


怎样利用历史数据做商业预测
使用历史数据进行商业预测,首先我们要知道什么东西是能够被预测的,举几个例子:
-
银行放贷款时,希望预测出当前贷款人是否可能违约?
-
保险公司希望预测出客户的理赔风险,从而更灵活的制定保费,高风险高收费,低风险低收费
-
银行有很多种金融产品,希望预测出哪些用户会购买哪些产品,更精准的进行销售活动
-
工业生产中,企业希望预测设备的运行状态,减少非计划停车
-
商场超市希望预测出产品的销量,可以精准备货,降低库存
-
互联网金融信贷业务,希望预测出借资金的流动情况,合理管理现金流
……
……
如果我们手头有足够多的历史数据,那么这些任务都是可能做到的。比如任务 1,我们可以从过去多年的贷款信息记录中找出某种规律,这些信息包括贷款人的收入水平、负债情况,贷款金额、期限、利率以及贷款人的工作职位、居住条件、交通习惯等等,特别地,必须有过去这笔贷款是否发生过违约的信息。这样,再碰到新的贷款客户,可以根据该客户的各项信息来匹配规律,来确定当前客户违约的可能性有多大。当然,这种预测并不能保证 100% 准确(有很多种办法来评估它的准确率),所以如果只有一例目标(比如只有一笔贷款)需要预测时,那就没有意义了。但通常,我们都会有很多例目标需要预测,这样即使不是每一例都能预测正确,但能保证一定的准确率,这仍然是很有意义的。对于贷款业务,预测出来的高风险客户未必都是真的,但准确率只要足够高,仍然能够有效的防范风险。
用历史数据做预测,一共 3 个步骤:1 准备历史数据→2 从历史数据中找出规律,我们称之为建立模型→3 用建立的模型进行预测。
1. 准备历史数据
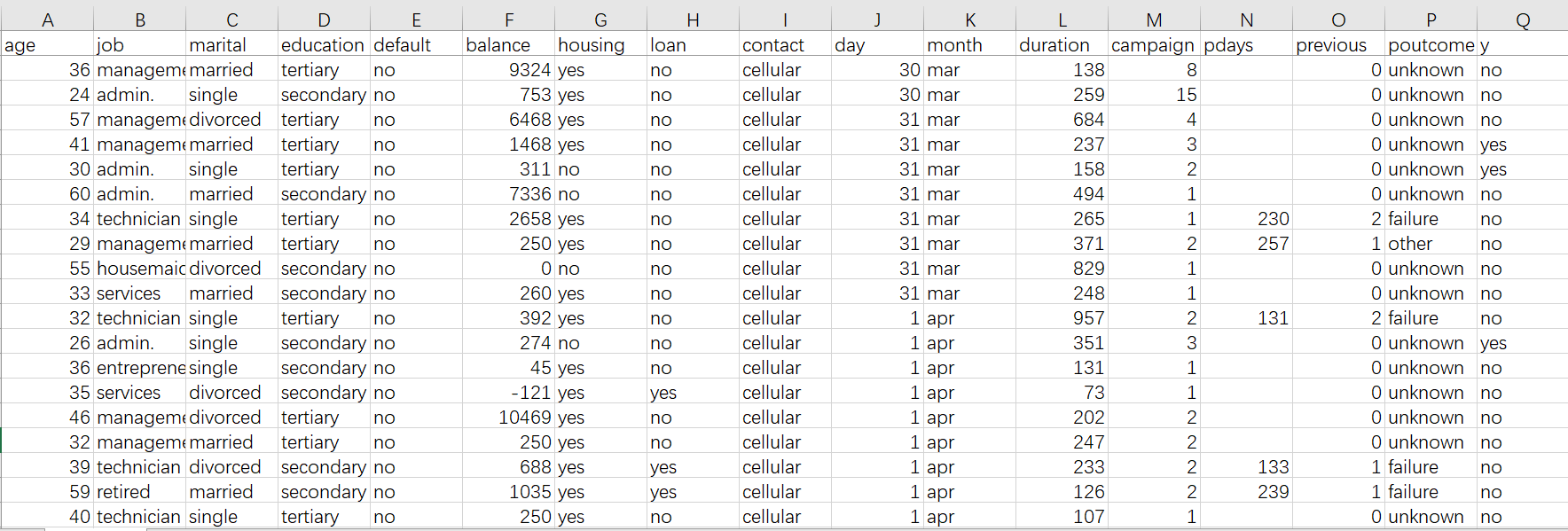
历史数据通常是一张我们俗称的宽表。比如下图这样的 Excel 表格:通过用户的一些基本信息来预测其是否会发生违约行为
