


Java 报表工具的多源混算难题该怎么解?
解决办法:esProc - Java 专业计算包
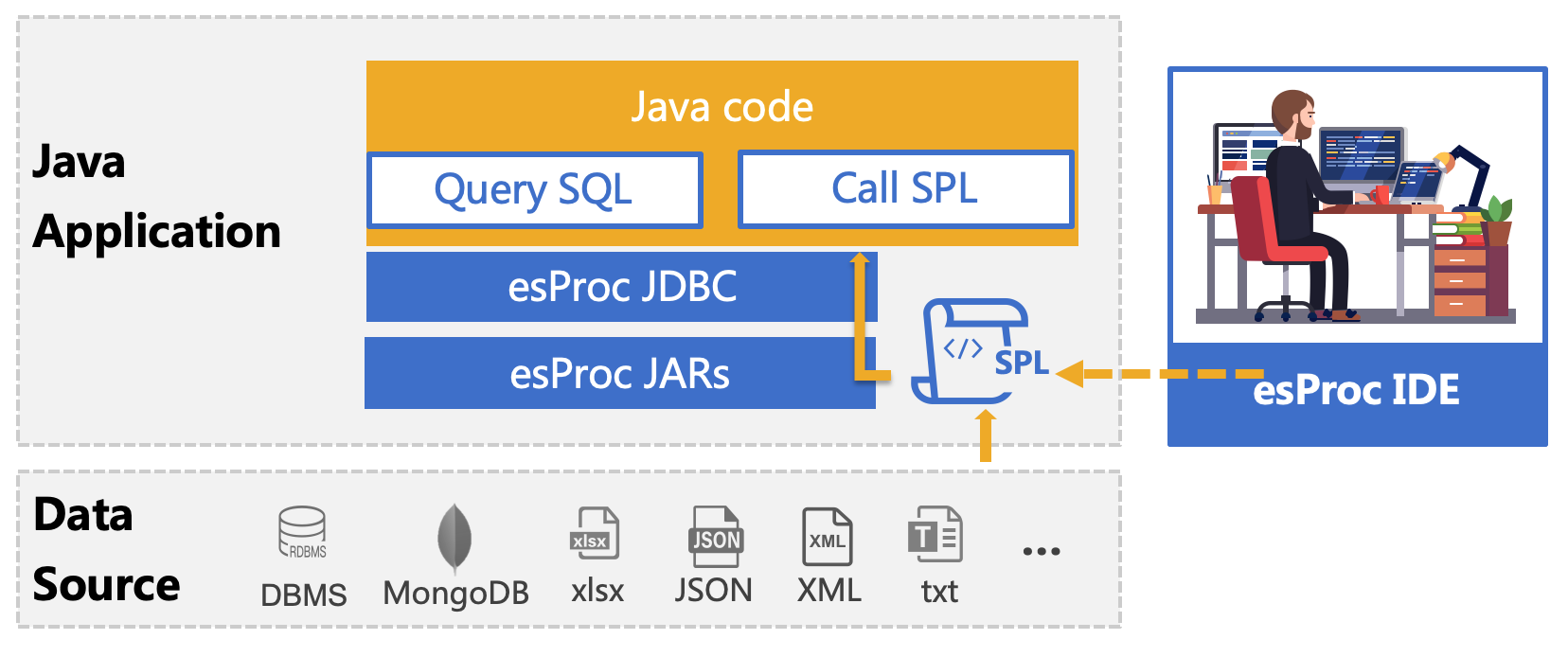
esProc 是专门用于基于 Java 计算的类库,旨在简化 Java 代码,提供不依赖数据库的计算能力,在实际应用中,经常用来解决报表开发中的复杂问题。 SPL 是基于 esProc 计算包的脚本语言,和 Java 程序一起部署,可以理解为库外存储过程,用法和 Java 程序中调用存储过程相同,通过 JDBC 接口传递给 Java 程序执行,实现分步式结构化计算,返回 ResultSet 对象。
同构数据汇总
许多数据库都支持跨库运算,但一般都要求同类型的数据库,通过将另一个库中的数据表映射成本库数据表或专门的计算网关完成。集算器类库是嵌入式的计算引擎,用多线程向各数据库同时发出 SQL 语句,由这些数据库并行执行,将各自的运算结果返回到集算器再汇总处理后提供给应用程序。
某电信企业用库表 userService 存储用户服务信息, 分地区存储于多个数据库, 用 SPL 脚本完成数据汇总如下:
A |
B |
|
| 1 | [mysql1,mysql2,mysql3,mysql4] |
|
| 2 | fork A1 | =connect(A2) |
| 3 | =B2.query@x("select product_no,sum(allDuration) sallDuration,sum(allTimes) sallTimes,sum(localDuration) slocalDuration ,sum(localTimes) slocalTimes from userService where I0419=? group by product_no", argType) | |
| 4 | =A2.conj() | |
| 5 | =A4.groups(product_no;sum(sallDuration):ad,sum(sallTimes):at,sum(slocalDuration):ld,sum(slocalTimes):lt) | |
语句 fork 并行开启四线程,每线程从对应的数据库取数,并将分组汇总的结果返回主线程。主线程合并各子线程计算结果,再次执行分组汇总,返回最终结果集。如果直接用 Java 工具完成,只能在一个线程里顺序取数,然后在报表层做数据合并、分组等数据计算,数据到了报表层就没法像专业计算类库里能通过高级算法做好性能优化工作。
SPL 与 Java 报表开发工具集成也非常简单。以报表工具 Birt 为例,把 esProc 核心 jar 包和相关数据库驱动 jar 包,拷贝至 Birt 开发环境 [安装目录]\plugins\org.eclipse.birt.report.data.oda.jdbc_4.6.0.v20160607212 下(不同 Birt 版本略有不同)。
Birt 开发工具内新建报表,并增加 esProc 数据源“esProcConnection”

