


在 Excel 中使用集算器 add-in
本篇内容已过期,新版文档 Excel 插件使用说明
集算器支持Excel add-in接口,既可以在单元格调用集算器表达式,也可以在单元格或VBA中调用集算器脚本文件。
一、环境配置
应在windows操作系统下配置JDK、集算器、Excel,对于最常见的64位windows,三个软件的位数必须保持一致,即都是32位,或都是64位。
JDK
集算器自带JDK,如果本机原先没有JDK,则建议跳过本步骤,在下一步安装。如果本机的JDK可卸载,建议用JAVA或Windows官方提供的工具正常卸载,再进入下一步。
如果本机已安装JDK(1.8或以上版本),且有重要用途不宜卸载,则应确保注册表信息正确,其中64位JDK的位置在:
\HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\javasoft\Java\Runtime Enviroment |
集算器
正常安装集算器,可以选装自带的JDK,也可以指向本机已安装的JDK。
Excel
在Excel中打开对话框:file->Option->add-ins
在对话框中点击Go…按钮,导航到集算器add-in:[esProc的安装目录]\bin\ExcelRaq.xll。
重启Excel,使配置生效。
二、基本用法
通过名为esproc的函数,可以在Excel单元格中调用集算器表达式。比如A列是逗号分隔的数字,B列是单个数字:
A |
B |
|
1 |
1,2,3,4,5,6 |
3 |
2 |
7,45,31,12,-10 |
4 |
3 |
9,7,5,3,2 |
5 |
现在要在C列的每行计算出:A列中比B列大的那些数中,最小的是哪个数,结果应当如下:
A |
B |
C |
|
1 |
1,2,3,4,5,6 |
3 |
4 |
2 |
7,45,31,12,-10 |
4 |
7 |
3 |
9,7,5,3,2 |
5 |
7 |
要计算本题,应当先在C1编写表达式:
=esproc("=?.split@cp().sort().select@1(~>?)",A1,B1)
回车后,将C1格下拉或复制到C3,即可完成计算。
表达式中的函数split将字符串按分隔符拆分成数组(序列),@c表示按逗号拆分,@p表示自动转换类型。函数sort实现排序,select实现条件查询,@1表示返回第1个。
参数可以是多个。表达式中的问号是参数占位符,有几个参数就有几个问号,这是集算器表达式的特色。
参数的格式遵循Excel规范。可以是B1这种复制时自动变更坐标的参数,或$B$1这种固定坐标的参数,以及跨sheet、跨文件的参数。集算器也支持片区参数,比如A1:D5,亦可通过鼠标选择生成片区参数。
三、以片区为参数
片区参数在格式上遵循Excel规范,本质上是集算器的序列数据类型。比如下面的字母数字表中,奇数行是唯一字母,偶数行是数字:
A |
B |
C |
D |
E |
|
1 |
A |
H |
M |
B |
T |
2 |
39 |
2 |
14 |
9 |
20 |
3 |
F |
W |
P |
L |
C |
4 |
6 |
35 |
11 |
4 |
22 |
5 |
Y |
D |
V |
E |
U |
6 |
6 |
5 |
7 |
18 |
27 |
现在要将奇数行的字母按照先横后纵的顺序拼接起来,即:AHMBTFWPLCYDVEU。
要计算本题,只需在F1输入表达式:=esproc("=?.step(2,1).conj().concat()",A1:E6)
表达式中的step(2,1)取序列中奇数位置的成员(行),conj可将多维序列合并为一维序列,concat将序列拼接为字符串。
如果片区参数是多列的,则被解析为序列(横向)组成的序列(纵向),可用?(N)来访问第N行,用?(N)(M)来访问第N行的第M列。如果片区参数是单列,则被解析为一维序列,可用?(N)来访问第N个成员。
四、输出单列片区
如果计算结果是单列片区,则应当选中要输出的所有单元格,然后在公式栏输入公式,最后按ctrl+shift+enter。
比如根据字母数字表,将奇数行的字母按照先横后纵的顺序,依次显示在H列,如下图:
H |
A |
H |
M |
B |
T |
F |
W |
P |
L |
C |
Y |
D |
V |
E |
U |
要计算本题,应该使用公式1:=esproc("=?.step(2,1).conj()",A1:E6)。但在输出之前,我们要知道会占多少格单元格,可以口算,也可以用公式2:=esproc("=?.step(2,1).conj().len()",A1:E6)
公式2的计算结果是15,因此应该选中H1:H15,再输入公式1。
最后按下ctrl+shift+enter,即可获得计算结果。
五、输出多列片区
要输出成单列片区,数据必须整理成简单类型组成的数组(序列);要输出成多列片区,数据必须整理成记录组成的结构化数据(序表),两者的数据类型和生成方式不同。
比如D1:I6片区的第1行是列名,其他行有些格为空,有些格有数据,有数据的格一定是连续的。如下所示:
A |
B |
C |
D |
E |
F |
G |
H |
I |
|
1 |
4.5.2020 |
5.5.2020 |
6.5.2020 |
7.5.2020 |
8.5.2020 |
9.5.2020 |
|||
2 |
Data |
data |
|||||||
3 |
Data |
data |
Data |
Data |
data |
||||
4 |
data |
Data |
Data |
data |
data |
||||
5 |
Data |
data |
Data |
Data |
data |
data |
|||
6 |
Data |
Data |
data |
data |
现在要在A列和B列分别算出连续有数据的格的起始列的列名,以及终止列的列名。如下所示:
A |
B |
C |
D |
E |
F |
G |
H |
I |
|
1 |
start date |
end date |
4.5.2020 |
5.5.2020 |
6.5.2020 |
7.5.2020 |
8.5.2020 |
9.5.2020 |
|
2 |
4.5.2020 |
5.5.2020 |
Data |
data |
|||||
3 |
4.5.2020 |
8.5.2020 |
