


Java 报表工具里写复杂 SQL 困难时该怎么办?
解决办法:esProc - Java 专业计算包
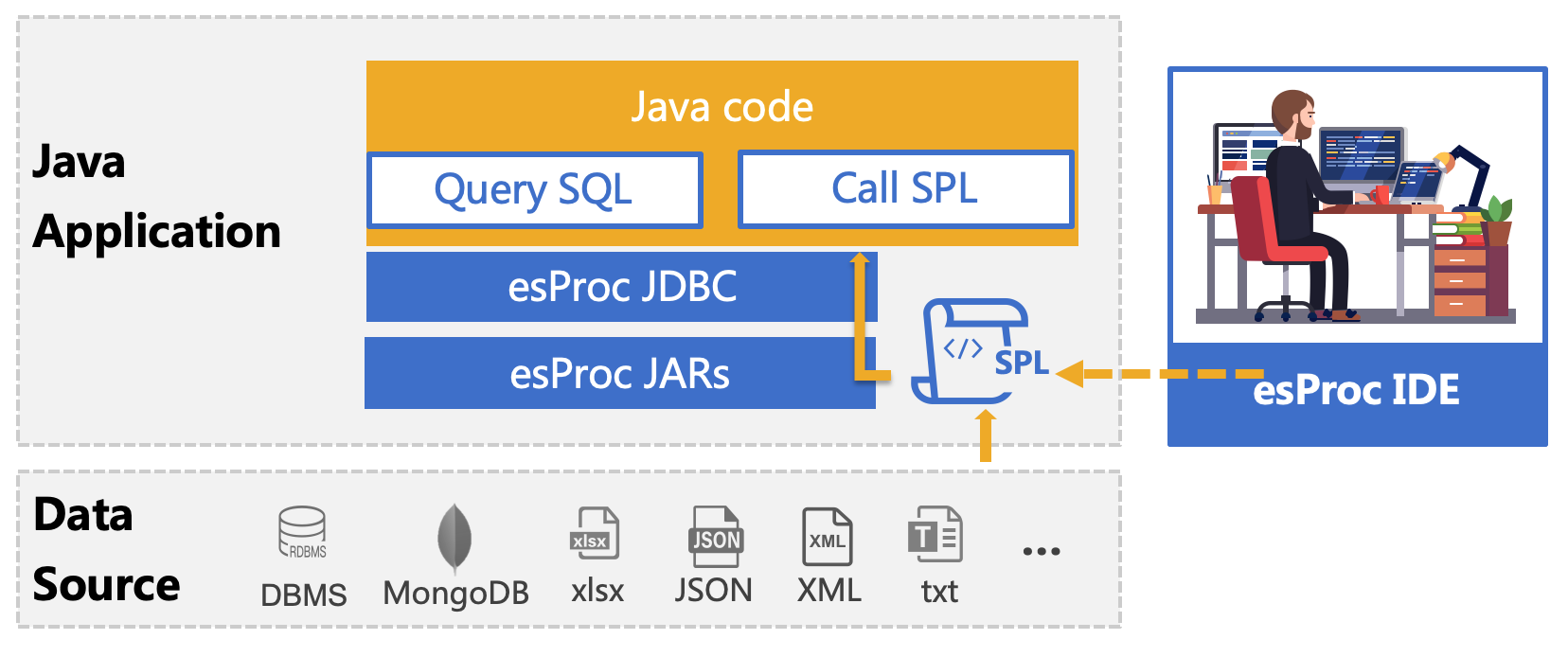
esProc 是专门用于基于 Java 计算的类库,旨在简化 Java 代码,提供不依赖数据库的计算能力,在实际应用中,经常用来解决报表开发中的复杂逻辑。 SPL 是基于 esProc 计算包的脚本语言,和 Java 程序一起部署,可以理解为库外存储过程,用法和 Java 程序中调用存储过程相同,通过 JDBC 接口传递给 Java 程序执行,实现分步式结构化计算,返回 ResultSet 对象。
众所周知,有些数据库没有强大的分析函数(eg. Mysql), 有些数据库没有存储过程(eg. Vertica),当遇到复杂的数据计算,只能在数据库外部来实现,如果直接用 Java 实现类似 SQL 函数和存储过程的功能,经常只是针对某个计算需求编写冗长的代码,代码几乎不可复用。
另外,即便拥有强大的分析函数,实现稍复杂的逻辑其实也不算容易,比如下面这种常见的业务计算,找出“销售额占到一半的前 n 个客户,并按销售额从大到小排序”,在 Oracle 中 SQL 实现如下:
with A as
(selectCUSTOM,SALESAMOUNT,row_number() over (order by SALESAMOUNT) RANKING
from SALES)
select CUSTOM,SALESAMOUNT
from (select CUSTOM,SALESAMOUNT,sum(SALESAMOUNT) over (order by RANKING) AccumulativeAmount
from A)
where AccumulativeAmount>(select sum(SALESAMOUNT)/2 from SALES)
order by SALESAMOUNT desc
按照销售额累计值从小到大排序,通过累计值大于“一半销售额”的条件,逆向找出占到销售额一半的客户。为了避免窗口函数在计算累计值时对销售额相同的值处理出现错误,用子查询先计算了排名。
下面是用 SPL 实现相同逻辑的代码:
| A | |
|---|---|
| 1 | =connect(“verticaLink”) |
| 2 | =A1.query(“select * from sales”).sort(SALESAMOUNT:-1) |
| 3 | =A2.cumulate(SALESAMOUNT) |
| 4 | =A3.m(-1)/2 |
| 5 | =A3.pselect(~>= A4) |
| 6 | =A2(to(A5)) |
| 7 | >A1.close() |
| 8 | return A6 |
A1: 获取数据库连接 P
A2: 查出销售表数据并按照销售额从大到小的顺序排序
A3: 计算出销售额的累计值序列,此处取代数据库窗口函数
A4: 根据最后的累计值,算出“一半销售额 " 的数据
A5: 在累计值序列找到大于“一半销售额 " 值的所在位置
A6: 找出 "一半销售额" 值的所在位置及其之前的所有记录
A7: 关闭数据库连接
A8: 结果返回
从上述代码我们可以看到,SPL 利用一套简洁的语法取代了需嵌套 SQL+ 窗口函数才能实现的逻辑,并且具有通用一致性(任何数据源代码一致)。
SPL 与 Java 报表开发工具集成也非常简单。以数据源是 Vertica,报表工具是 Birt 为例。把 esProc 核心 jar 包和相应数据库驱动 jar 包,拷贝至 Birt 开发环境 [安装目录]\plugins\org.eclipse.birt.report.data.oda.jdbc_4.6.0.v20160607212 下(不同 Birt 版本略有不同)。
