


SQL 和 SPL 的多对一连接对比
【摘要】
连接(JOIN)用于把来自两个或多个表的记录结合起来。SQL 和 SPL 是大家比较熟悉的程序语言,本文将探讨对于连接问题,这两种语言的解决方案和基本原理。如何简便快捷的处理连接运算,这里为你全程解析,并提供 SQL 和 SPL 示例代码。SQL 和 SPL 的多对一连接对比
前文介绍了一对一、多对一两种表间关联关系,本文继续介绍多对一关联关系。
多对一关联,是指一张表的任意条记录能与另外一张表的一条记录进行对应。多对一关联关系,常见于有外键关系的两个表。表 A 的某些字段与表 B 的主键关联。A 表中与 B 表主键关联的字段称为指向 B 表的外键,B 也称为 A 的外键表。
例如有员工表和部门表,其中员工表的部门 ID 字段,指向了部门表的 ID 字段。每个员工都有一个部门,但是每个部门可以有多个员工,员工表和部门表是多对一的关系。
我们经常把一对多和多对一混在一起来讲,其实是受了 SQL 的误导。在 SQL 中对这两种关联关系并没有进行区分,也没有单独提供各自的解决方案。
解决多对一关联的思路与一对多完全不同,我们可以在连接时将外键值转换成对应记录,或者将需要的字段值附加到“多”表上,然后就可以当作是一张表进行查询运算了。但是在 SQL 中并没有单独支持多对一关联关系,仍然是使用 JOIN 进行连接。而 SPL 则是提供了 A.switch() 等函数,针对外键表连接(多对一)进行优化和提速。
【例 1】 根据员工表和部门表,查询所有员工的姓名及其所在部门名称。部分数据如下:
EMPLOYEE:
ID |
NAME |
BIRTHDAY |
DEPARTMENTID |
SALARY |
1 |
Rebecca |
1974/11/20 |
6 |
7000 |
2 |
Ashley |
1980/07/19 |
2 |
11000 |
3 |
Rachel |
1970/12/17 |
7 |
9000 |
4 |
Emily |
1985/03/07 |
3 |
7000 |
5 |
Ashley |
1975/05/13 |
6 |
16000 |
… |
… |
… |
… |
… |
DEPARTMENT:
ID |
NAME |
MANAGER |
1 |
Administration |
18 |
2 |
Finance |
2 |
3 |
HR |
4 |
4 |
Marketing |
6 |
5 |
Production |
7 |
… |
… |
… |
SQL的解决方案:
SQL处理多对一关系时,还是使用 JOIN 语句将两表连接,连接条件是外键字段与外键表的主键字段相等。这里要查询所有员工,所以使用了左连接 LEFT JOIN,SQL 语句如下:
SELECT
E.NAME, D.NAME DEPT_NAME
FROM EMPLOYEE E
LEFT JOIN
DEPARTMENT D
ON E.DEPARTMENTID=D.ID
SPL的解决方案:
SPL提供了函数 A.switch(),将编码字段的键值转换为对应的记录。
A |
|
1 |
=T("Employee.txt") |
2 |
=T("Department.txt") |
3 |
=A1.switch(DEPARTMENTID, A2:ID) |
4 |
=A3.new(NAME, DEPARTMENTID.NAME:DEPT_NAME) |
A1:导入员工表。
A2:导入部门表。
A3:使用函数 A.switch() 将部门 ID 进行外键对象化,即将部门 ID 的字段值转换成相应的部门记录。
A4:返回员工名称和部门名称,其中部门名称可以通过部门记录的 NAME 字段获得。
由于这个例子比较简单,SQL 和 SPL 都可以很好的解决。可能有的同学会有疑问,在连接时将需要的外键字段引入就可以了,为什么还要进行外键对象化呢?接下来我们用一个稍微复杂一点的例子来说明。
【例 2】 根据员工表和部门表,查询哪些美国籍员工有一个中国籍经理。部分数据如下:
EMPLOYEE:
ID |
NAME |
BIRTHDAY |
DEPARTMENTID |
SALARY |
1 |
Rebecca |
1974/11/20 |
6 |
7000 |
2 |
Ashley |
1980/07/19 |
2 |
11000 |
3 |
Rachel |
1970/12/17 |
7 |
9000 |
4 |
Emily |
1985/03/07 |
3 |
7000 |
5 |
Ashley |
1975/05/13 |
6 |
16000 |
… |
… |
… |
… |
