


Java 报表工具的数据源不能用 SQL 计算时该怎么办?
解决办法:esProc - Java 专业计算包
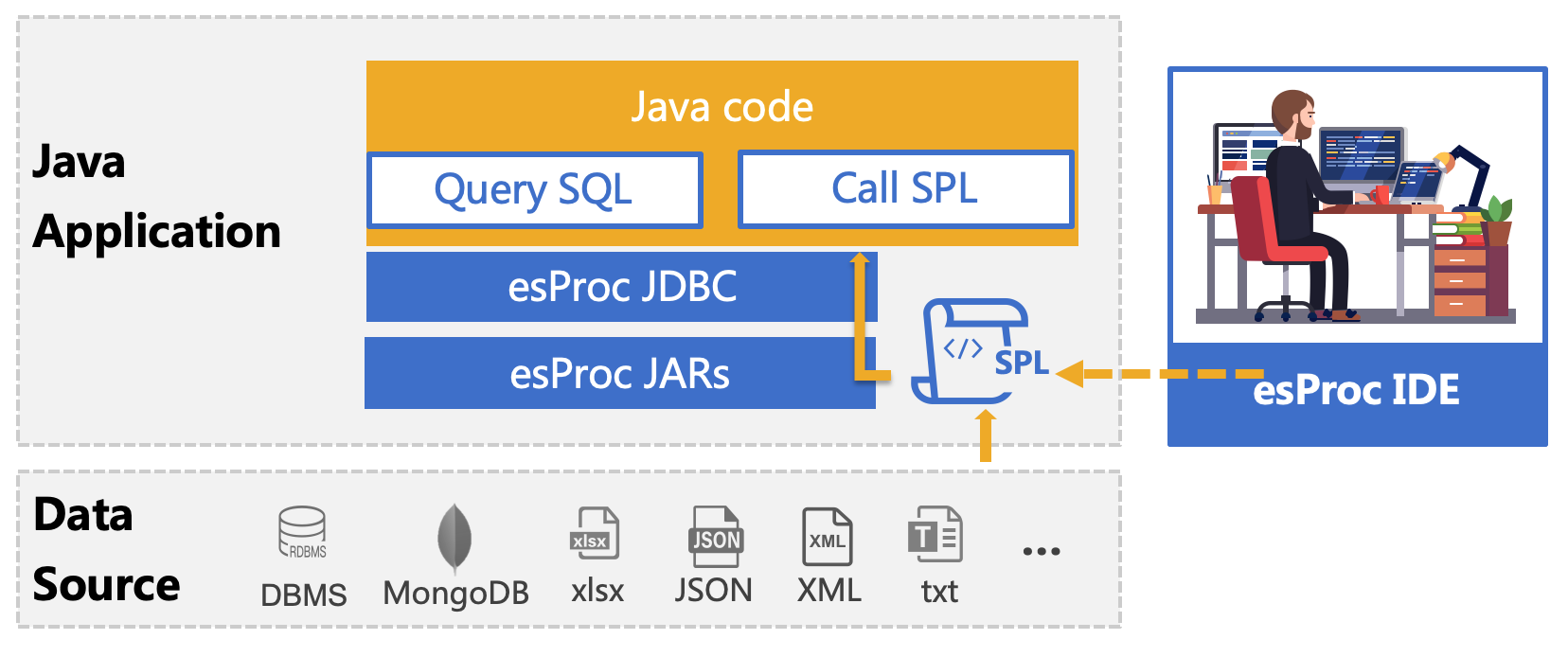
esProc 是专门用于基于 Java 计算的类库,旨在简化 Java 代码,提供不依赖数据库的计算能力,在实际应用中,经常用来解决报表开发中的复杂问题。 SPL 是基于 esProc 计算包的脚本语言,和 Java 程序一起部署,可以理解为库外存储过程,用法和 Java 程序中调用存储过程相同,通过 JDBC 接口传递给 Java 程序执行,实现分步式结构化计算,返回 ResultSet 对象。
现代报表的数据源并不只是数据库,还可能是文本文件或 json、XML 等。这些非数据库数据源没有再计算能力,但生成报表时总还是需要再进行一些过滤分组甚至多表连接等运算,报表工具本身的计算能力不足,一般都不能很好地处理 json 和 XML 数据,即使针对能进行简单处理的结构化文本,由报表工具运算也也会造成容量负担过重的问题。因此,我们经常会有一个过程把这些非数据库数据导入到数据库再去生成报表,增加开发工作量。
集算器自有的计算能力可以使这些计算能力不一的多样性数据获得通用一致的计算能力。比如文件几乎没有计算能力,MongoDB 对 JOIN 和 GROUP 运算支持不足,各家数据库对窗口函数的支持程度不同、日期与字串处理能力也普遍不足且风格迥异。采用集算器后可以用相对一致的方案来计算,而这将意味着更低的移植成本以及学习难度。
文本数据源
绝大多数报表工具可以导入结构化文本实施计算列、分组排序等运算。但是,报表工具是把所有计算表达式写在报表布局上,在计算依赖关系较为复杂,要分多步骤实施计算,经常需要借用隐藏格,很难一目了然地了解运算目标。如果采用集算器就会容易得多,数据准备在专门的计算单元完成,报表只负责呈现及少量的直观计算,应用结构更为清晰。先举一个简单的例子,然后介绍如何搭配报表工具使用。
比如:找出英语平均分低于70分的班级。
A |
|
1 |
=T(“E:/txt/Students_scores.txt”) |
2 |
=A1.groups(CLASS;avg(English):avg_En) |
3 |
=A2.select(avg_En<70) |
集算器与 Java 报表开发工具搭配也非常简单。以报表工具 Birt 为例,把 esProc 核心 jar 包和相关数据库驱动 jar 包,拷贝至 Birt 开发环境 [安装目录]\plugins\org.eclipse.birt.report.data.oda.jdbc_4.6.0.v20160607212 下(不同 Birt 版本略有不同)。
Birt 开发工具内新建报表,并增加 esProc 数据源“esProcConnection”