Birt 开发工具内新建报表,并增加 esProc 数据源“esProcConnection”

Birt 调用 Vertica 外部存储过程(esProc 数据集)。新建“Data Sets”,选择配置的集算器数据源(esProcConnection),数据集类型选择存储过程(SQL Stored Procedure Query)

查询脚本(Query-Query Text)输入:{call VerticaExternalProcedures()},其中,VerticaExternalProcedures 为 SPL 脚本文件名

Finish,预览数据(Preview Results)

更多 Java 报表集成详细参见: BIRT 调用 SPL 脚本 和 JasperReport 调用 SPL 脚本
SQL 不擅长的运算主要包括复杂的集合计算、有序计算、关联计算、多步骤计算等。SQL 集合化不够彻底,没有显式的集合数据类型,导致计算过程中产生的集合难以复用,比如分组后必须强制汇总,而基于分组后的子集无法再计算。SQL 本身也不提倡多步骤代码,经常迫使程序员写出嵌套很多层的长语句,虽然用存储过程可以一定程度解决这个问题,但有时实际环境不允许我们使用存储过程,比如 DBA 严格控制存储过程的权限、旧数据库和小型数据库不支持存储过程等,而且存储过程的调试也很不方便,并不是很适合写出有过程的计算。
SPL 是专业的结构化计算语言,基于有序集合设计,同时提供了完善的集合运算,相当于 Java 和 SQL 优势的结合,擅长简化 SQL 复杂运算,像前面有序计算的问题都非常容易,下面再举几个不同类型的例子。
简化 SQL 分组
以员工表为例,按照 California, Texas, New York, Florida, OTHER 的顺序统计各州的平均工资,其中”OTHER”组用于存放其他州的员工。部分数据如下:
ID |
NAME |
BIRTHDAY |
STATE |
DEPT |
SALARY |
1 |
Rebecca |
1974/11/20 |
California |
R&D |
7000 |
2 |
Ashley |
1980/07/19 |
New York |
Finance |
11000 |
3 |
Rachel |
1970/12/17 |
New Mexico |
Sales |
9000 |
4 |
Emily |
1985/03/07 |
Texas |
HR |
7000 |
5 |
Ashley |
1975/05/13 |
Texas |
R&D |
16000 |
… |
… |
… |
… |
… |
… |
SQL:
with cte1(ID,STATE) as
(select 1,'California' from DUAL
UNION ALL select 2,'Texas' from DUAL
UNION ALL select 3,'New York' from DUAL
UNION ALL select 4,'Florida' from DUAL
UNION ALL select 5,'OTHER' from DUAL)
select
t1.STATE, t2.AVG_SALARY
from cte1 t1
left join
(select
STATE,avg(SALARY) AVG_SALARY
from
( select
CASE WHEN
STATE IN ('California','Texas','New York','Florida')
THEN STATE
ELSE 'OTHER' END STATE,
SALARY
from EMPLOYEE)
group by STATE) t2
on t1.STATE=t2.STATE
order by t1.ID