… |
DEPARTMENT:
ID |
NAME |
MANAGER |
1 |
Administration |
18 |
2 |
Finance |
2 |
3 |
HR |
4 |
4 |
Marketing |
6 |
5 |
Production |
7 |
… |
… |
… |
SQL的解决方案:
在本例中,我们不能简单的将需要的外键表字段添加到员工表上,需要进行两次连接:一是部门表与员工表通过员工 ID 进行连接, 查找经理的国籍。二是员工表与部门表通过部门 ID 进行连接,查找员工的部门。SQL 语句如下:
SELECT *
FROM EMPLOYEE E2
LEFT JOIN
(SELECT D1.ID,D1.MANAGER,E1.NATION MANAGER_NATION
FROM DEPARTMENT D1
LEFT JOIN EMPLOYEE E1
ON D1.MANAGER=E1.ID
) D2
ON E2.DEPARTMENTID=D2.ID
WHERE D2.MANAGER_NATION='Chinese' AND E2.NATION='American'
这个 SQL 看起来就比较复杂了。因为每增加一次连接 SQL 语句就要多嵌套一层,并且要提前想清楚我们需要外键表中的哪些字段。
SPL的解决方案:
SPL还是可以通过函数 A.switch() 进行外键的对象化来解决问题:
A |
|
1 |
=T("Employee.txt").keys(ID) |
2 |
=T("Department.txt").keys(ID) |
3 |
=A2.switch(MANAGER, A1) |
4 |
=A1.switch(DEPARTMENTID, A2) |
5 |
=A4.select(NATION=="American" && DEPARTMENTID.MANAGER.NATION=="Chinese") |
A1:导入员工表,以 ID 为主键。
A2:导入部门表,以 ID 为主键。
A3:使用函数 A.switch() 外键对象化,将部门表的经理字段,转换成相应的员工记录。
A4:使用函数 A.switch() 外键对象化,将员工表的部门字段,转换成相应的部门记录。
A5:选出经理是中国籍的美国籍员工。
与 SQL 语句相比,SPL 语句并没有变得复杂。多了一层关联关系,SPL 脚本只是按照逻辑增加了一次外键对象化。我们不需要每次外键连接都提前想好需要哪些字段,可以直接从记录对象中取得,在选出时也非常符合自然逻辑,部门的经理的国籍(DEPARTMENTID.MANAGER.NATION)是中国籍。
【例 3】 根据课程表和选课表,查询有多少学生选修了“Matlab”课程。部分数据如下:
COURSE:
ID |
NAME |
TEACHERID |
1 |
Environmental protection and sustainable development |
5 |
2 |
Mental health of College Students |
1 |
3 |
Matlab |
8 |
4 |
Electromechanical basic practice |
7 |
5 |
Introduction to modern life science |
3 |
… |
… |
… |
SELECT_COURSE:
ID |
COURSEID |
STUDENTID |
1 |
6 |
59 |
2 |
6 |
43 |
3 |
5 |
52 |
4 |
5 |
44 |
5 |
5 |
37 |
… |
… |
… |
SQL的解决方案:
我们想要在连接时,删除不匹配的记录(选出课程不是 Matlab 的),可以使用内连接。SQL 语句如下:
SELECT
COUNT(*) COUNT
FROM SELECT_COURSE SC
INNER JOIN
COURSE C
ON SC.COURSEID=C.ID
WHERE NAME='Matlab'
SPL的解决方案:
在函数 A.switch() 中,选项 @i 用于在连接时删除不匹配的记录。
A |
|
1 |
=T("Course.csv") |
2 |
=T("SelectCourse.csv") |
3 |
=A1.select(NAME:"Matlab") |
4 |
=A2.switch@i(COURSEID, A3:ID).count() |
A1:导入课程表。
A2:导入选课表。
A3:在课程表中选出名为 Matlab 的记录。
A4:使用函数 A.switch() 的选项 @i,在连接时删除不匹配的记录,即剩下的都是选择了 Matlab 课程的记录,再统计数量。