新建“Data Sets”,选择配置的集算器数据源(esProcConnection),数据集类型选择存储过程(SQL Stored Procedure Query)

查询脚本(Query-Query Text)输入:{call VerticaExternalProcedures()},其中,VerticaExternalProcedures 为 SPL 脚本文件名

Finish,预览数据(Preview Results)

更多 Java 报表集成详细参见: BIRT 调用 SPL 脚本 和 JasperReport 调用 SPL 脚本
用 SPL 实现多文本关联计算:
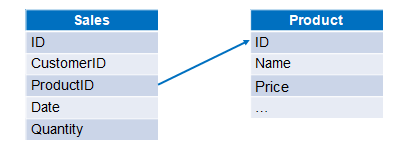
比如:销售订单信息和产品信息分别存储在两个文本文件中,计算各订单的销售额。两个文件数据结构如下图:
A |
|
1 |
=T(“e:/orders/sales.csv”) |
2 |
=T(“e:/orders/product.csv”).keys(ID) |
3 |
=A1.join(ProductID,A2,Name,Price) |
4 |
=A3.derive(Quantity*Price:amount) |
一个目录里有很多相同结构的文本,用 SPL 合并后查询汇总同样十分简单:
| A | |
| 1 | =directory@p("./"+user+"/*.csv") |
| 2 | =A1.conj(file(~).import@tc()) |
| 3 | =A2.groups('Customer ID':CID,year('Purchase Date'):Year; 'Customer Name':Customer,sum('Sale Amount'):Total,round(avg('Sale Amount'),1):Average) |
| 4 | =A3.select(Year==when).new(Customer,Total,Average) |
SPL 中提供了完善的用 SQL 查询文件数据的方法:
比如:州信息,部门信息和员工信息分别存储在3个文本文件中,查询经理在California州的New York州员工。
A |
|
1 |
$select e.NAME as ENAME from E:/txt/EMPLOYEE.txt as e join E:/txt/DEPARTMENT.txt as d on e.DEPT=d.NAME join E:/txt/EMPLOYEE.txt as emp on d.MANAGER=emp.EID where e.STATE='New York' and emp.STATE='California' |
Excel 数据源
SPL 中有完善的 Excel 文件处理函数,进行结构化解析及后续的计算等操作非常方便。比如,用 SPL 读取 Excel 数据做条件查询,只要写两行代码:
A |
|
1 |
=file("simple.xls").xlsimport@t() |
2 |
=A1.select(amount>500 && amount<=2000) |
许多 Excel 文件的格式并不规整,提取数据编程结构化的工作量比较大,而且很难通用。比如,把主表信息附加在每条子表记录中,订单明细列表 order.xlsx 中数据如下图所示:

编写SPL脚本:
A |
|
1 |
=file("E:/work/order.xlsx").xlsopen() |
2 |
=A1.xlsimport@t(;1,5).select(Model) |
3 |
=A2.derive(A1.xlscell("D2"):Name,A1.xlscell("F2"):Phone,A1.xlscell("D3"):Email,A1.xlscell("D4"):Address) |
A1 打开order.xlsx文件为Excel对象
A2 读取A1第1个Sheet中第5行开始的行式数据,并过滤掉Model为空的行,选项@t表示首行是列标题
A3 在A2新增4列:Name列的值为D2单元格内容,Phone列的值为F2单元格内容,Email列的值为D3单元格内容,Address列的值为D4单元格内容
A3格的最终结果如下图所示:

Json 数据源
一般报表工具使用的数据集都是类似 SQL 返回的那种单层二维表,碰到象 Json 或 XML 这类多层数据只能先转换成多个单层数据集,再在报表模板中关联运算拼接成多层报表。而 SPL 可以直接支持多层数据集计算,不需要做这个转换,减少工作量,报表也可以接受 SPL 返回的多层数据集直接按层次呈现,不需要在报表中再做关联。
文件 EO.json 存储一批员工信息,以及属于员工的多个订单,部分数据如下:
[{
"_id": {"$oid": "6074f6c7e85e8d46400dc4a7"},
"EId": 7,"State": "Illinois","Dept": "Sales","Name": "Alexis","Gender": "F","Salary": 9000,"Birthday": "1972-08-16",
"Orders": [
{"OrderID": 70,"Client": "DSG","SellerId": 7,"Amount": 288,"OrderDate": "2009-09-30"},
{"OrderID": 131,"Client": "FOL","SellerId": 7,"Amount": 103.2,"OrderDate": "2009-12-10"}
]
}
{
"_id": {"$oid": "6074f6c7e85e8d46400dc4a8"},
"EId": 8,"State": "California", ...
}]
用 SPL 条件查询实现如下:
A |
|
1 |
=json(file("D:\\data\\EO.json").read()) |
2 |
=A1.conj(Orders) |
3 |
=A2.select(Amount>500 && Amount<=2000 && like@c(Client,"*bro*")) |
上面代码先将Json读为多层的序表对象,再用conj函数合并所有订单,之后用select函数完成条件查询。
Json 数据经常是 REST API 返回 的数据,比如部分数据格式如下:
[
{
"id": 1000,
"content": "It is too hot",
"comment": [
{
"author": "joe",
"score": 3,
"comment": "just so so!"
},
{
"author": "jimmy",
"score": 5,
"comment": "cool! good!"
}
]
}
...
]
用 SPL 解析 REST API 实现如下:
| A | |
|---|---|
| 1 | =httpfile(“http://yourapi/endpoint/servlet/testServlet?table=blog&type=json”) |
| 2 | =json(file(A1).read()) |
| 3 | =A2.news(comment;id,content,${A2.comment.fname().concat@c()}) |
解析后的结果如下:

XML 数据源
文件 Employees_Orders.xml 存储一批员工信息,以及属于员工的多个订单,部分数据如下:
<?xml version="1.0" encoding="UTF-8"?>
<xml>
<row>
<EId>2</EId>
<State>"New York"</State>
<Dept>"Finance"</Dept>
<Name>"Ashley"</Name>
<Gender>"F"</Gender>
<Salary>11000</Salary>
<Birthday>"1980-07-19"</Birthday>
<Orders>[]</Orders>
</row>
<row>
<EId>3</EId>
<State>"New Mexico"</State>
<Dept>"Sales"</Dept>
<Name>"Rachel"</Name>
<Gender>"F"</Gender>
<Salary>9000</Salary>
<Birthday>"1970-12-17"</Birthday>
<Orders>
<OrderID>32</OrderID>
<Client>"JFS"</Client>
<SellerId>3</SellerId>
<Amount>468.0</Amount>
<OrderDate>"2009-08-13"</OrderDate>
</Orders>
<Orders>
<OrderID>39</OrderID>
<Client>"NR"</Client>
<SellerId>3</SellerId>
<Amount>3016.0</Amount>
<OrderDate>"2010-08-21"</OrderDate>
</Orders>
<Orders>
</row>
…
<xml>
用 SPL 解析如下:
A |
|
1 |
=xml(file("D:\\xml\\Employees_Orders.xml").read(),"xml/row") |
2 |
=A1.conj(Orders) |
3 |
=A2.select(Amount>100 && Amount<=3000 && like@c(Client,"*bro*")) |
上面代码先将 XML 读为多层的序表对象,再用 conj 函数合并所有订单,之后用 select 函数完成条件查询。
MongoDB 数据源
esProc 也是专业的结构化计算引擎,可以用统一的语法和数据结构计算多种 NOSQL 数据源,其中就包括 MongoDB。比如对多层 collection 进行条件查询 SPL 代码如下:
A |
|
1 |
=mongo_open("mongodb://127.0.0.1:27017/mongo") |
2 |
=mongo_shell(A1,"test1.find()") |
3 |
=A2.conj(Orders) |
4 |
=A3.select(Amount>1000 && Amount<=3000 && like@c(Client,"*s*")).fetch() |
5 |
=mongo_close(A1) |
从A2可以看出来,esProc支持MongoDB的json查询表达式(find、count、distinct和aggregate),比如区间查询写作:=mongo_shell(A2,"test1.find({Orders.Amount:{$gt:1000,$lt:3000}})")。
类似地,分组汇总代码如下:
A |
|
1 |
=mongo_open("mongodb://127.0.0.1:27017/mongo") |
2 |
=mongo_shell(A1,"test1.find()") |
3 |
=A2.conj(Orders).groups(year(OrderDate);sum(Amount)) |
4 |
=mongo_close(A1) |
关联查询代码如下:
A |
|
1 |
=mongo_open("mongodb://127.0.0.1:27017/mongo") |
2 |
=mongo_shell(A1,"test1.find()") |
3 |
=A2.new(Orders.OrderID,Orders.Client, Name,Gender,Dept).fetch() |
4 |
=mongo_close(A1) |
更多数据源
除了上述数据源,集算器还可以访问 ElasticSearch、Spark、HBase、Redis、Cassandra、SAP、Kafka、HDFS 文件系统等
部署和连接参阅详情 集算器外部库


英文版