Data |
data |
Data |
data |
data |
||
4 |
5.5.2020 |
9.5.2020 |
data |
Data |
data |
data |
data |
||
5 |
4.5.2020 |
9.5.2020 |
Data |
data |
Data |
Data |
data |
data |
|
6 |
6.5.2020 |
9.5.2020 |
Data |
Data |
data |
data |
要计算本题,只需选中A1:B6,输入表达式:=esproc("=?.new(~.pselect(~):start,~.pselect@z(~):end).new(?2(start):'start date',?2(end):'end date')",D2:I6,D1:I1)
集算器函数pselect可算出序列中顺序第1个不为空的成员的位置,pselect@z()可算出逆序第1个不为空的成员的位置。函数new可生成新的序表。
表达式中有两处?2,这表示第2个参数,即D1:I1,这种表达形式便于多次引用同一个参数。类似地,第一个?写成?1也正确。
最后按下ctrl+shift+enter,即可获得计算结果。
注意:如果不想输出列头,可使用esprocT函数。本例不仅输出结果是多列,输入参数也是多列,与输出不同的是,输入参数不论单列或多列,数据类型都统一为序列。
六、自动输出片区
应该注意到,先手动计算位置再输出片区是比较麻烦的操作,为了使这一过程自动化,可使用集算器加载时宏文件esproc_template.xla,该文件原位置在[esProc的安装目录]\bin。
下面以计算起始列名和终止列名为例进行说明。
1. 将集算器加载时宏文件从原位置复制到[Excel的安装目录]\XLSTART。
2. 重新启动Excel文件,在第1行插入空行,如下:
A |
B |
C |
D |
E |
F |
G |
H |
I |
|
1 |
|||||||||
2 |
4.5.2020 |
5.5.2020 |
6.5.2020 |
7.5.2020 |
8.5.2020 |
9.5.2020 |
|||
3 |
Data |
data |
|||||||
4 |
Data |
data |
Data |
Data |
data |
||||
5 |
data |
Data |
Data |
data |
data |
||||
6 |
Data |
data |
Data |
Data |
data |
data |
|||
7 |
Data |
Data |
data |
data |
3. 在A1格输入表达式:=esproc("=?.new(~.pselect(~):start,~.pselect@z(~):end).new(?2(start):'start date',?2(end):'end date')",D3:I7,D2:I2)
注意原数据下移了一行,因此参数要做相应变化。
之后按下ctrl+enter,即可从下一行开始自动输出结果,如下:
A |
B |
C |
D |
E |
F |
G |
H |
I |
|
1 |
start date |
||||||||
2 |
start date |
end date |
4.5.2020 |
5.5.2020 |
6.5.2020 |
7.5.2020 |
8.5.2020 |
9.5.2020 |
|
3 |
4.5.2020 |
5.5.2020 |
Data |
data |
|||||
4 |
4.5.2020 |
8.5.2020 |
Data |
data |
Data |
Data |
data |
||
5 |
5.5.2020 |
9.5.2020 |
data |
Data |
Data |
data |
data |
||
6 |
4.5.2020 |
9.5.2020 |
Data |
data |
Data |
Data |
data |
data |
|
7 |
6.5.2020 |
9.5.2020 |
Data |
Data |
data |
data |
通常,数据和表达式将来可能发生变化,因此第1行可暂时隐藏起来;如果不再变化,也可删除第1行。、
说明:此方法适用于任意输出数据,包括单列和单值(单值意义不大)。
七、单元格调用脚本文件
如果表达式较复杂(比如涉及流程控制语句),或希望复用和调试,则应当把表达式写在集算器脚本文件中,然后在Excel单元格中调用脚本文件。
下面以计算起始列名和终止列名为例进行说明。
1. 新建集算器脚本文件,并添加两个参数:data和title,分别代表输入的数据和列名。
2. 编写如下脚本。
A |
|
1 |
=data.new(~.pselect(~):start,~.pselect@z(~):end) |
2 |
=A1.new(title(start):'start date',title(end):'end date') |
3 |
return A2 |
3. 将脚本保存为getColName.splx,保存在集算器的Main path目录下。参考下图:
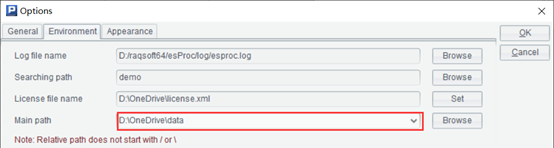
4. 在Excel的A1:B6输入公式:=esproc("getColName",D2:I6,D1:I1)
5. 最后按下ctrl+shift+enter,即可获得计算结果。
说明:集算器加载时宏文件对单元格中的集算器脚本文件同样有效。
八、VBA调用脚本文件
在VBA中调用脚本文件,可使用Application.Run函数,下面以计算起始列名和终止列名为例。
Sub Test(): rowStart = 1 colStart = 1 Application.ScreenUpdating = False With Sheets(1) ret = Application.Run("esproc", "getColName", Range("D2:I6"), Range("D1:I1")) r = UBound(ret, 1) c = UBound(ret, 2) rowEnd = rowStart + r - 1 colEnd = colStart + c - 1 Range(Cells(rowStart, colStart), Cells(rowEnd, colEnd)) = ret End With End Sub |

