


枚举维度与二值维度切片的优化
【摘要】
多维分析(OLAP)中常见的枚举维度切片(过滤条件 in)和二值维度(是否型过滤条件)如何优化?点击了解枚举维度与二值维度切片的优化
问题描述
多维分析(OLAP)系统的汇总和切片,实际上是在计算分组汇总和条件过滤。切片过滤条件的情况多种多样,其中比较多的是枚举维度切片和二值维度切片。
枚举维度切片是指过滤条件中的in计算,例如:D5 in (valueB,valueC),也就是过滤条件字段在一个枚举范围内取值的情况。在实际应用中,“按照客户性别、员工部门、产品类型等切片”就属于枚举维度切片的情况。二值维度切片是过滤条件中的是否型计算,例如:D6 =true and D7=false and D8=true。实际应用中的“客户是否属于某几个客群,或者是否属于某几个标签”等就属于二值维度切片。
包含枚举维度和二值维度的多维分析计算,用SQL表示为:
SELECT D1,…,SUM(M1),COUNT(ID)… FROM T GROUP BY D1,…
WHERE Di in (di1,di2…) and Dj =true …
分析过程中,用户选择众多的维度作为where条件时,计算性能会很明显的下降。特别是条件中出现很多in计算,或者有很多二值维度条件都要满足的时候,性能下降的更为明显。
这里我们讨论如何优化in和二值维度条件计算,从而整体提升多维分析性能。
为了方便讲解,我们将上述SQL具体化如下:
SELECT D1,D2,D3,D4,SUM(M1),COUNT(ID) FROM T GROUP BY D1,D2,D3,D4
WHERE D5 in (valueB,valueC) and D6 =true and D7=false and D8=true
假设“D1和D2”、“D3和D4”都是层次关系的维度(“省和市”、“部门和员工”等)。两个汇总值,SUM(M1)是指数值字段M1求和,COUNT(ID)是指对主键ID字段计数。T是指进行OLAP计算的事实表。过滤条件为:D5的值是(valueB,valueC)其中一个,并且D6的值为true、D7为false、D8为true。
这个SQL计算的结果集可以呈现为下面的交叉表:

图1、结果集呈现的交叉表
在多维分析系统中,一般的存储结构如下图:
事实表T:
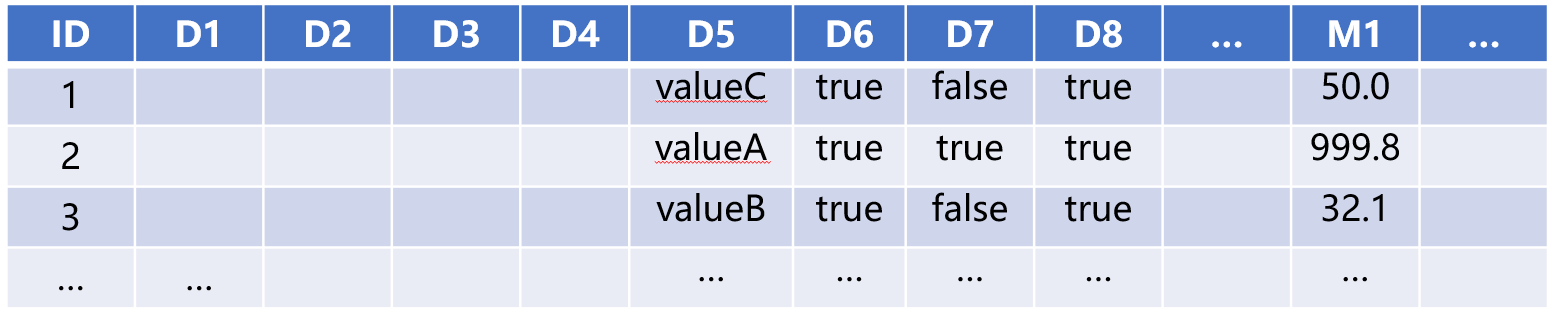
维表DT1:
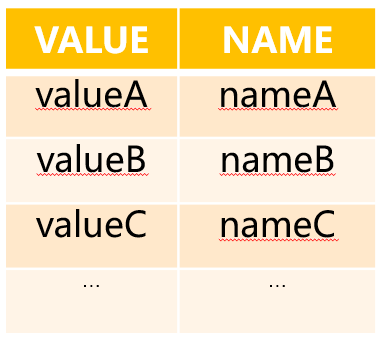
图2、数据结构
in计算需要遍历事实表中的数据,每一行数据中的枚举维度值都要和多个枚举值进行比较。假设枚举值的个数是n,事实表中的每一行枚举维度平均都要比较n/2次,计算性能会随着n的增大而明显降低,当n较大时性能会很差。即使n较大时使用二分法,比较次数也还是很多。