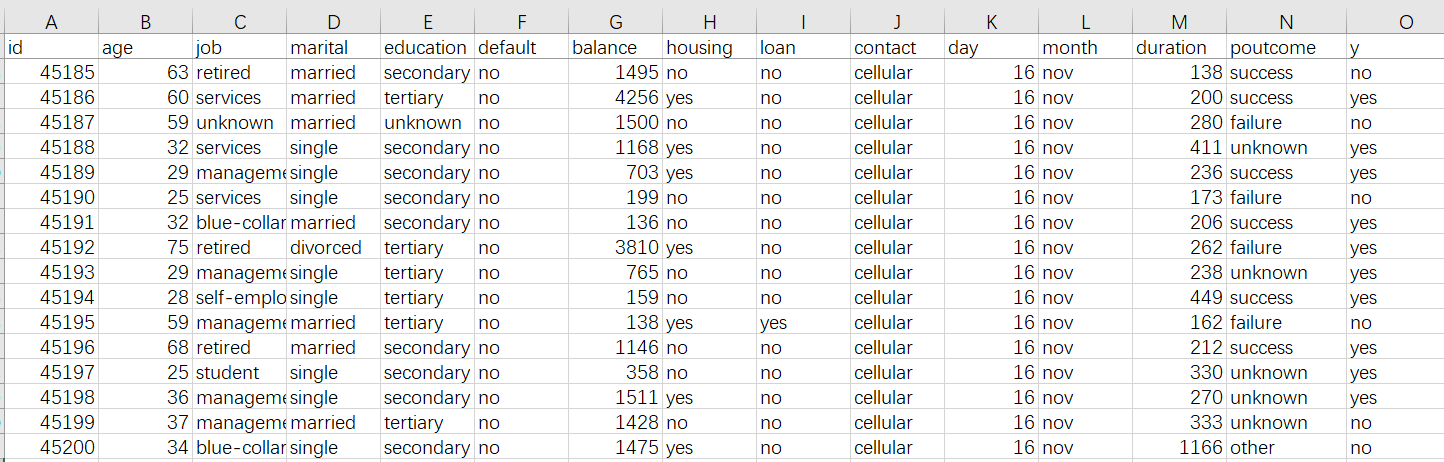
首先,宽表中一定要包括我们想预测的事情,通常称作预测目标,上图中的预测目标就是历史用户的违约行为,也就是图中 y 那一列,yes 表示违约,no 表示不违约。预测目标还可以是一个数值,比如产品的销量、售价……,或者是预测属于什么种类,比如预测产品质量是优、良、合格还是差。有时目标在原始数据里就有,可以直接使用,有时目标还需要人工标注。
除了预测目标外,这里还需要很多信息,如表中的用户年龄、工作,房产,贷款情况……,这里的每一列称为变量,也就是和贷款人将来是否违约可能会相关的信息,原则上能收集到的变量越多越好。例如预测客户是否会购买产品,可以搜集客户的行为信息,购物偏好,以及产品的特征信息,促销力度等;预测汽车保险理赔风险,需要保单数据,车辆信息、车主交通习惯以及历史理赔情况等等,如果是预测健康险还需要一些被保人的生活习惯,身体状况,就医看病的信息;预测商场超市的销售情况,需要历史的销售订单,客户信息,商品信息;预测不良产品,需要生产的工艺参数,环境,原料情况等数据。