新建“Data Sets”,选择配置的集算器数据源(esProcConnection),数据集类型选择存储过程(SQL Stored Procedure Query)

查询脚本(Query-Query Text)输入:{call VerticaExternalProcedures()},其中,VerticaExternalProcedures 为 SPL 脚本文件名

Finish,预览数据(Preview Results)

更多 Java 报表集成详细参见: BIRT 调用 SPL 脚本 和 JasperReport 调用 SPL 脚本
如果数据表相同,但数据库类型不同,通过 SPL 可以执行相同的 SQL 语句:
A |
|
1 |
>sql="SELECT * FROM sales WHERE WEEKOFYEAR(orderdate) = 35" |
2 |
>dbname=["oracle","mysql"] |
3 |
>dbtype=["ORACLE","MYSQL"] |
4 |
=dbname.(connect@l(~)) |
5 |
=dbtype.(sql.sqltranslate(~)) |
6 |
=A4.conj(~.query@x(A5(#))) |
如果数据量较大,SPL 还有游标读取的方式,可以在游标上绑定计算,比如按 Employees 表的 Dept 字段分组,对 Orders 表的 Amount 字段汇总,在游标上实现了关联和分组计算,可以利用小内存完成大数据计算。
A |
|
1 |
=orcl.cursor("select EId, Dept from Employees order by EId") |
2 |
=mysql1.cursor("select SellerId, Amount from Orders order by SellerId") |
3 |
=joinx(A2:O,SellerId; A1:E,EId) |
4 |
=A3.groups(E.Dept;sum(O.Amount)) |
异构数据关联
数据还常常会来自于多种异构数据源,例如:关系型数据库(oracle、db2、mysql)、nosql 数据库(mongodb)、http 数据源、hadoop(hive、hdfs),甚至是 excel 或者文本文件,通常需要将所有数据集中到一个数据库中再进行计算,会增加很多工作量。如果使用 SPL 实现异构数据关联,不仅可以保持现有数据存储流程不变,开发工作量也很小。SPL 具有丰富的结构化算法,很容易实现关联查询以及后续的计算,经常比 SQL 还简单。
比如,销售系统的数据存储于 mongoDB,和来自于 DB2 数据库的销售员信息表,混合计算示例如下:
| A | |
|---|---|
| 1 | >hrdb=connect(“db22”) |
| 2 | =hrdb.query(“select * from employee where state=?”,state) |
| 3 | =mongodb(“mongo://localhost:27017/test?user=test&password=test”) |
| 4 | =A3.find(“orders”,,“{_id:0}”).fetch() |
| 5 | =A4.switch@i(SELLERID,A2:EID) |
| 6 | =A5.new(ORDERID,CLIENT,SELLERID.NAME:SELLERNAME,AMOUNT,ORDERDATE) |
| 7 | >hrdb.close() |
| 8 | >A3.close() |
| 9 | result A6 |
再比如,文本与 JSON 关联,sales.txt 是 tab 分割的结构化文本,city.json 是非结构化的 JSON 串,sales.txt 的第 2 列和 city.json 的部分文本存在外键关系,需要将两个文件连接为二维表。
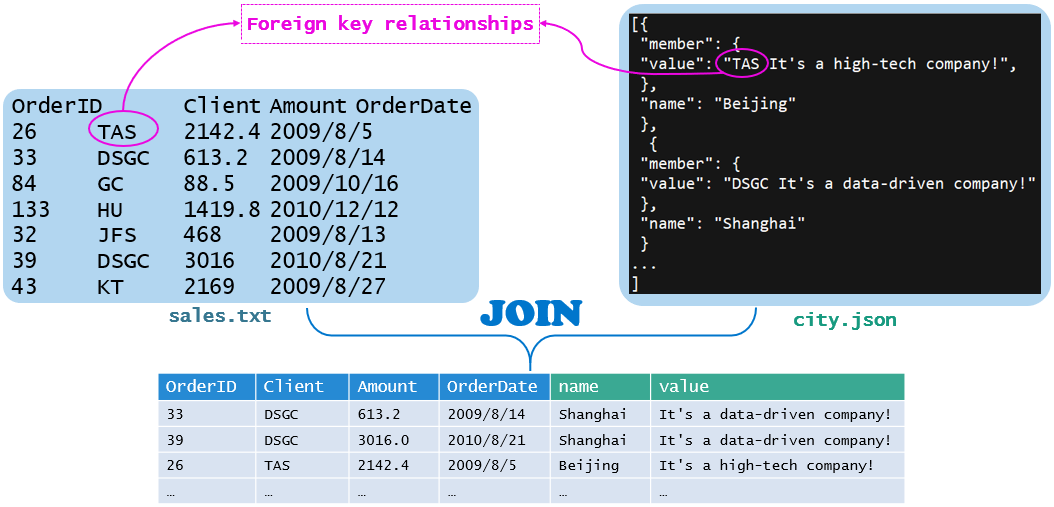
SPL 代码实现如下:
| A | |
|---|---|
| 1 | =json(file(“/workspace/city.json”).read()) |
| 2 | =A1.new(name,#1.(#1):desc,(firstblank=pos(desc," "),left(desc,firstblank-1)):key,right(desc,len(desc)-firstblank):value) |
| 3 | =file(“/workspace/sales.txt”).import@t() |
| 4 | =join(A3:sales,#2;A2:city,key) |
| 5 | =A4.switch@i(SELLERID,A2:EID) |
| 6 | =A4.new(sales.OrderID,sales.Client,sales.Amount,sales.OrderDate,city.name,city.value) |
更多 SPL 应用
参见 SPL 应用计算


英文版