是否型计算也需要比较判断。是否型条件比较多的时候,事实表遍历计算性能也会很差。在实际应用中,有可能会出现是否型的维度非常多的情况,比如客户有几千个是否型的标签。如果在事实表中增加几千个字段存储二值维度数据,对于关系数据库来说无法承受。因此需要另外建一个关系表(比如字段为ID、TAG)。再通过事实表和关系表关联(join)来实现二值维度的切片计算。在事实表和关系表数据量都比较大时,两个大表关联性能较差。
枚举维度:布尔维
布尔维是指用布尔值代替字符串或者数值,进行枚举维度的切片计算。上面提到的多维分析计算,在用布尔维优化之前需要对事实表T预处理,如下图:
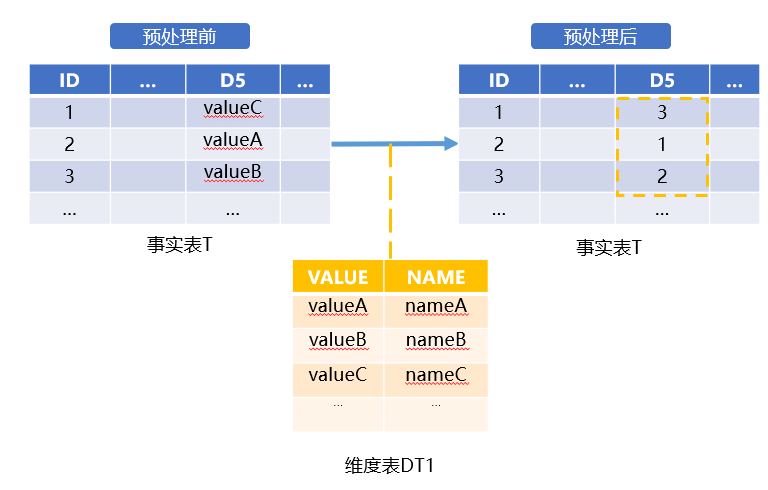
图3、对事实表T的预处理
预处理是将事实表中的D5字段,转换成维表DT1的序号。例如:ID为1的数据,D5是valueC,在DT1表中是第三条记录,所以预处理时要把D5的值转换成数值3。ID为2的数据,D5是valueA,在DT1表中是第一条记录,所以要转换成1。其他行依此类推。虽然事实表数据量比较大,预处理时间比较长,但是历史数据一般不发生变动,因此预处理是一次性完成的,不会影响多维分析的查询计算速度。
预处理之后,在枚举维度切片计算时就可以对事实表T采用布尔维序列的方法了。如下图:
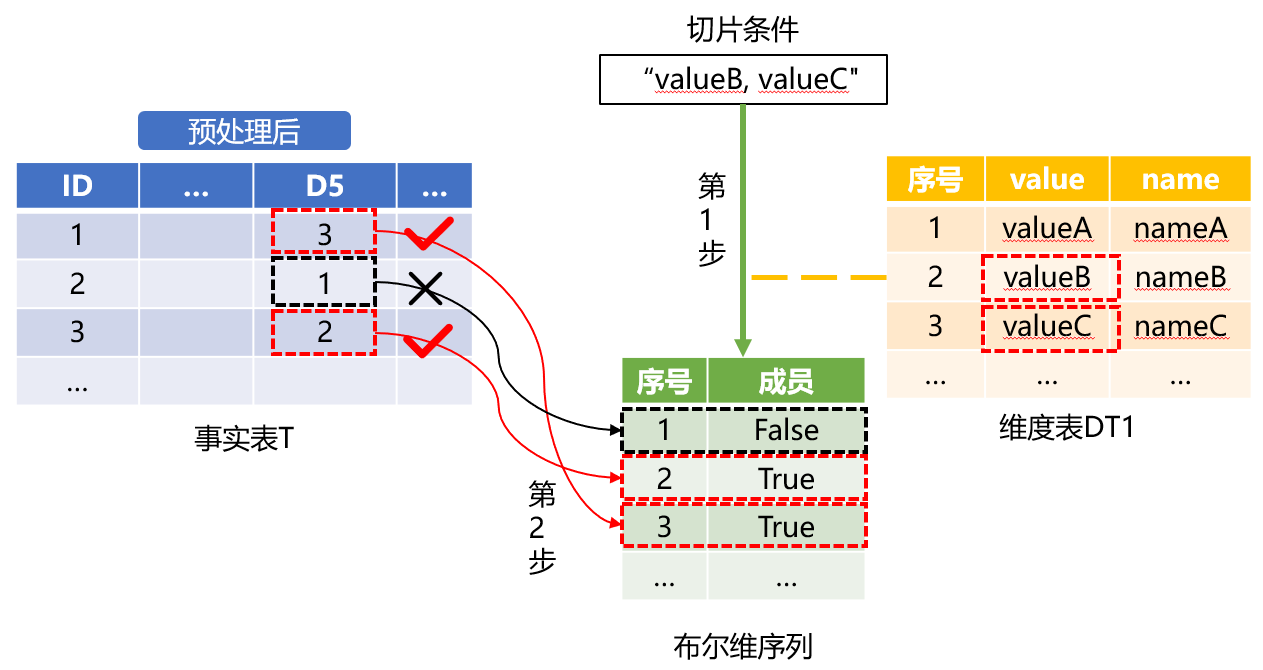
图4、用布尔维序列过滤事实表
图中第1步:准备布尔维序列;第2步:应用布尔维序列过滤事实表。
切片条件是从前端传入的参数,也就是枚举值:"valueB,valueC"。计算时要根据DT1表转换成布尔维序列。具体的实现可以采用Java、C++、SPL等高级语言。这里我们以代码量最少的SPL语言为例讲解。计算满足D5条件的结果集,代码示例如下:
A |
B |
|
1 |
="valueB,valueC" |
|
2 |
valueA |
nameA |
3 |
valueB |
nameB |
4 |
valueC |
nameC |
5 |
=create(value,name).record([A2:B4]) |
|
6 |
=A1.split(",") |
=A5.(A6.contain(value)) |
7 |
=file("data/ctx/T.ctx").open().cursor(;B6(~.D5)) |
|
8 |
return A7.groups(~.D1,~.D2,~.D3,~.D4;sum(~.M1):S,count(ID):C) |
|
代码示例1
第1步准备布尔维序列:
A1:传入参数,D5的枚举项。为了描述简单,暂以常数形式出现。
A2-B4:准备DT1表数据。
A5:构成DT1表,真实应用中应该从文件或者数据库中读取,也可以在系统初始化时预先加载为全程变量。
A6:将传入参数用逗号分隔符解析成序列。运行结果:
Index |
Member |
1 |
valueB |
2 |
valueC |
B6:循环计算A5,生成序列,如果当前行D5的值包含在A6中,序列成员就设置为true,否则设置为false。运行结果:
Index |
Member |
1 |
false |
2 |
true |
3 |
true |
可以看到,传入参数中包含的value值,在B6中都被计算成true了,参数中没有的就是false。B6就是布尔维序列。
第2步用布尔维序列过滤事实表T:
准备好布尔维序列之后,就可以用来过滤预处理之后的事实表数据。
A7:定义对事实表T文件游标的循环计算。计算方法为:第一行D5为3,在布尔维序列中找到第3个成员值为true,则第一条记录符合过滤条件。第二行D5为1,在布尔维序列中找到第1个成员值为false,则第二条记录不符合过滤条件。注意这里仅仅是定义了计算方法,还没有真的计算,是延迟游标。
A8:一边执行A7中定义的过滤计算,一边按照D1、D2、D3、D4分组汇总。最后得到结果集,返回给前端。
布尔维序列性能优势分析:
图4结合A7中的代码,我们可以看到事实表的每一行D5值,都不需要和多个枚举值进行比较,直接按照序号取出布尔值就可以了。也就是说,布尔维序列计算方法,是将原来in计算遍历事实表时的每行多次比较,转换成了直接按照位置取布尔值。省去了很多次的判断,因此性能会有很明显的提升。而且,布尔维序列的计算时间和枚举值的个数无关,解决了in计算时间随着枚举值个数的增加而增加的问题。
二值维度:按位存储
二值维度只有是否两种状态,只需要一个bit(位)就能保存。0表示false,1表示true。我们可以用整型数的32个bit保存二值维度值。
为了方便讲解,我们假设总共有8个二值维度,用整数字段c1存储8位二进制数表示。要用按位存储的方法计算二值维度切片,需要先将事实表预处理为按位存储,如下图:
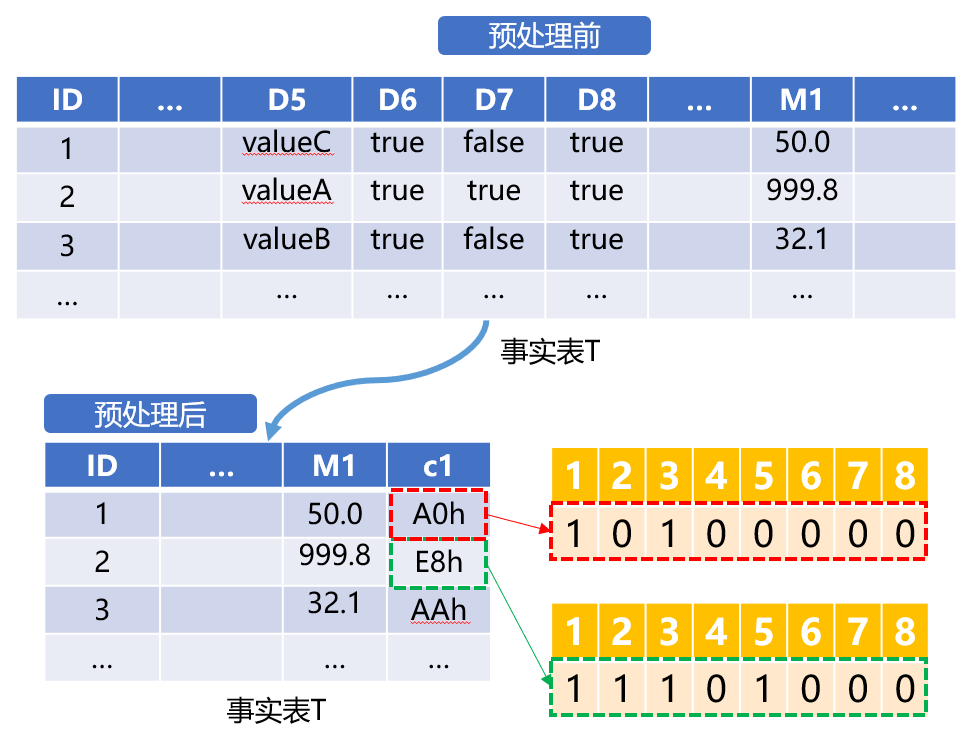
图5、将事实表预处理成按位存储
处理后的事实表,第一行c1为AFh,转换为二进制数为10100000,表示D6、D8是true,其他二值维度是false。第二行c1为E8h,转换为二进制数为11101000,表示D6、D7、D8都是true。在c1中,从左向右每一位分别对应原来的D6、D7、D8…二值维度字段的取值,0代表false,1代表true。
预处理之后,就可以对事实表T进行按位计算,实现二值维度切片了。如下图:

