


【程序设计】10.2 [找关联] 外键
10.2 外键
有了主键,也就能够唯一标识一条记录了。然后,我们就能建立不同数据表的记录之间的关联了。
先生成两个有主键的表用来做实验,简单起见用整数做主键,但被故意打乱了次序。
A |
B |
C |
|
1 |
[HR,R&D,Sales,Marketing,Admin] |
=A1.len().sort(rand()) |
=100.sort(rand()) |
2 |
=A1.new(B1(#):did, ~:name, C1(#):manager ).keys(did) |
[CHN,USA] |
|
3 |
=100.new(C1(#):eid,C2(rand(2)+1):nation,rand(5)+1:dept).keys(eid) |
||
4 |
=A2.run(A3(manager).dept=did) |
||
A2 是个部门表,每条记录对应一个部门,did 字段是部门的编号,用作主键,name 字段是部门名称;A3 是员工表,每条记录对应一名员工,eid 字段是员工编号,用作主键,nation 是员工国籍。员工表通常还会有姓名字段,但这里没什么用,我们就不生成了。
重点是 A3 的 dept 字段和 A2 的 manage 字段。dept 存储的是一个整数,它代表这个员工所属的部门。员工表中记录 e 对应的员工的所属部门,就是部门表中以 e.dept 为主键的记录 d 对应的部门。我们这时也会说记录 e 和记录 d关联。
A2 的 manager 字段表示部门的经理,经理也是个员工,也会出现在员工表中。部门表中记录 d 对应的部门的经理,就是员工表中以 d.manager 为主键的记录 e 对应的员工。我们也说这两条记录 d 和 e 关联。
了解一这个关系,A4 的作用就清楚了,因为随机生成的数据不能保证经理的所属部门就是本部门,要在 A4 再调整一下,这样这份数据就可以用了。
现在我们想列出所有 R&D 部门的人员。
这是个简单的选出问题,应该用 select 函数。但是,员工表中没有部门名称,只有部门的编号,去部门表中去用编号查出部门名称才能做选出。
A |
B |
C |
|
… |
… |
||
5 |
=A3.select(A2.find(dept).name=="R&D") |
||
类似地,我们还可以列出所有经理是美国人的部门:
A |
B |
C |
|
… |
… |
||
5 |
=A2.select(A3.find(manager).nation=="USA") |
||
这样我们就把员工表和部门表关联起来了,可以联合使用两个表的信息来做运算。其中员工表中的 dept 字段,它的取值总是部门表中某条记录的主键,而且也用来代表部门表中的这条记录。我们称这种字段为外键,更完整的说法是员工表中指向部门表的外键。通过外键,可以在针对某个表的运算中引用指向表的关联记录的某些字段,这两个表也就有了外键关联。
同样,部门表中的 manager 字段也是指向员工表的外键。
主键可能有多个字段构成,对应的外键也可能有多个字段,但相对不太常见,我们这里不再举例了。
当两个表之间有外键的关系时,比如 A 表的某个字段是指向 B 表的外键。我们还要知道两个术语:称 B 表是 A 表的维表,而 A 表称为事实表。维表和事实表的关系是相对的,关注员工表的外键 dept 时,部门表是员工表的维表,而在关注部门表的外键 manager 时,员工表又是部门表的维表。
维表和事实表在讨论数据库业务时经常会被程序员使用。日常数据处理中不大使用这种太学术化的词汇,但还是知道一下更好一点。
数据库的术语中,还会说外键关联是多对一的关联,也就是可能多条事实表记录与同一条维表记录关联。
外键也不是个陌生的概念。维表就是我们常常使用的代码表,把一些经常要被引用的事物的属性列到一个代码表中,并给一个编码(也就是主键)来标识,在引用时就只用这个编码(也就是外键),更详细的信息则用这个编码到代码表中去查询。
比如电话号码上会挂着机主姓名、地址、…等信息,而通话记录中就只有电话号码了。电话号码是通讯录的主键,通话记录中的电话号码就是指向通讯录的外键。通讯录是通话记录的维表,通话记录是事实表。在针对通话记录的运算中经常可能使用到电话号码相关的信息,比如查询北京地区打出的电话有多少等,这就用外键去寻找关联记录的字段。
其它像银行帐户与银行交易记录、商品信息与买卖记录、…都是这种情况。
针对事实表的运算中使用到维表信息是很常见的事情,为什么我们不把要用到维表字段直接抄录到事实表中呢?