【例 4】 根据销售表和客户表,查询 2014 年新增客户的销售情况(即销售表的客户 ID 不在客户表中的记录)。部分数据如下:
SALES:
ID |
CUSTOMERID |
ORDERDATE |
SELLERID |
PRODUCTID |
AMOUNT |
10248 |
VINET |
2013/7/4 |
5 |
59 |
2440 |
10249 |
TOMSP |
2013/7/5 |
6 |
38 |
1863.4 |
10250 |
HANAR |
2013/7/8 |
4 |
65 |
1813 |
10251 |
VICTE |
2013/7/8 |
3 |
66 |
670.8 |
10252 |
SUPRD |
2013/7/9 |
4 |
46 |
3730 |
… |
… |
… |
… |
… |
… |
CUSTOMER:
ID |
NAME |
CITY |
POSTCODE |
TEL |
ALFKI |
Sanchuan Industrial Co., Ltd |
Tianjin |
343567 |
(030) 30074321 |
ANATR |
Southeast industries |
Tianjin |
234575 |
(030) 35554729 |
ANTON |
Tanson trade |
Shijiazhuang |
985060 |
(0321) 5553932 |
AROUT |
Guoding Co., Ltd |
Shenzhen |
890879 |
(0571) 45557788 |
BERGS |
Tongheng machinery |
Nanjing |
798089 |
(0921) 9123465 |
… |
… |
… |
… |
… |
SQL的解决方案:
我们想要在连接时,只保留不匹配的记录(销售表的客户 ID 不在客户表中的),在 SQL 中我们可以使用 NOT IN 或者 NOT EXISTS 来实现。SQL 语句如下:
SELECT *
FROM SALES S
WHERE
EXTRACT (YEAR FROM ORDERDATE)=2014
AND
CUSTOMERID NOT IN
(SELECT DISTINCT ID
FROM CUSTOMER)
或者:
SELECT *
FROM SALES S
WHERE
EXTRACT (YEAR FROM ORDERDATE)=2014
AND
NOT EXISTS
(SELECT *
FROM CUSTOMER C
WHERE S.CUSTOMERID=C.ID)
SPL的解决方案:
在函数 A.switch() 中,选项 @d 时只保留不匹配的记录。
A |
|
1 |
=T("Sales.csv") |
2 |
=T("Customer.txt") |
3 |
=A1.select(year(ORDERDATE)==2014) |
4 |
=A3.switch@d(CUSTOMERID, A2:ID) |
A1:导入销售表。
A2:导入客户表。
A3:在销售表中选出 2014 的记录。
A4:使用函数 A.switch() 的选项 @d,在连接时只保留不匹配的记录,即 2014 年新增客户的销售记录。
【例 5】 根据组织机构表,查询每个机构的上级机构名称。部分数据如下:
ID |
ORG_NAME |
PARENT_ID |
1 |
Head Office |
0 |
2 |
Beijing Branch Office |
1 |
3 |
Shanghai Branch Office |
1 |
4 |
Chengdu Branch Office |
1 |
5 |
Beijing R&D Center |
2 |
… |
… |
… |
SQL的解决方案:
在组织机构表中,上级机构 ID(PARENT_ID)指向的还是本表,这是一个自连接的例子。我们可以对组织机构表查询两次,分别看作两个表,再使用之前用到的连接方式即可。SQL 语句如下:
SELECT
ORG1.ID,ORG1.ORG_NAME,ORG2.ORG_NAME PARENT_NAME
FROM
ORGANIZATION ORG1
LEFT JOIN
ORGANIZATION ORG2
ON ORG1.PARENT_ID=ORG2.ID
ORDER BY ID
SPL的解决方案:
在 SPL 中,我们还是可以使用函数 A.switch() 进行外键对象化,外键表选择自身即可。
A |
|
1 |
=T("Organization.txt") |