图6、按位计算二值维度切片
前端传入的切片条件为"2,3",也就是要过滤出第2个二值维度(D7)和第3个二值维度(D8)值是true,其他二值维度是false的数据。
图中第1步,我们要将传入条件转化为用二进制位来表示,代码示例如下:
A |
B |
|
1 |
="2,3" |
=A1.split@p(",") |
2 |
=to(8).(0) |
=B1.(A2(8-~+1)=1) |
3 |
=bits(A2) |
|
4 |
=file("data/ctx/T.ctx").open().cursor(;and(c1,A3)==A3) |
|
5 |
return A4.groups(~.D1,~.D2,~.D3,~.D4;sum(~.M1):S,count(ID):C) |
|
代码示例2
A1:传入参数。为了描述简单,暂以常数形式出现。
B1:将传入参数转化为序列,成员为数值型。结果为:
Index |
Member |
1 |
2 |
2 |
3 |
A2:创建一个全为零的序列,长度为8。
B2:用B1来循环计算,将A2与B1的每个成员的对应位置设置为1。例如:B1第一个成员是2,就将A2的第7个成员设置为1;B2第二个成员是3,就将A2的第6个成员设置为1。这样做是为转化二进制数做准备。计算后A2为:
Index |
Member |
1 |
0 |
2 |
0 |
3 |
0 |
4 |
0 |
5 |
0 |
6 |
1 |
7 |
1 |
8 |
0 |
B3:使用bits函数,将A2生成对应二进制整数。也就是先将A2看为二进制数01100000,求出对应的整数。在集算器中显示为十进制数140。B3就是准备好的二进制条件。
图中第2步:利用二进制条件,通过位计算过滤事实表数据。
A4:对事实表游标定义循环计算。对照图6理解,先计算第一行,c1字段值为16进制A0h,也就是二进制的10100000,与A3中的二进制数01100000按位与计算,结果是00100000,不等于A3,所以第一行数据并不同时满足2、3两个二值维度(D7、D8)为true,是不过滤满足条件的,舍弃掉。第二行c1字段和A3按位与的结果还是A3,所以是满足过滤条件的,不舍弃,参加后面的分组计算。后续行的计算以此类推。
注意这里也只是定义了计算方法,还没有真正计算。
A5:一边进行A4中定义的循环计算,一边对满足条件的记录分组汇总。最后返回计算的结果集。
按位存储性能优势分析:
图6结合A4中的代码,我们可以看到事实表的8个是否型条件过滤,只要做一次按位与计算即可实现。这样就将原来二值维度的多次比较计算,转换成了一次按位与计算,因此性能会有很明显的提升。多个是否值转换为一个整数,还可以减少数据占用的存储空间。
