


自己训练模型,盘活历史数据
DT时代,数据作为一种资产越来越受到重视,各行各业都积累了不少的历史数据。然而沉淀的数据只是资源,只有用起来,数据的价值才能释放。如何盘活数据资产,让历史数据中的价值充分发挥显得尤为重要。
数据挖掘自然是必不可少的一种手段。例如,商家通过用户的历史消费行为,可以挖掘出用户的兴趣爱好,以便制定更精准的销售策略;工业生产中,通过挖掘历史产品的生产过程数据,可以优化生产工艺;医疗行业中,通过挖掘历史患者的病症和用药情况,可以帮助医生更加快速和精准的诊断疾病。总之,只要有历史数据,都可以通过数据挖掘来开发数据中的价值,盘活数据资产。
但是数据挖掘又是一个复杂的事情,首先历史数据有可能是来自不同系统的多源数据又或可能是原始交易流水数据,需要做一些ETL工作将其整理成一张宽表才能建模,这部分难度不大但是非常繁琐,如果有一个称手的工具,效率则会高很多。
其次,数据挖掘建模部分难度很大,通常需要有数据科学家的参与,普通人很难掌握。而且建模过程也不是一蹴而就的,即使是数据科学家也要根据自己的知识和经验反复的调试和优化,才能建好一个模型,短则几天,长则数月,费时费力。于是自动建模技术逐渐兴起。自动建模是将数据科学家的经验融入到软件产品中,由软件来完成数据预处理,模型选择调参,模型评估等一系列流程。自动建模一方面可以降低数据挖掘的门槛,普通程序员和小白也可建出好的模型,一方面还可以提高建模效率,原本需要几天或数月的模型,缩短为几小时或几天。使用自动建模技术,普通程序员或者业务人员可以随时利用手里的历史数据,自己训练模型,充分发掘数据中的价值,盘活历史数据。
那么,有没有什么好用的工具,能够让普通人也能借助自动建模技术,来训练自己的模型呢。
当然有,用SPL。
SPL是一款开源的,轻量级工具,它有一个非常专业的自动建模库Ymodel。在SPL里,通过简单的函数调用,就能实现自动建模。对于程序员来说,不需再要去学习如何预处理数据,也不需要学习各种复杂的算法原理和参数用途,只要对数据挖掘有一个概念的了解就能建出优质模型。对于数据科学家来说,则不必整日沉浸在反反复复处理数据,调试模型的工作中,很大程度上减少了人工的工作量,提高了工作效率。
例如,某金融公司有一些历史数据,包括用户的基本信息,资产信息,历史贷款记录,贷款产品信息等,那么根据这些数据就可以建立一个预测用户违约风险的模型。使用SPL代码如下:
A |
||
1 |
=file("train.csv").import@qtc() |
|
2 |
=ym_env() |
初始化环境 |
3 |
=ym_model(A2,A1) |
载入建模数据 |
4 |
=ym_target(A3,"y") |
设置预测目标 |
5 |
=ym_build_model(A3) |
执行建模 |
查看模型表现:
A |
||
... |
||
6 |
=ym_present(A5) |
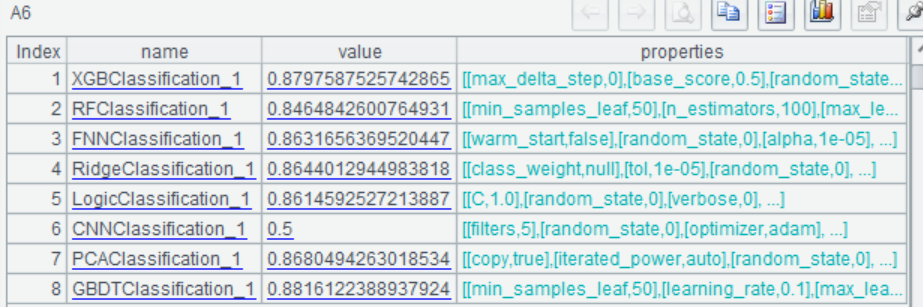
查看模型信息 |
7 |
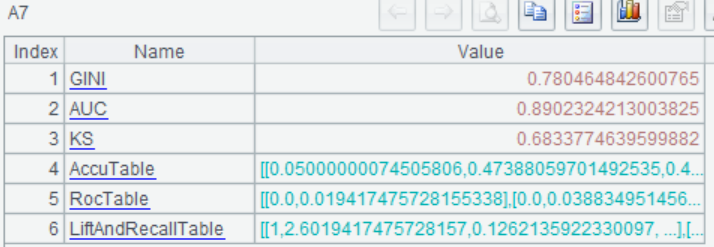
=ym_performance(A5) |
查看模型表现 |
8 |
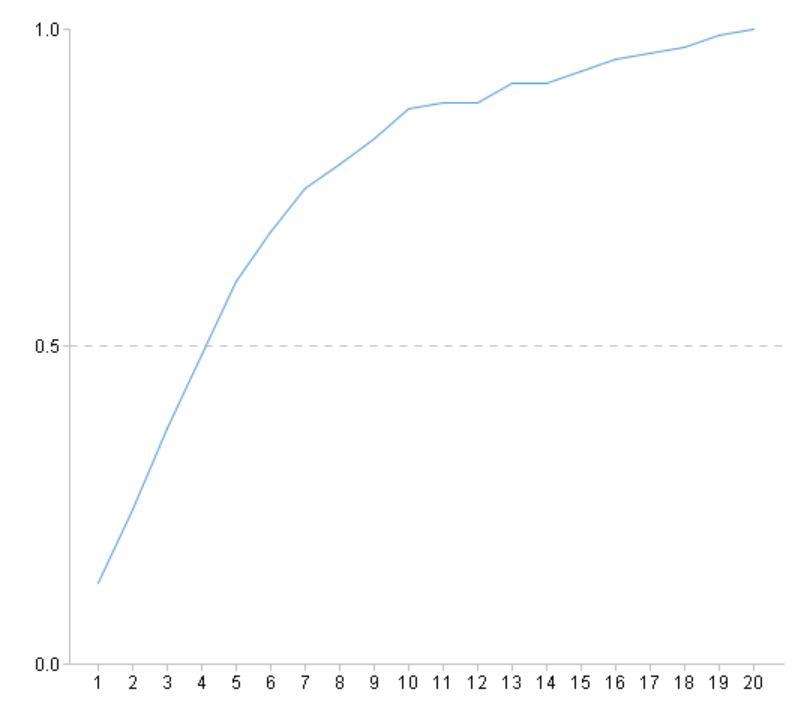
=ym_importance(A5) |
查看变量重要度 |
使用模型进行预测,预测出用户发生违约的概率:
A |
||
... |
||
9 |
=ym_predict(A5,A1) |
执行预测 |
10 |
=ym_result(A9) |
获取预测结果 |
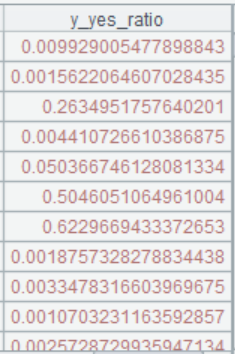
预测结果的概率值越大表示发生违约风险越高,进而业务人员可以根据预测结果很快的发现高风险客户,及时采取对应的措施降低坏账损失。而对于低风险的优质客户则可以加强营销,增加客户粘性创造更多的价值。
使用SPL,只需要调用几个函数就能够完成建模和预测过程。对于使用者来说没有复杂的数据预处理,没有晦涩难懂的算法原理和参数,通通由SPL来完成,建模新手和小白都能使用。
SPL建模不仅操作简单使用方便,而且不需要很大的数据量,几万几千条数据也能建模。一个小模型可能分分钟就能建好。使用者可以方便的使用手中的历史数据来训练模型,充分发掘历史数据中的价值,盘活历史数据,让数据真正成为资产,而不只是躺在仓库里的资源。
更加完整数据挖掘过程可以参考:用 SPL 做数据挖掘建模预测 - 乾学院 (raqsoft.com.cn)
除此之外SPL本身还是一个擅长结构化数据计算的工具,它有着丰富计算函数,优秀的大数据运算能力,用它做数据准备ETL工作也再合适不过,详情可参考SPL提效数据准备。


英文版