2 |
=A1.switch(PARENT_ID, A1:ID) |
3 |
=A2.new(ID, ORG_NAME, PARENT_ID.ORG_NAME:PARENT_NAME) |
A1:导入组织机构表。
A2:使用函数 A.switch() 进行外键对象化,将父机构 ID 字段值转换为相应的父机构记录。
A3:返回所有机构的名称和父机构的名称。
【例 6】 查询 2015 年每个客户的名称和订单总金额。订单表、订单明细表和客户表部分数据如下:
ORDERS:
ID |
CUSTOMERID |
EMPLOYEEID |
ORDER_DATE |
ARRIVAL_DATE |
10248 |
VINET |
5 |
2012/07/04 |
2012/08/01 |
10249 |
TOMSP |
6 |
2012/07/05 |
2012/08/16 |
10250 |
HANAR |
4 |
2012/07/08 |
2012/08/05 |
10251 |
VICTE |
3 |
2012/07/08 |
2012/08/05 |
10252 |
SUPRD |
4 |
2012/07/09 |
2012/08/06 |
… |
… |
… |
… |
… |
ORDER_DETAIL:
ID |
ORDER_NUMBER |
PRODUCTID |
PRICE |
COUNT |
DISCOUNT |
10814 |
1 |
48 |
102.0 |
8 |
0.15 |
10814 |
2 |
48 |
102.0 |
8 |
0.15 |
10814 |
3 |
48 |
306.0 |
24 |
0.15 |
10814 |
4 |
48 |
102.0 |
8 |
0.15 |
10814 |
5 |
48 |
204.0 |
16 |
0.15 |
… |
… |
… |
… |
… |
… |
CUSTOMER:
ID |
NAME |
CITY |
POSTCODE |
TEL |
ALFKI |
Sanchuan Industrial Co., Ltd |
Tianjin |
343567 |
(030) 30074321 |
ANATR |
Southeast industries |
Tianjin |
234575 |
(030) 35554729 |
ANTON |
Tanson trade |
Shijiazhuang |
985060 |
(0321) 5553932 |
AROUT |
Guoding Co., Ltd |
Shenzhen |
890879 |
(0571) 45557788 |
BERGS |
Tongheng machinery |
Nanjing |
798089 |
(0921) 9123465 |
… |
… |
… |
… |
… |
SQL的解决方案:
本题中同时存在一对多(订单表和订单明细表)和多对一(订单表和客户表)关联关系。在 SQL 中对于一对多和多对一关系是没有特意区分的,但是我们必须搞清楚两者的不同。我们可以先处理外键表(多对一),将相应外键记录或需要的字段值附加到“多”表上,然后就变成只有主子表(一对多)的情况了。SQL 语句如下:
SELECT
CUSTOMER_NAME, SUM(AMOUNT) AMOUNT
FROM (
SELECT
Orders1.ID, CUSTOMER_NAME, Detail.PRICE*Detail.COUNT AMOUNT
FROM (
SELECT
Orders.ID,Customer.NAME CUSTOMER_NAME
FROM ORDERS Orders
LEFT JOIN
CUSTOMER Customer
ON Orders.CUSTOMERID=Customer.ID
WHERE EXTRACT (YEAR FROM ORDER_DATE)=2015
) Orders1
INNER JOIN
ORDER_DETAIL Detail
ON Orders1.ID=Detail.ID
)
GROUP BY CUSTOMER_NAME
ORDER BY CUSTOMER_NAME
SPL的解决方案:
在 SPL 中,我们首先使用外键对象化,将订单表中的客户 ID 转换为对应的客户记录然后就只有单个主子表关系了,使用函数 join() 进行连接即可。
A |
|
1 |
=T("Orders.txt") |
2 |
=T("Customer.txt") |
3 |
=A1.select(year(ORDER_DATE)==2015).switch(CUSTOMERID, A2:ID) |