有过这种代码表处理经验的读者都会知道答案。维表的信息内容很多,如果都抄到事实表中,事实表会被搞得很大,占用很多存储空间,导致性能低下;而且,维表很可能会变,比如部门名称、机主地址等,如果都抄到事实表中,一旦发生改变,事实表都要更新,而事实表通常巨大得多,这就会非常麻烦和低效。如果是独立的维表,那只要修改维表,事实表运算时临时来取维表字段,总能得到最新信息。
理解了概念,我们继续。现在把员工编号(没生成姓名字段,就用编号代替了)和所属的部门名称列到成一个表:
A |
B |
C |
|
… |
… |
||
5 |
=A3.new(eid,A2.find(dept).name:dept) |
||
这个很像 Excel 里的 VLookup 函数,代码表就是这么用的。
但是,总是使用 find 来写显然非常麻烦,而且每次都计算的效率也很差,比如再一步,想把员工所属部门的经理的编号也列上,就得把这个 find 写两遍。
A |
B |
C |
|
… |
… |
||
5 |
=A3.new(eid,A2.find(dept).name:dept,A2.find(dept).manager) |
||
这就更像 VLookup 了,Excel 要引用关联表格的两个列就得写两遍 VLookup。
SPL 显然不会没考虑到这个问题,这种对于结构化数据来讲属于家常便饭的操作不能搞得这么麻烦。SPL 提供了 switch 函数来实现外键的关联运算:
A |
B |
C |
|
… |
… |
||
5 |
>A3.switch(dept,A2) |
||
6 |
=A3.new(eid,dept.name:dept,dept.manager) |
||
switch 函数将把外键字段转换成对应的维表记录,A5 的代码相当于执行了一句:
>A3.run(dept=A2.find(dept))
执行 A5 前看 A3 的值(可以使用调试功能),是下面这样,dept 字段是整数:
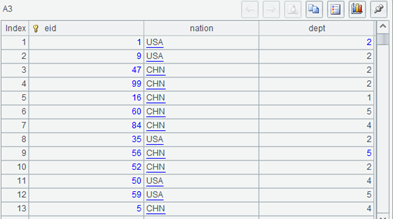
执行之后再看 A3,dept 字段看起来仍然是整数,但变了颜色也显示到左边了:
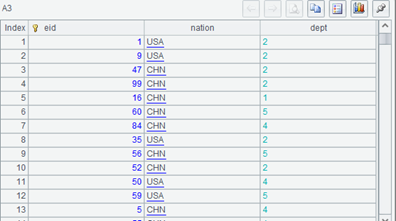
双击某个 dept 的值,值显示区域可能出现这样的结果:

dept 字段的取值已经变成记录,双击它后将显示这条记录的详细信息。刚才显示的变了颜色的数值实际上是这条记录的主键。
即然是记录,那么当然就可以引用它的字段了,A6 中的 dept.name 和 dept.manager 就都能正常计算了。
之所以用 switch 这个函数名,是因为它还可以把取值为记录的字段转换回来:
A |
B |
C |
|
… |
… |
||
5 |
>A3.switch(dept,A2) |
||
6 |
=A3.select(dept.name=="R&D") |
||
7 |
>A3.switch(dept) |
||
A5 将外键转换成维表的记录,A6 就可以使用它引用维表记录的字段了,到 A7 又将现在取值为记录的字段再转回来,A7 相当于执行了
>A3.run(dept=dept.key())
不过,转换回来的情况很少见。
被 switch 处理过后,这两个表的记录感觉真地连到了一起,这个表的字段取值是另一个表的记录,可以通过这个字段去引用另一个表的字段了。这比 VLookup 方便了许多。
相应地,部门表中的 manager 字段也是外键,也可以转换成人员表中的记录。
比如,我们想统计有多少美国员工的经理是中国人:
A |
B |
C |
|
… |
… |
||
5 |
>A3.switch(dept,A2) |
>A2.switch(manager,A3) |
|
6 |
=A3.count(nation=="USA" && dept.manager.nation=="CHN") |
||
外键关系可能有多层,这时候如果还使用 find 方法,就会很难描述(有兴趣的读者也可以尝试想想 Excel 中如何用 VLookup 实现这种多层关联)。被 switch 转换之后的外键,点操作符可以形象地理解成“的”,A6 中的 dept.manager.nation 可以解读为当前员工的部门的经理的国籍,很多层次也不会觉得困难,这样的语法即书写简单也容易理解。
通常,外键字段的取值一定会在维表的主键取值范围内,但有时候也会出现超出的情况。比如新员工在尚未确定所属部门前,dept 字段都被填成了 0,部门表中没有对应的记录。
A |
B |
C |
|
… |
… |
||
4 |
=A2.run(A3(manager).dept=did) |
>C1.to(90,).run(A3(~).dept=0) |
|
5 |
=A3.switch(dept,A2) |
=A5.count(dept.name==null) |
|
5 |
=A3.switch@i(dept,A2) |
=A5.count(dept.name==null) |
|
5 |
=A3.switch@d(dept,A2) |
=A5.count(dept.name==null) |
|
我们在生成数据的代码 B4 中故意找了一些员工的 dept 填成 0,然后可以观察这三种 A5 分别会计算出什么结果。注意要分别执行,不能顺序执行,因为执行完之后 A3 将会被改变,再继续执行另一种 A5 就没有意义了。
switch 找不到外键对应的维表记录时会将外键填成 null,之后再引用其字段时并不会报错,只是会返回 null,相应的 B5 将不会为 0。@i 选项将删除找不到外键对应记录的事实表记录,保证 switch 之后的事实表记录的外键都正确转换成维表记录了,相应的 B5 将返回 0。而 @d 则将只保留找不到外键对应记录的事实表记录,并且无法再做外键转换,相应的 B5 就会报出错误。
