


有什么 JOIN 跑得快的数据库技术?
JOIN 一直是数据库性能优化的老大难问题,参与 JOIN 的大表越多,性能就越差。
想让 JOIN 跑得快,关键是要对 JOIN 分类,这样可以利用各种类型的特征来实施高效的提速方法。像 SQL 那样笼统地用一种方法定义所有 JOIN,简单是简单,但也没办法做性能优化了,所以常规的关系数据库通常都很难把 JOIN 跑快。
开源的集算器 SPL 对 JOIN 做了更细致的分类,针对每种类型设计不同高性能算法,可以大幅提高计算速度。SPL 程序员根据场景选择最合适的算法,就可以让 JOIN 跑的更快。
常见的外键关联,也就是用一个表的非主键字段,去关联另一个表的主键。前者可以简称为事实表,后者为维表。比如用订单表的客户号字段关联客户表、产品号字段关联产品表或者商户号字段关联商户表等等。
一般来说,订单表这样的事实表会随时间不断增长,数据量比较大,而维表的数据量不会太大。针对这种 JOIN,SPL 提供了外键序号化技术,预先将事实表中的维度字段转换为对应内存维表记录的序号。关联计算时,将事实表数据分批读入内存,用维度字段值(也就是维表序号),直接取内存维表对应位置的记录。
在相同的数据量和环境下,对比测试大事实表和小维表关联计算,SPL 比 Oracle 跑的快 3 到 8 倍:
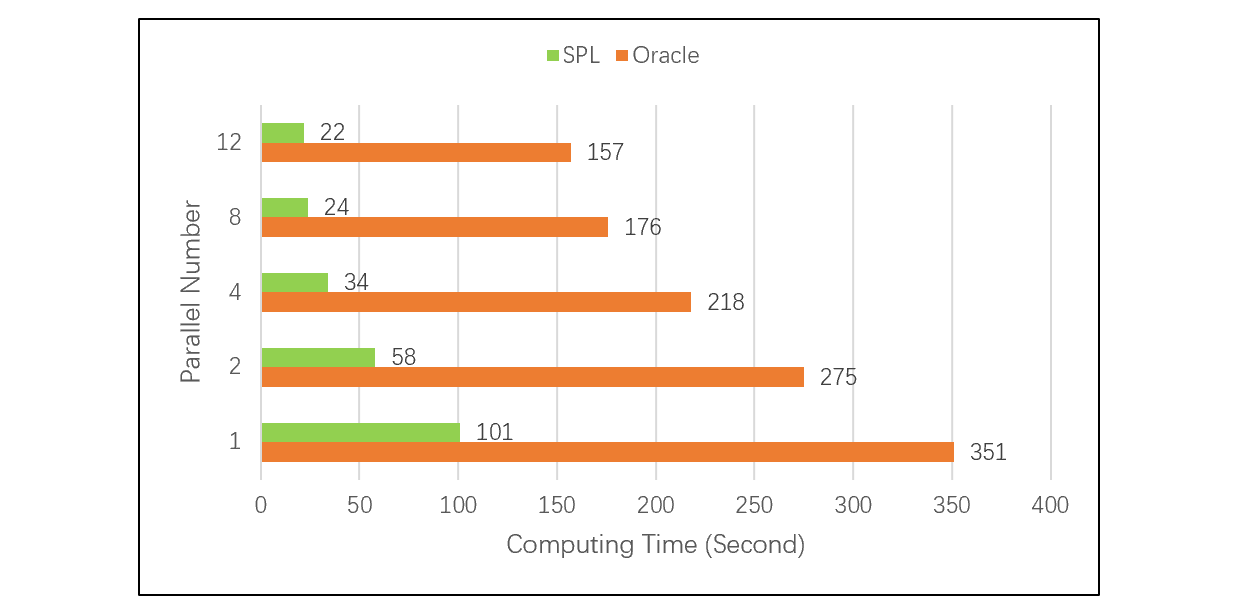
SPL 更快的原因,是外键序号化不需要像关系数据库那样计算和比对 HASH 值,从而加快了与维表关联的速度,有效提升了性能。
虽然预先把事实表的外键字段转换成序号需要一定成本,但这个预计算可以在多次外键关联中得到复用。
更详细信息可以参考:性能优化技巧:外键序号化
如果事实表和维表都很大,SPL 提供单边分堆技术,也比常规关系数据库的 JOIN 跑的更快,具体计算方法参见SPL 的单边分堆算法。这里同样有个大事实表和大维表的测试对比材料:性能优化技巧:大事实表与大维表关联,将其中结果抄录一下(单位秒):
事实表记录数 |
10亿 |
12亿 |
14亿 |
15亿 |
16亿 |
Oracle |
730 |
802 |
860 |
894 |
>10小时 |
SPL |
486 |
562 |
643 |
681 |
730 |
数据量能被内存装下时,Oracle 的计算速度基本上和数据量成正比。但当内存放不下时,开始发生大量占用 swap 区的现象,也造成计算速度奇慢,测试中等了 11 小时也没查询出来,只好终止了。而 SPL 的单边分堆技术,不受数据量大小的限制,本来就是面向外存设计,而且一次分堆就能解决,计算时间基本上随着数据量的增加而呈线性增加。
另外两种很常见的 JOIN,是一个表的主键关联另一个表的主键(或部分主键)。比如订单表和订单明细表通过订单号关联、客户表和 VIP 客户表通过主键关联等。针对这种 JOIN,SPL 提速的方法是:预先将两个大表按照主键有序存储,采用有序归并实现关联。
有序归并算法只需要对两个表依次遍历,不必借助外存缓存,可以大幅降低 IO 量。而且,其算法复杂度是加法级的,相比关系数据库乘法级的 HASH JOIN,复杂度降低很多,性能会大幅提升。
在相同情况下,我们对订单和订单明细两个大表按照订单号关联测试(详情参见性能优化技巧:有序归并),结果是 SPL 比 Oracle 快了近 3 倍:
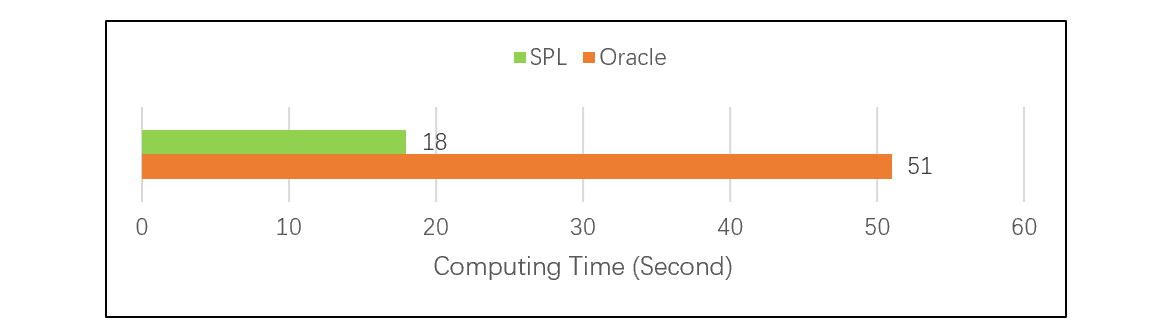
这类 JOIN 的两表之间只会按主键(或部分主键)关联,不会针对其它字段关联。预先按照主键排序虽然慢,但是一次性的,而且只需要保持主键有序这一种存储即可,不会出现冗余。
除这些方法之外,SPL 还提供了大维表查找、内存预关联等等适应不同场景的 JOIN 提速方法,可以全面的解决 JOIN 性能优化问题,有兴趣请参考乾学院的其他相关文章。


英文版