4 |
=T("OrderDetail.txt").group(ID) |
5 |
=join(A3:Orders, ID;A4:Detail, ID) |
6 |
=A5.groups(Orders.CUSTOMERID.NAME; Detail.sum(PRICE*COUNT):AMOUNT) |
A1:导入订单表。
A2:导入客户表。
A3:选出 2015 年的订单,并使用函数 A.switch() 将客户 ID 外键对象化,转换为对应的客户记录。
A4:导入订单明细表,并按订单 ID 分组。
A5:使用函数 join() 按照订单 ID 连接订单表和订单明细表。
A6:分组汇总每个客户的总销售额。
【例 7】 查询商品名称中包含“water”,在 2014 年下单,订单总金额大于 200 元,没有使用分期,得到 5 星好评的订单信息(订单号、产品名称和总金额)。表间关联关系和部分数据如下:
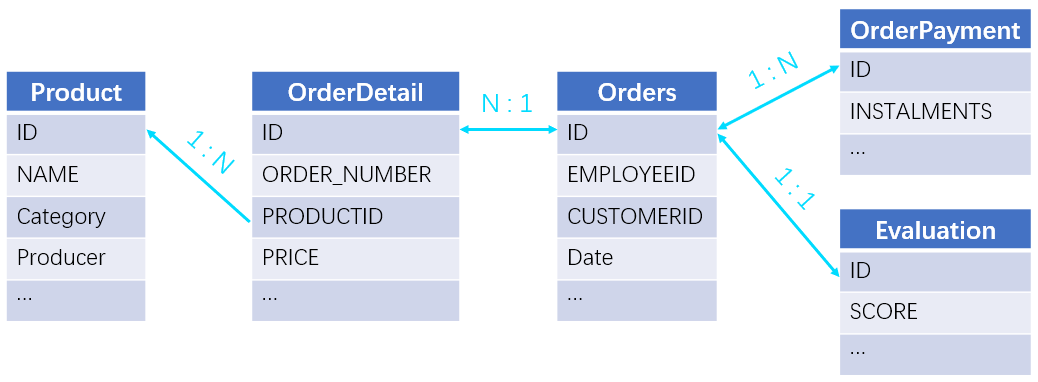
ORDERS:
ID |
CUSTOMERID |
EMPLOYEEID |
ORDER_DATE |
ARRIVAL_DATE |
10248 |
VINET |
5 |
2012/07/04 |
2012/08/01 |
10249 |
TOMSP |
6 |
2012/07/05 |
2012/08/16 |
10250 |
HANAR |
4 |
2012/07/08 |
2012/08/05 |
10251 |
VICTE |
3 |
2012/07/08 |
2012/08/05 |
10252 |
SUPRD |
4 |
2012/07/09 |
2012/08/06 |
… |
… |
… |
… |
… |
ORDER_DETAIL:
ID |
ORDER_NUMBER |
PRODUCTID |
PRICE |
COUNT |
DISCOUNT |
10814 |
1 |
48 |
102.0 |
8 |
0.15 |
10814 |
2 |
48 |
102.0 |
8 |
0.15 |
10814 |
3 |
48 |
306.0 |
24 |
0.15 |
10814 |
4 |
48 |
102.0 |
8 |
0.15 |
10814 |
5 |
48 |
204.0 |
16 |
0.15 |
… |
… |
… |
… |
… |
… |
ORDER_PAYMENT:
ID |
PAY_DATE |
AMOUNT |
CHANNEL |
INSTALMENTS |
10814 |
2014/01/05 |
816.0 |
3 |
0 |
10848 |
2014/01/23 |
800.25 |
2 |
1 |
10848 |
2014/01/23 |
800.25 |
0 |
0 |
10848 |
2014/01/23 |
800.25 |
3 |
1 |
10966 |
2014/03/20 |
572.0 |
2 |
1 |
… |
… |
… |
… |
… |
EVALUATION:
ID |
SCORE |
DATE |
COMMENT |
10248 |
4 |
2012/07/12 |
|
10249 |
1 |
2012/07/06 |
|
10250 |
4 |
2012/07/10 |
|
10251 |
2 |
2012/07/11 |
|
10252 |
3 |
2012/07/16 |
|
… |
… |
… |
… |
PRODUCT:
ID |
NAME |
SUPPLIERID |
CATEGORY |
1 |
Apple Juice |
2 |
1 |
2 |
Milk |
1 |
1 |
3 |
Tomato sauce |
1 |
2 |
4 |
Salt |
2 |
2 |
5 |
Sesame oil |
2 |
2 |
… |
… |
… |
… |
SQL的解决方案:
在本题中,既有一对多和多对一关系,又有一对一关系。如果我们不区分这几种连接方式,直接用 JOIN 来连接,就会产生多对多的关系,这样做是错误的。我们应该先处理多对一关系(外键表),将相应外键记录或需要的字段值附加到“多”表上,然后就变成只有一对一和一对多关系的情况了。再将子表按照主表主键(订单 ID)进行分组,主表主键(订单 ID)就变成子表事实上的主键了。最后将订单表、订单明细表、订单回款表和评价表按照订单 ID 连接即可。SQL 语句如下:
SELECT
Orders.ID,Detail1.NAME, Detail1.AMOUNT
FROM (
SELECT ID