SPL:
A |
|
1 |
=T("Employee.csv") |
2 |
[California,Texas,New York,Florida] |
3 |
=A1.align@an(A2,STATE) |
4 |
=A3.new(if (#>A2.len(),"OTHER",STATE):STATE,~.avg(SALARY):AVG_SALARY) |
A1:导入员工表。
A2:定义地区常数集合。
A3:使用函数 A.align() 将员工表按地区对位分组,选项 @a 时每组返回所有匹配成员,选项 @n 时不匹配成员存放到新组。
A4:统计每组的平均工资,定义新组的名称为 OTHER。
因为 SQL 并不支持对齐分组,在 SQL 中我们只能通过 JOIN 等方式来实现。因为 SQL 的结果集是无序的,我们只能使用行号等方式记录原表的顺序。这些原因使得 SQL 实现对齐分组非常复杂。而 SPL 专门提供了用于对齐分组的函数 A.align(),语法更简洁,效率也更高。
简化 SQL 连接
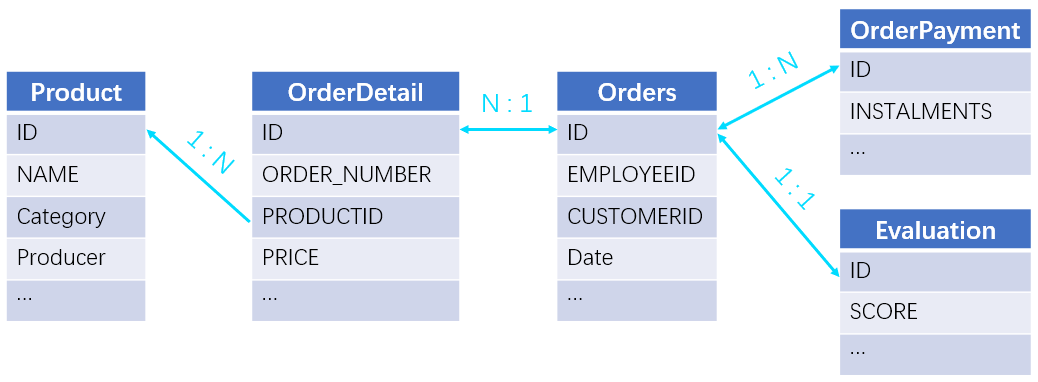
查询商品名称中包含“water”,在 2014 年下单,订单总金额大于 200 元,没有使用分期,得到 5 星好评的订单信息(订单号、产品名称和总金额)。表间关联关系如下:
SQL:
在本题中,既有一对多和多对一关系,又有一对一关系。如果我们不区分这几种连接方式,直接用 JOIN 来连接,就会产生多对多的关系,这样做是错误的。我们应该先处理多对一关系(外键表),将相应外键记录或需要的字段值附加到“多”表上,然后就变成只有一对一和一对多关系的情况了。再将子表按照主表主键(订单 ID)进行分组,主表主键(订单 ID)就变成子表事实上的主键了。最后将订单表、订单明细表、订单回款表和评价表按照订单 ID 连接即可。SQL 语句如下:
SELECT
Orders.ID,Detail1.NAME, Detail1.AMOUNT
FROM (
SELECT ID
FROM ORDERS
WHERE
EXTRACT (YEAR FROM Orders.ORDER_DATE)=2014
) Orders
INNER JOIN (
SELECT ID,NAME, SUM(AMOUNT) AMOUNT
FROM (
SELECT
Detail.ID,Product.NAME,Detail.PRICE*Detail.COUNT AMOUNT
FROM ORDER_DETAIL Detail
INNER JOIN
PRODUCT Product
ON Detail.PRODUCTID=Product.ID
WHERE NAME LIKE '%water%'
)
GROUP BY ID,NAME
) Detail1
ON Orders.ID=Detail1.ID
INNER JOIN(
SELECT
DISTINCT ID
FROM ORDER_PAYMENT
WHERE INSTALMENTS=0
) Payment
ON Orders.ID = Payment.ID
INNER JOIN(
SELECT ID
FROM EVALUATION
WHERE SCORE=5
) Evaluation
ON Orders.ID = Evaluation.ID
这个 SQL 已经很难看懂了,无论是编写 SQL,还是后期维护,都需要不少工作量。更重要的是,由于需要多次连接和嵌套查询,我们很难判断 SQL 语句的正确性。
SPL:
A |
|
1 |
=T("Orders.txt").select(year(ORDER_DATE)==2014) |
2 |
=T("Product.txt").select(like(NAME, "*water*")) |
3 |
