


SPL 的单边分堆算法
两个大表做关联,常常会出现性能问题。其中比较常见的一种情况,是用一个大表的非主键字段,去关联另一个大表的主键。例如:订单表 orders 和客户表 customer 都很大,内存无法装下。订单表(以下称为事实表)用客户号 cid 字段,去关联客户表(以下称为维表)的主键。这两个表和内存的大小关系,可以用图 1 直观的表示:
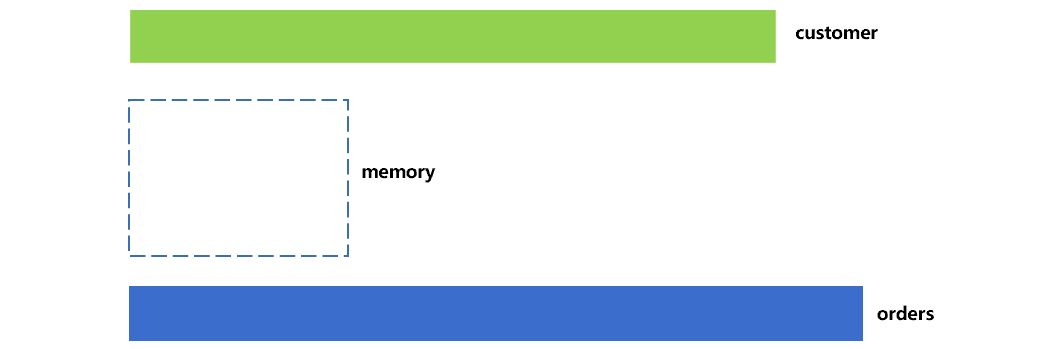
图 1
实际应用中,这两个数据表要比内存大很多。图 1 只是示意图,缩小了这个差距。
如果两个表中有一个比较小,可以将其全部读入内存,再和另一个大表的数据分批关联。但是这里的两个表都比较大,就不能这样做了。
如果将两个大表都按照关联字段预先排序,再做有序归并连接,是可以完成这个计算的。但是,事实表还可能有其他字段关联另外的大表,比如订单表用产品号关联产品表、用商户号关联商户表等等。不可能让一个事实表同时针对多个字段都有序。所以,这个办法也不适用。
对于这种情况,数据库一般采用哈希分堆的方法。即分别计算两个表中关联字段的哈希值,将哈希值在一定范围的数据分到一堆,形成外存的缓存数据,保证每一堆都足够小可以装入内存,然后再逐个针对每一对堆(两个表)执行内存连接算法。这种方法会将两个大表都拆分缓存,也可以称为双边分堆方法。在哈希函数运气不好时,还可能发生某一堆过大而要再做第二轮哈希的情况。
针对这种很难提速的场景,SPL 提供单边分堆方案,可以尽量计算的更快。实施单边分堆算法,要预先将维表按主键有序存储。连接计算时,SPL 先将维表分段。分段数是按照维表大小和内存容量计算出来的,要让每一段都可以装入内存。以客户表为例,大致是图 2 这样:

图 2
假设我们将客户表分为 4 段。由于客户表按主键有序存储,所以查出每一段第一条记录的 cid 值,cid0 到 cid3,即可确定 4 段数据的 cid 取值范围。预先将维表按照主键有序存储的作用就体现在这里:分为 n 段时,只要查出 n 条记录就能快速确定每段主键取值的范围。
接下来,按照 cid 的这 4 个范围,将订单表拆分生成 4 个临时缓存 orders1 到 orders4。示意如下:
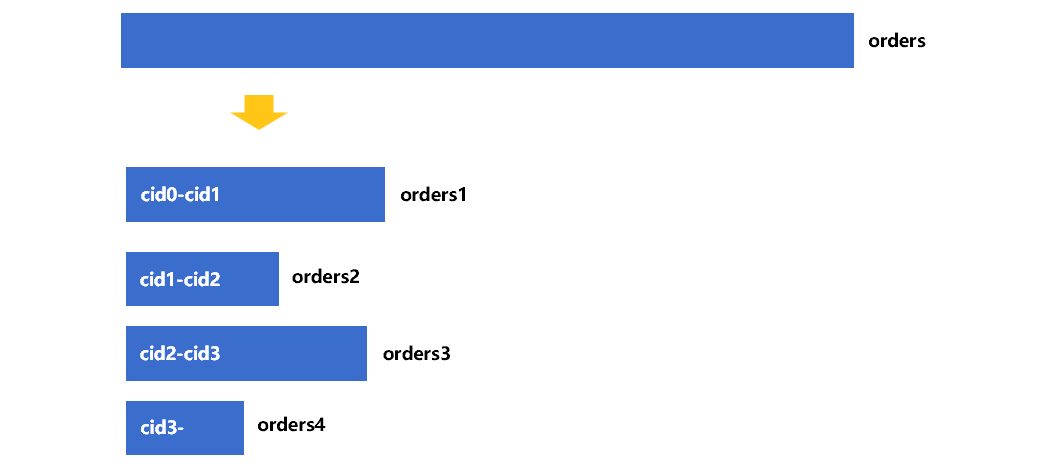
图 3
正如图 3 中标注的,事实表缓存 orders1 中的 cid 都在 cid0 和 cid1 之间,另外三个缓存的 cid 范围也是确定的。这时,我们可以保证 orders1 到 orders4 中记录对应的客户号,分别在客户表的 part1 到 part4 中。所以,可以用内存中的维表分段和对应的事实表缓存游标做连接。大致过程如图 4:
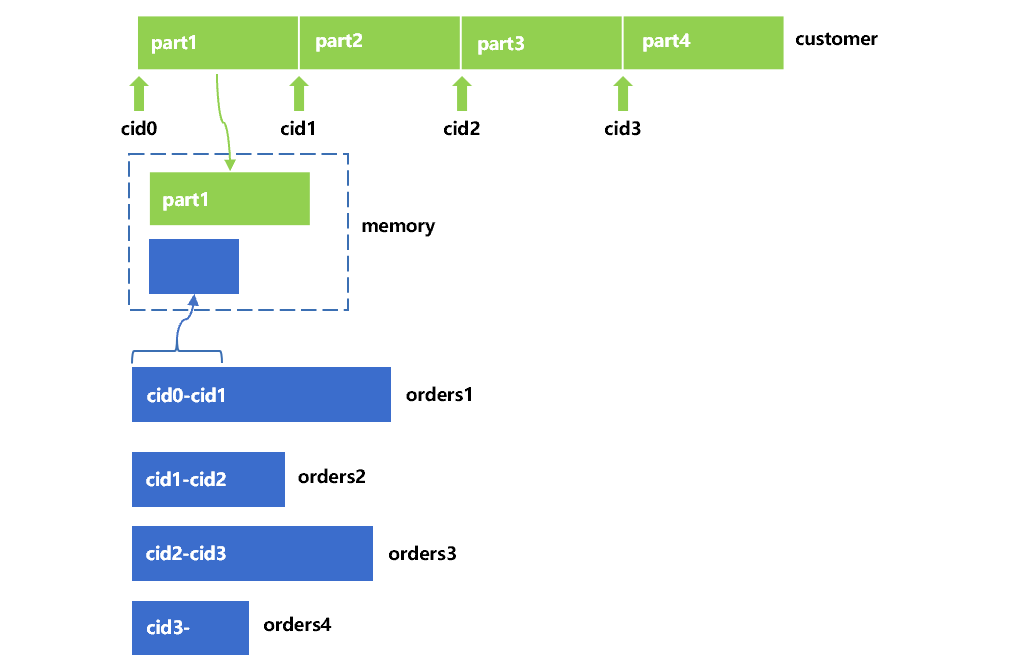
图 4
SPL 先将客户表的 part1 读入内存,和 orders1 的游标做连接,结果以游标方式输出。完成之后再依次做剩下三对事实表缓存和维表分段的连接,就可以得到结果游标。
看起来,SPL 单边分堆的整体过程和双边分堆差不多。不同之处在于,SPL 将维表分段就相当于在逻辑上完成了分堆,每一段就是一堆。不需要再生成维表分堆的缓存了,只需要将事实表分堆就可以,所以我们称为单边分堆。而且,这种办法可以将维表平均分段,不会出现运气不好要二次哈希分堆的情况。可能某一个事实表的分堆太大,比如 orders1。但这时候可以执行图 4 中的维表分段装入内存,与事实表缓存游标分批连接的算法,也不需要二次分堆。单边分堆算法的缓存数据量要比双边分堆少得多,性能也会更优。
SPL 将单边分堆算法做了封装:
A |
|
1 |
=file("customer.btx") |
2 |
=file("orders.btx").cursor@b(cid,amount) |
3 |
=A2.joinx@u(cid,A1:cid,area,discount) |
4 |
=A3.groups(area;amount*discount) |
使用joinx@u 函数,SPL 即认为事实表也很大,需要做分堆处理。由于维表需要被分段访问,所以要以数据文件的方式出现,而不能是游标。
joinx@u 返回的游标,不再对事实表的主键有序。从图 4 描述的算法可知,SPL 会按维表的分段逐个取出做连接后返回,总体次序应该和维表主键相同。但对于每一段又会以事实表分堆的次序,这一段内并不一定按维表主键有序,总体看起来就是无序的。
通常事实表是对主键有序的,有时还需要利用这个次序做下一轮计算,所以关联结果也要保持有序。我们把 @u 选项去掉,结果就会按照事实表主键有序了。这时候,SPL 会生成一个原事实表中记录的序号,在分堆缓存时按这个序号排序后再写入。做完每一对事实表缓存和维表分段的连接后,还要再次写成缓存。然后将后一轮的所有缓存按原序号做归并排序。这样相当于比 joinx@u 多做一次大排序,性能会更慢一些,但是可以在后续计算中利用事实表有序的特征提升性能。
实际测试证明了单边分堆在性能上的优势。对于大事实表、大维表的关联,在相同数据量和计算环境下,SPL 和 Oracle 数据库对比测试的结果是这样的(时间单位秒):
事实表记录数 |
10亿 |
12亿 |
14亿 |
15亿 |
16亿 |
Oracle |
730 |
802 |
860 |
894 |
>10小时 |
SPL |
486 |
562 |
643 |
681 |
730 |
经测算,10 亿行数据正常情况已经超过机器内存,但 Oracle 可能采用了某种压缩技术,一直能装下 15 亿行数据。但是在 16 亿行数据时,内存就怎么也放不下了,开始发生大量占用 swap 区的现象,也造成运行速度奇慢,测试中等了 11 小时也没查询出来,只好终止了。而 SPL 的单边分堆技术,不受数据量大小的限制,本来就是面向外存设计,而且一次分堆就能解决,计算时间基本上随着数据量的增加而呈线性增加。
详细测试数据、环境等,请参考:性能优化技巧:大事实表与大维表关联


英文版