枚举维和二值维同时计算
还是以SPL为例,同时计算需要合并代码示例1、2。代码示例1中A7之前和代码示例2中A4之前的部分,复制到一起即可。A7和A4开始合并为A10,代码示例如下:
A |
B |
|
1 |
="valueB,valueC" |
|
2 |
valueA |
nameA |
3 |
valueB |
nameB |
4 |
valueC |
nameC |
5 |
=create(value,name).record([A2:B4]) |
|
6 |
=A1.split(",") |
=A5.(A6.contain(value)) |
7 |
="1,2,3" |
=A7.split@p(",") |
8 |
=to(8).(0) |
=B7.(A8(8-~+1)=1) |
9 |
=bits(A8) |
|
10 |
=file("data/ctx/T.ctx").open().cursor(;B6(~.D5)&&and(c1,A9)==A9) |
|
11 |
return A10.groups(~.D1,~.D2,~.D3,~.D4;sum(~.M1):S,count(ID):C) |
|
代码示例3
A10:同时定义布尔维序列和按位存储两种过滤计算。
A11:一边进行A10中定义的循环计算,一边对满足条件的记录分组汇总。最后返回计算的结果集。
外存和内存
上面的例子是外存文件游标的过滤计算。实际上,布尔维序列和按位存储也可以提高内存数据的枚举值和二值维度条件过滤的计算性能,原理上和外存计算是一样的。
实际应用中可以根据数据量大小和硬件的情况,来选择外存和内存方案。
预处理为小整数
布尔维序列和按位存储,都用到了整数类型。OLAP计算引擎如果是Java实现的话,可以考虑用预处理为小整数(16位整数)的方法,进一步提高性能。
先要在内存中预生成所有小整数(0到65535)的对象集合。从事实表文件中读取维度值或者初始化加载数据的时候,对于在0到65535范围内的小整数,不再在内存中新建小整数对象,而是直接引用小整数对象集合中的对应的成员。
小整数对象集的范围选择0到65535是比较适中的。如果范围太小,比如0到255,那么事实表大部分整数值都会超过这个范围,对性能的提升就不明显了。如果范围太大,比如0到2^32-1,整数对象集合本身就太大了,占用过多内存反而不利于性能提升。
对于Java应用来说,这样做可以减少对象创建,外存计算时可以提高文件读入内存的速度。也可以减少占用的内存存储空间。
对于SPL语言来说,小整数对象集是系统内置的优化机制,只要是小整数,都会自动应用这个机制。编写SPL的时候不需要额外的选项或者特殊的代码指定,非常方便。