=T("OrderDetail.txt").switch@i(PRODUCTID, A2:ID) |
4 |
=A3.group(ID).select(sum(PRICE*COUNT)>200) |
5 |
=T("OrderPayment.txt").select(INSTALMENTS==0).group(ID) |
6 |
=T("Evaluation.txt").select(SCORE==5) |
7 |
=join(A1:Orders,ID;A4:Detail,ID;A5:Payment,ID;A6:Evaluation,ID) |
8 |
=A7.new(Orders.ID,Detail.PRODUCTID.NAME,Detail.sum(PRICE*COUNT):AMOUNT) |
A1:导入订单表,并选出 2014 年的记录。
A2:导入产品表,并选出名称含有 water 的产品。
A3:导入订单明细表,并将产品 ID 字段外键对象化,转换为相应的产品记录。
A4:将订单明细按照订单 ID 分组,并选出总金额大于 200 的记录。
A5:导入订单回款表,并选出没有使用分期付款的记录。
A6:导入评价表,并选出 5 星好评的记录。
A7:使用函数 join() 按照订单 ID 连接订单表、订单明细表、订单回款表和评价表。
A8:返回满足条件的订单 ID、产品名称和订单总金额。
与 SQL 相比,SPL 脚本只是比前面的例子多了两行代码。而且每个表格的导入、选出、分组等运算,都是各自独立的,连接的代码只有 A7 一行。SPL 脚本的逻辑非常清晰,就是按照前面介绍的思路一步一步书写就完成了。
简化 SQL 转置
按渠道分类的销售表,按日期记录。部分数据如下:
YEAR |
MONTH |
ONLINE |
STORE |
2020 |
1 |
2440 |
3746.2 |
2020 |
2 |
1863.4 |
448.0 |
2020 |
3 |
1813.0 |
624.8 |
2020 |
4 |
670.8 |
2464.8 |
2020 |
5 |
3730.0 |
724.5 |
… |
… |
… |
… |
期望得到如下格式结果:
CATEGORY |
1 |
2 |
3 |
… |
ONLINE |
2440 |
1863.4 |
1813.0 |
… |
STORE |
3746.2 |
448.0 |
624.8 |
… |
SQL:
这个问题单独用行转列或者列转行都无法实现,需要进行两次转换。首先列转行,将渠道类型转换为类别列的字段值:
YEAR |
MONTH |
CATEGORY |
AMOUNT |
2020 |
1 |
ONLINE |
2440 |
2020 |
1 |
STORE |
3746.2 |
2020 |
2 |
ONLINE |
1863.4 |
2020 |
2 |
STORE |
448.0 |
… |
… |
… |
… |
然后行转列,将月份字段的值转换为列。SQL 语句如下:
SELECT *
FROM (
SELECT *
FROM MONTH_SALES
UNPIVOT (
AMOUNT FOR CATEGORY IN (
"ONLINE",STORE
)
)
WHERE YEAR=2020
)
PIVOT (
MAX(AMOUNT) FOR MONTH
IN (
1 AS "1",2 AS "2",2 AS "3",
4 AS "4",5 AS "5",6 AS "6",
7 AS "7",8 AS "8",9 AS "9",
10 AS "10",11 AS "11",12 AS "12"
)
)
在 SQL 中不允许将非常量表达式用于 PIVOT/UNPIVOT 值,所以行转列时需要枚举所有的月份。
SPL:
按照逻辑顺序使用函数 A.pivot@r()列转行,A.pivot() 行转列即可:
A |
|
1 |
=T("MonthSales.csv").select(YEAR:2020) |
2 |
=A1.pivot@r(YEAR,MONTH; CATEGORY, AMOUNT) |
3 |
=A2.pivot(CATEGORY; MONTH, AMOUNT) |
A1:导入销售表,并选出 2014 年的记录。
A2:使用函数 A.pivot@r() 列转行,将渠道类型转换为 CATEGORY 的字段值。
A3:使用函数 A.pivot() 行转列,将月份字段的值转换为列。
简化 SQL 递归
下面是某公司组织结构表,查询北京分公司的下属机构,并列出其上级机构名称,多层的用逗号分隔。
ID |
ORG_NAME |
PARENT_ID |
1 |
Head Office |
0 |
2 |
Beijing Branch Office |
1 |
3 |
Shanghai Branch Office |
1 |
4 |
Chengdu Branch Office |
1 |
5 |
Beijing R&D Center |
2 |
… |
… |
… |
SQL:
我们的直观想法是,每个机构在递归查找上级机构时,如果查找到指定值(例如北京分公司)则停止递归并保留当前机构,查找不到的机构则过滤掉。在 SQL 中,我们很难在一次递归中实现这个目标。我们将问题拆分为两步:首先找到北京分公司的所有下级机构,再按照上一个例题的方法,循环递归查找这些机构的所有父机构,查找到北京分公司时停止。SQL 语句如下:
WITH CTE1 (ID,ORG_NAME,PARENT_ID) AS(
SELECT
ID,ORG_NAME,PARENT_ID
FROM ORGANIZATION
WHERE ORG_NAME='Beijing Branch Office'
UNION ALL
SELECT
ORG.ID,ORG.ORG_NAME,ORG.PARENT_ID
FROM ORGANIZATION ORG
INNER JOIN CTE1
ON ORG.PARENT_ID=CTE1.ID
)
,CTE2 (ID,ORG_NAME,PARENT_ID,O_ID,GROUP_NUM) AS(
SELECT
ID,ORG_NAME,PARENT_ID,ID O_ID,1 GROUP_NUM
FROM CTE1
UNION ALL
SELECT ORG.ID,ORG.ORG_NAME,ORG.PARENT_ID,
CTE2.O_ID,CTE2.GROUP_NUM+1 GROUP_NUM
FROM ORGANIZATION ORG
INNER JOIN CTE2
ON ORG.ID=CTE2.PARENT_ID AND
CTE2.ORG_NAME<>'Beijing Branch Office'
)
SELECT
MAX(O_ID) ID, MAX(O_ORG_NAME) ORG_NAME,
MAX(PARENT_NAME) PARENT_NAME
FROM(
SELECT
O_ID, O_ORG_NAME,
WM_CONCAT(ORG_NAME) OVER
(PARTITION BY O_ID ORDER BY O_ID,GROUP_NUM) PARENT_NAME
FROM(
SELECT
ID,PARENT_ID,O_ID,GROUP_NUM,
CASE WHEN GROUP_NUM=1 THEN NULL ELSE ORG_NAME END ORG_NAME,
CASE WHEN GROUP_NUM=1 THEN ORG_NAME ELSE NULL END O_ORG_NAME
FROM (
SELECT
ID,ORG_NAME,PARENT_ID,O_ID,GROUP_NUM,ROWNUM RN
FROM CTE2
