些大模型,选择小模型也是一种不错的选择。
例如,在金融机构,会有一些历史贷款用户的数据信息,这些信息可能包括,贷款人的收入水平、负债情况,贷款金额、期限、利率、还贷情况,甚至贷款人的工作职位、居住条件、消费习惯等等,根据这些信息我们就可以建立起一个预测用户贷款是否会发生违约的模型。这样,再碰到新的贷款客户,可以根据该客户的各项信息匹配规律,来确定当前客户违约的可能性有多大。当然,这种预测并不能保证 100% 准确(有很多种办法来评估它的准确率),所以如果只有一例目标(比如只有一笔贷款)需要预测时,那就没有意义了。但通常,我们都会有很多例目标需要预测,这样即使不是每一例都能预测正确,但能保证一定的准确率,这仍然是很有意义的。对于贷款业务,预测出来的高风险客户未必都是真的,但准确率只要足够高,仍然能够有效的防范风险。建立一个这样的小模型,不需要像GPT那样投喂海量的数据,几千几万条数据也能做出不错的模型,当然也不需要太多的算力,甚至一个笔记本也能跑。
事实上,这些小模型在很多实际的应用中表现得十分出色。例如产品的精准营销,信贷用户的风险评估,工业生产中的优化管理,医疗中的疾病诊断等等。很多常用的商业预测场景小模型都可以实现。
当然小模型也并不是天生就会生成出来的,也需要数据科学家的努力。首先在数学原理上和大模型类似,学习起来难度较大,需要专业的人才。其次建模过程也不是一蹴而就的,需要反复的调试和优化。再者,数据预处理过程也很复杂,比如数据噪音,缺失值,高偏度分布等等。除此之外,如果数据来源不同,或是比较原始,往往还需要做一些繁琐的准备工作。一套流程下来少则一两周,多则几个月,并且还需要数据科学家参与,费时费力。但是令人欣慰的是建立小模型有很多现成的自动化工具可以使用,借助工具一方面可以提高工作效率,一方面还可以降低建模人才的门槛。
SPL正是这样一款好用的工具,它具有可以全自动化建模的库,配置好建模外部库,通过简单的函数调用,就能实现自动建模。完全不需要花费时间去预处理数据和调试模型,普通程序员和建模小白都可以使用。在SPL中训练小模型,需要的数据也不多,几千几万条数据也能做点事情,几分钟就能跑好,简单方便。
以经典的泰坦尼克生存预测数据为例,通过简单的几句代码就可以建好模型:
A |
|
1 |
=file("titanic.csv").import@qtc() |
2 |
=ym_env() |
3 |
=ym_model(A2,A1) |
4 |
=ym_target(A3,"Survived") |
5 |
=ym_build_model(A3) |
然后可以查看模型表现:
A |
|
... |
|
6 |
=ym_present(A5) |
7 |
=ym_performance(A5) |
8 |
=ym_importance(A5) |
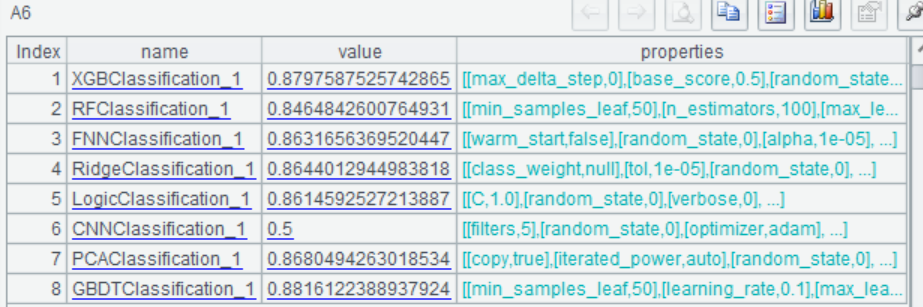