FROM ORDERS
WHERE
EXTRACT (YEAR FROM Orders.ORDER_DATE)=2014
) Orders
INNER JOIN (
SELECT ID,NAME, SUM(AMOUNT) AMOUNT
FROM (
SELECT
Detail.ID,Product.NAME,Detail.PRICE*Detail.COUNT AMOUNT
FROM ORDER_DETAIL Detail
INNER JOIN
PRODUCT Product
ON Detail.PRODUCTID=Product.ID
WHERE NAME LIKE '%water%'
)
GROUP BY ID,NAME
) Detail1
ON Orders.ID=Detail1.ID
INNER JOIN(
SELECT
DISTINCT ID
FROM ORDER_PAYMENT
WHERE INSTALMENTS=0
) Payment
ON Orders.ID = Payment.ID
INNER JOIN(
SELECT ID
FROM EVALUATION
WHERE SCORE=5
) Evaluation
ON Orders.ID = Evaluation.ID
这个 SQL 已经很难看懂了,无论是编写 SQL,还是后期维护,都需要不少工作量。更重要的是,由于需要多次连接和嵌套查询,我们很难判断 SQL 语句的正确性。
SPL的解决方案:
A |
|
1 |
=T("Orders.txt").select(year(ORDER_DATE)==2014) |
2 |
=T("Product.txt").select(like(NAME, "*water*")) |
3 |
=T("OrderDetail.txt").switch@i(PRODUCTID, A2:ID) |
4 |
=A3.group(ID).select(sum(PRICE*COUNT)>200) |
5 |
=T("OrderPayment.txt").select(INSTALMENTS==0).group(ORDER) |
6 |
=T("Evaluation.txt").select(SCORE==5) |
7 |
=join(A1:Orders,ID;A4:Detail,ID;A5:Payment,ORDER;A6:Evaluation,ID) |
8 |
=A7.new(Orders.ID,Detail.PRODUCTID.NAME,Detail.sum(PRICE*COUNT):AMOUNT) |
A1:导入订单表,并选出 2014 年的记录。
A2:导入产品表,并选出名称含有 water 的产品。
A3:导入订单明细表,并将产品 ID 字段外键对象化,转换为相应的产品记录。
A4:将订单明细按照订单 ID 分组,并选出总金额大于 200 的记录。
A5:导入订单回款表,并选出没有使用分期付款的记录。
A6:导入评价表,并选出 5 星好评的记录。
A7:使用函数 join() 按照订单 ID 连接订单表、订单明细表、订单回款表和评价表。
A8:返回满足条件的订单 ID、产品名称和订单总金额。
与 SQL 相比,SPL 脚本只是比前面的例子多了两行代码。而且每个表格的导入、选出、分组等运算,都是各自独立的,连接的代码只有A7一行。SPL 脚本的逻辑非常清晰,就是按照前面介绍的思路一步一步书写就完成了。
通过以上的例子我们可以看到,多对一与一对多关系是有很大的区别的。SQL 没有区分两者的不同,需要用户自己去注意两者的区别。而在 SPL 中,明确的区分了两者的不同,分别提供了不同的函数来支持多对一和一对多两种关联关系。我们再来按照 SPL 的解题方式,总结一下多表关联查询的思路:
(1) 有多对一关联关系(外键表)时,将相应外键记录或需要的字段值附加到“多”表上。
(2) 有一对多关联关系(主子表)时,子表按照主表主键分组后,主表主键就成为了子表事实上的主键。
(3) 多表按照主键(或事实上的主键)进行连接。
SQL 与 SPL 对比系列:
SQL 和 SPL 的集合运算对比
SQL 和 SPL 的选出运算对比
SQL 和 SPL 的有序运算对比
SQL 和 SPL 的等值分组对比
SQL 和 SPL 的非等值分组对比
SQL 和 SPL 的有序分组对比
SQL 和 SPL 的一对一和一对多连接对比
SQL 和 SPL 的多对一连接对比
SQL 和 SPL 的多对多连接对比
SQL 和 SPL 的基本静态转置对比
SQL 和 SPL 的复杂静态转置对比
SQL 和 SPL 的动态转置对比
SQL 和 SPL 的递归对比