使用外键关联两个数据表,经常是为了将维表的某些字段临时拼到事实表上(也就是 VLookup 干的事),大多数情况并不打算改变事实表的字段。switch 函数用来进行关联运算虽然方便,但它却会改变原事实表的外键字段值,如果只是想追加维表字段的话,使用 switch 后还要再多做一步转换将已经变成记录的外键再转换回来,这就比较麻烦了。而且,如果再碰到刚才说的有对应不上的情况,外键将被填成 null,信息已经丢失,无法转换回来了。
SPL 提供了 join 函数来实现这种目标:
A |
B |
C |
|
… |
… |
||
4 |
=A2.run(A3(manager).dept=did) |
>C1.to(90,).run(A3(~).dept=0) |
|
5 |
=A3.join(dept,A2,name:deptname,manager:manager) |
||
A5 将在序表 A3 的基础上增加 deptname 和 manager 字段,分别填入员工的部门名称和经理编号,dept 字段将保持原样,找不到对应的维表记录时,会导致新加入的字段填成 null。
join 函数会产生一个新序表,原来 A3 并不会改变。
join 函数还可以支持多字段的主键和外键,因为不常见,这里不再举例了,需要使用时可以查阅 SPL 的相关文档,也能再体会层次参数的必要性。
switch 函数不支持多字段主键的维表,它只能转换单字段外键。
使用外键到维表中查找对应记录,以引用关联记录的某些字段,这是很常见的情况。不过,业务是复杂的,有时关联记录并不能简单用外键来确定,而需要一个与区间有关的条件。
回到前面章节中常用到的人员表,并造一个 BMI 对照表:
A |
B |
|
1 |
=100.new(string(~):name,if(rand()<0.5,"Male","Female"):sex,50+rand(50):weight,1.5+rand(40)/100:height) |
|
2 |
=A1.derive(weight/height/height:bmi) |
|
3 |
[null,20,25,30] |
[UnderWeight,Normal,OverWeight,Fat] |
4 |
=A3.new(~:low,~[1]:high,B3(#):type) |
|
现在我们想在有 BMI 信息的人员表 A2 上加个字段,列出每个人的体重类型。
如果把 BMI 对照料表 A3 作为维表(有要被引用的字段),它有 low 和 high 字段来表示某个体重类型的 BMI 区间,但并没有什么适合作主键的字段(虽然 low 和 high 都有唯一性)。人员表 A2 中看起来也没有字段可以充当外键。但是,显然 A2 和 A4 会存在一种关联,A2 的每条记录都会和 A4 的某条记录对应。
区间关联也是一种常见的关联,那么它该怎么实现?
简单地使用 select 函数当然可以,类似本节开始使用 find 一样。
A |
B |
|
… |
… |
|
5 |
=A2.derive(A4.select@1(low<=bmi && (!high || high>bmi)).type) |
|
这里要判断 high 是空的情况(表示最后一段),low 不用判断,因为 SPL 规则 null 是最小的,null<=bmi 总会得到 true。
其实,区间关联也能被理解为外键关联。如果我们把 BMI 对照表做一些改造,再在人员表增加用 pseg 函数计算出来的 BMI 区段序号,就可以看出外键关系了。
A |
B |
|
… |
… |
|
3 |
[null,20,25,30] |
[UnderWeight,Normal,OverWeight,Fat] |
4 |
=A3.new(#:no,~:level,B3(#):type).keys(no) |
|
5 |
=A2.derive(A4.(level).pseg(bmi)+1:bmitype) |
|
6 |
=A5.switch(bmitype,A4) |
|
经过改造的 BMI 对照表 A3 有了主键,可以作为维表。A5 增加出来的 bmitype 字段则是指向 A3 的外键,也可以用 switch 建立关联。
区间关联本质上也是外键关联。
为人员表单造一个外键实在有点麻烦,其实我们写成上面这样主要是为了帮助读者理解外键概念可以延伸到这种情况。实际上会直接用 pseg 拼出目标字段。
A |
B |
|
… |
… |
|
3 |
[null,20,25,30] |
[UnderWeight,Normal,OverWeight,Fat] |
4 |
=A3.new(~:level,B3(#):type) |
|
5 |
=A2.derive(A4(A4.(level).to(2,).pseg(bmi)+1).type) |
|
区间关联过程一般都不会专门生成外键,但仍然可以延用维表和事实表的概念。
如果情况像这个例子这样只有 type 字段需要被引用,我们甚至都不会生成那个对照表了,而是直接用序列和 pseg 来计算并引用。
A |
B |
|
… |
… |
|
3 |
[20,25,30] |
[UnderWeight,Normal,OverWeight,Fat] |
4 |
=A2.derive(B3(A3.pseg(bmi)+1):type) |
|
和所有外键关联一样,区间关联也是多对一的关联。即使没有生成维表,这个关联关系仍然在逻辑上存在。