ORDER BY O_ID,GROUP_NUM
)
)
)
GROUP BY O_ID
ORDER BY O_ID
在 ORACLE 中,我们还可以使用 START WITH … CONNECT BY … PRIOR … 进行递归查询,语句如下:
WITH CTE1 AS (
SELECT ID,ORG_NAME,PARENT_ID,ROWNUM RN
FROM ORGANIZATION ORG
START WITH ORG.ORG_NAME='Beijing Branch Office'
CONNECT BY ORG.PARENT_ID=PRIOR ORG.ID
)
,CTE2 AS (
SELECT
ID,ORG_NAME,PARENT_ID,RN,
CASE WHEN LAG(ORG_NAME,1) OVER(ORDER BY RN ASC)= 'Beijing Branch Office' OR
LAG(ORG_NAME,1) OVER(ORDER BY RN ASC) IS NULL THEN 1 ELSE 0 END FLAG
FROM(
SELECT ID,ORG_NAME,PARENT_ID,ROWNUM RN
FROM CTE1
START WITH 1=1
CONNECT BY CTE1.ID=PRIOR CTE1.PARENT_ID
)
)
SELECT
MAX(ID) ID, MAX(O_ORG_NAME) ORG_NAME,
MAX(PARENT_NAME) PARENT_NAME
FROM(
SELECT
ID,O_ORG_NAME,GROUP_ID,
WM_CONCAT(ORG_NAME) OVER
(PARTITION BY GROUP_ID ORDER BY RN) PARENT_NAME
FROM(
SELECT
ID, ORG_NAME, O_ORG_NAME,RN,
SUM(ID) OVER (ORDER BY RN) GROUP_ID
FROM(
SELECT
PARENT_ID,RN,
CASE WHEN FLAG=1 THEN NULL ELSE ORG_NAME END ORG_NAME,
CASE WHEN FLAG=1 THEN ID ELSE NULL END ID,
CASE WHEN FLAG=1 THEN ORG_NAME ELSE NULL END O_ORG_NAME
FROM CTE2
)
)
)
GROUP BY GROUP_ID
ORDER BY GROUP_ID
SPL:
在 SPL 中提供了函数 A.prior(F,r) 用于递归查找引用直到指定值:
A |
|
1 |
=T("Organization.txt") |
2 |
>A1.switch(PARENT_ID,A1:ID) |
3 |
=A1.select@1(ORG_NAME=="Beijing Branch Office") |
4 |
=A1.new(ID,ORG_NAME,~.prior(PARENT_ID,A3) :PARENT_NAME) |
5 |
=A4.select(PARENT_NAME!=null) |
6 |
=A5.run(PARENT_NAME=PARENT_NAME.(PARENT_ID.ORG_NAME).concat@c()) |
A1:导入组织机构表
A2:将父机构 ID 外键对象化,转换为相应的父机构记录,实现外键对象化。
A3:选出北京分公司的记录。
A4:创建由序号、部门名称和所有上级部门的记录集合组成的表。
A5:选出父机构不为空的记录,即北京分公司的记录。
A6:循环将父机构名称拼成由逗号分隔的字符串。
SPL 的解决方案依然非常简洁,使用北京分公司的记录作为参数,用于在递归时查找引用直到北京分公司记录为止。与 SQL 相比,SPL 的逻辑看起来非常清晰。


英文版