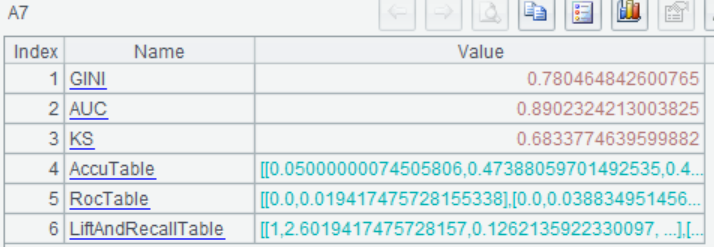
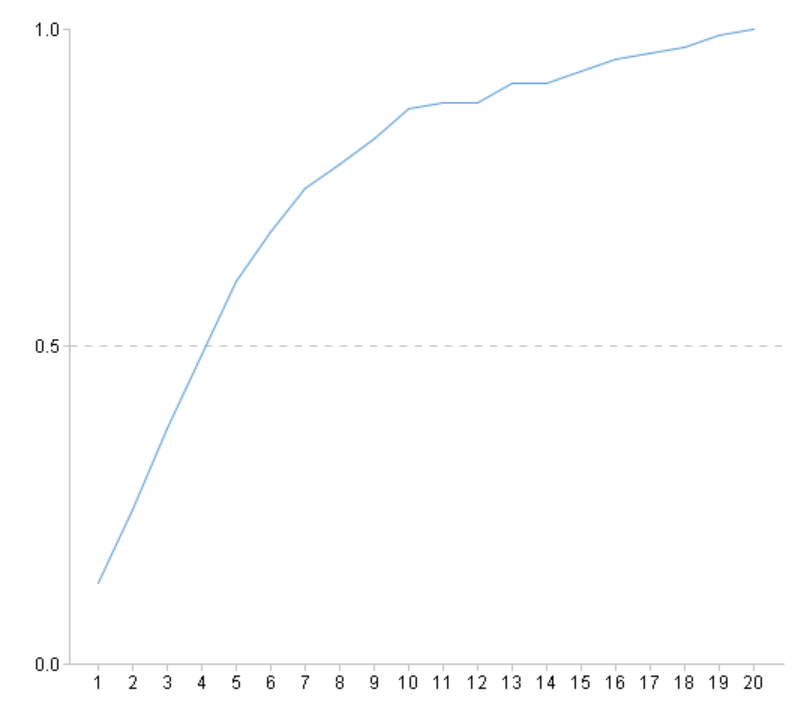
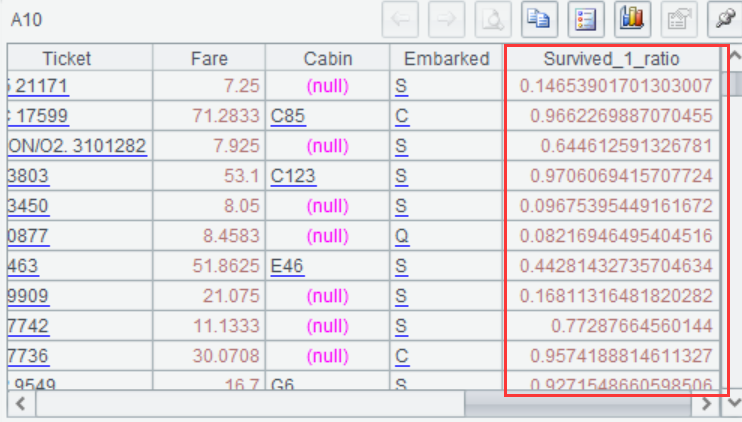
再使用模型进行预测,预测出每位乘客存活的概率:
A |
|
... |
|
9 |
=ym_predict(A5,A1) |
10 |
=ym_result(A9) |
完整过程可以参考:用 SPL 做数据挖掘建模预测 - 乾学院 (raqsoft.com.cn)
在很多实际业务中,SPL 建出的小模型效果都表现良好,为生产实践活动中提供了强有力的支持。
例如,银行有很多种金融产品,同时也有大量的用户,如何将合适的产品营销给合适的用户显得尤为重要。传统的营销方式效率低下,成功率也不高。因此银行希望充分挖掘潜力客户清单,推荐金融产品组合包,对目标客户进行多产品组合同步营销,从而夯实以客户为中心的经营体系,突出重点客群的综合经营。
我们采用银行的自有数据,包括用户的基本个人信息,资产情况,消费数据等等,
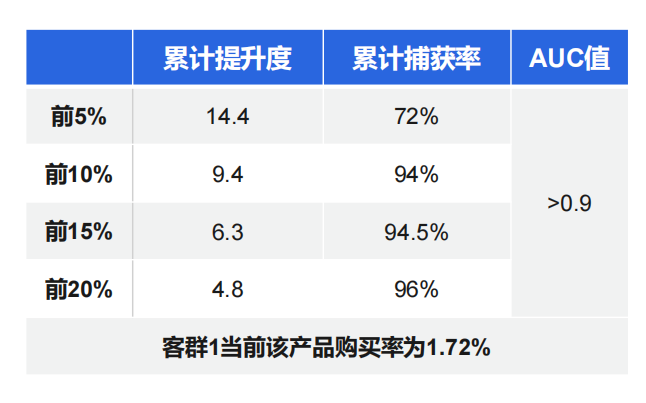
然后借助SPL 的自动建模功能,对多个客户群体(客户群体可以是百万人的大客群,也可以是几千人的小客群),多种目标产品进行建模后,成功预测出了重点客群的客户购买清单。以某客群为例,根据模型效果可将购买率提升 14.4 倍,在 5% 的数据上可以捕获 72% 的目标客户。经过实践,使用模型后日均增长额提高了 70 多倍。
再例如,车险市场竞争激烈,保险公司希望建立更精确的定价模型,帮助公司更精准的定位客户。一方面利用价格弹性以较低的溢价带来更多低风险客户,另一方面以更高的溢价阻止更多高风险客户,从而提高利润率。我们使用保单的基本信息以及历史出险情况等,对其建模,采用GLM和神经网络相结合的方法制定出新的定价模型,比原定价模型基于赔付的GINI表现提高了12%。显著提升了定价模型的表现,使得保险机构的收益最大化
在以上两个案例中,我们都使用了SPL的自动建模功能,数据预处理、模型选择和调参,模型评估等一系列流程都由软件自动完成,操作简单方便。
除此之外SPL还具备强大的结构化计算能力,交互式的编程方式,准备数据也十分方便,比SQL和Python用起来还简单。SPL 和 Python 应用于结构化数据处理的对比 - 乾学院 (raqsoft.com.cn)
总之,虽然大模型在很多方面的表现令人惊叹,但是我们同样不能忽视小模型的优秀表现。无论是在计算资源的消耗还是在实际应用场景上,小模型都可以成为我们的一个不错的选择。建立自己的大模型需要投入大量的时间、人力和资金,还要面对多个领域的挑战和困难。企业应根据自身的实际情况和需求来衡量选用哪种模型。


英文版