总之,收集到的相关信息越多,预测效果也会越好。
采集数据时,通常会截取某一段时期的历史数据来制作宽表,比如我们想预测 7 月份用户的违约情况,可以采集 1-6 月份的数据来建立模型。数据采集的时间范围并不是固定的,可以灵活操作,例如也可以是近 1 年或者近 3 个月等等。
准备好的宽表要保存成 csv 格式,第一行是标题,后面每一行都是一条历史记录,可以用 Excel 把数据另存为 csv 格式。
如果企业有建设好的信息系统,那可以找 IT 部门要这些数据,很多企业的 BI 系统中可以直接导出这种数据(可能格式不同,可以用 Excel 转换)。
2. 使用 YModel 建立模型
宽表准备好后,就可以用 YModel 来建立模型了。
YModel 是一款完全免费的、专门为业务人员和没有专业背景的初学者设计的建模神器,操作非常简单, 可以到 http://www.raqsoft.com.cn/download/download-ymodel 下载。
(1) 导入数据
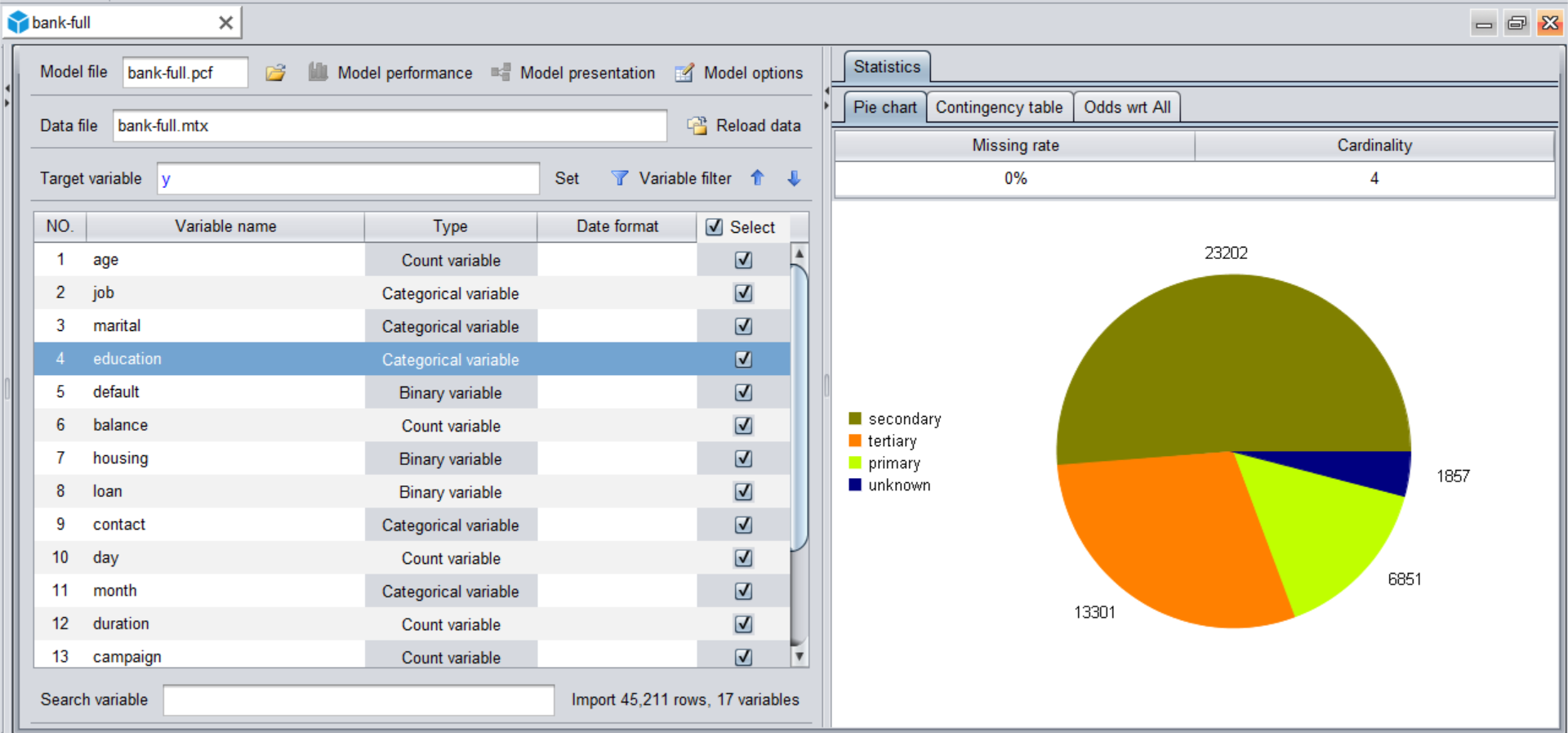
点击“New model”  按钮,导入数据(也就是整理好的宽表),数据导入的过程中 YModel 会自动检测数据类型,并自动计算各种统计量。
按钮,导入数据(也就是整理好的宽表),数据导入的过程中 YModel 会自动检测数据类型,并自动计算各种统计量。
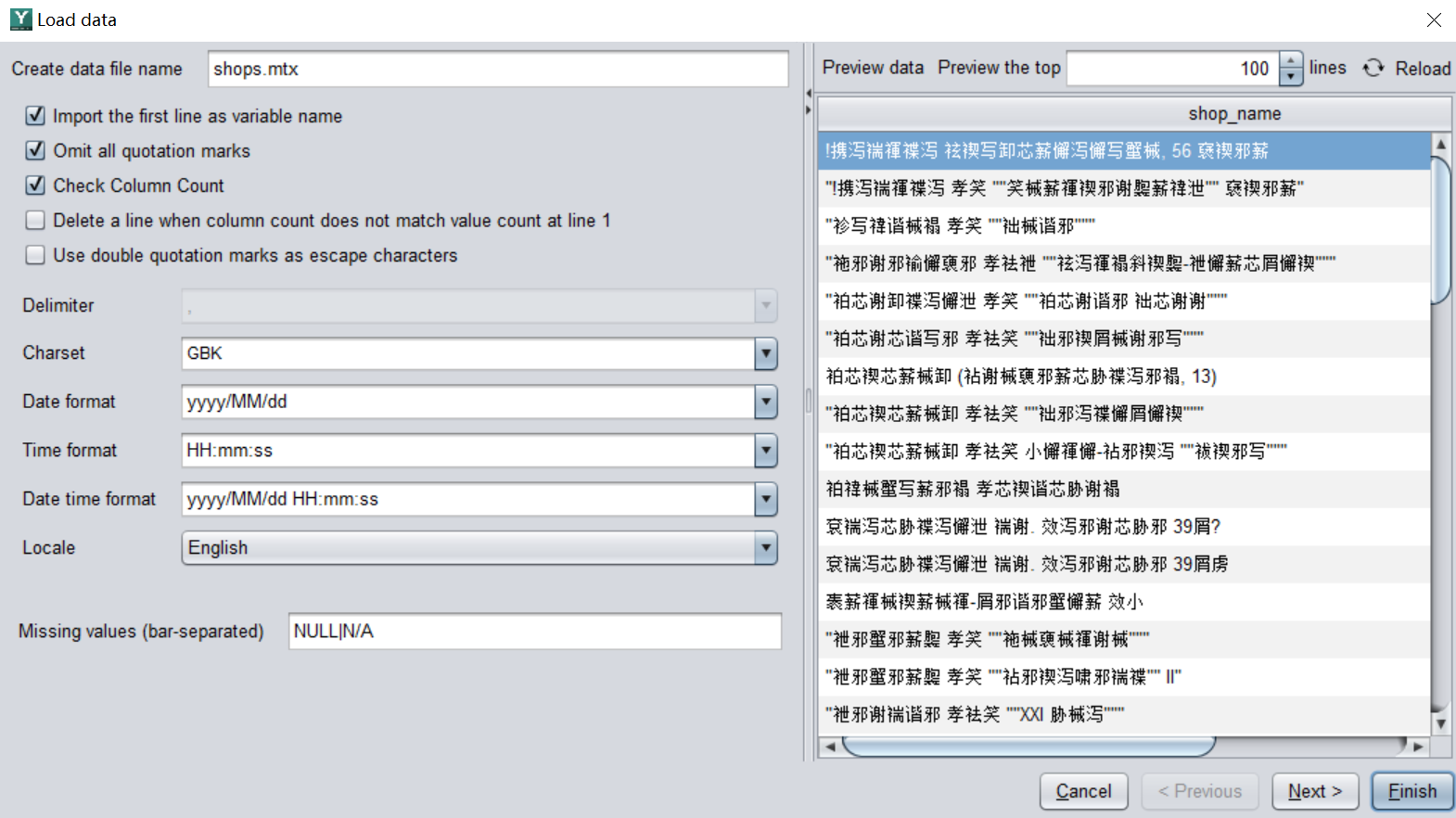
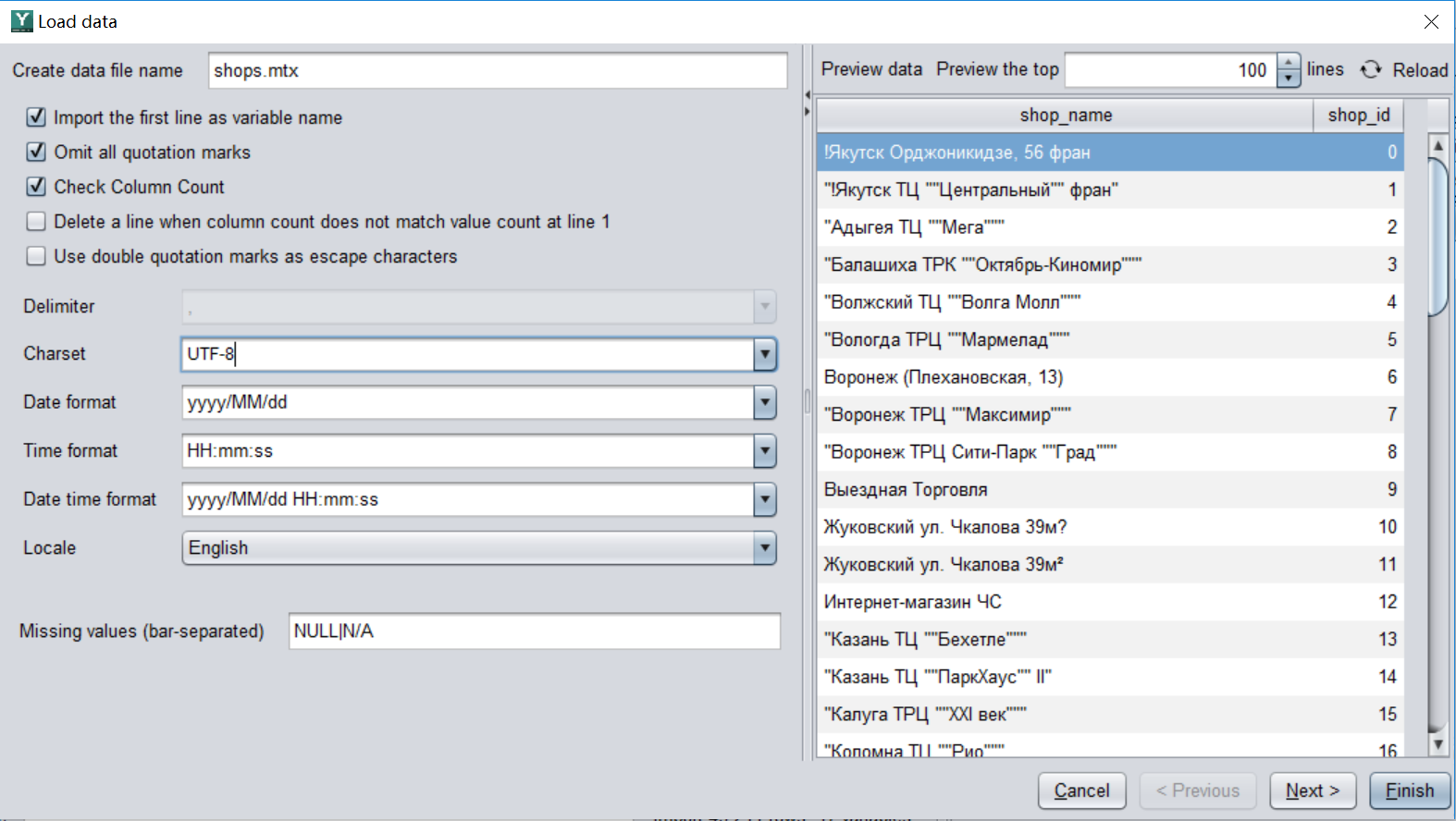
在初次导入的时候有时会出现一些错误,比如文字是乱码,日期格式不对,缺失值没有识别,只需要回到导入界面配置一下格式,再导入就可以了。比如下面两张图,通过数据预览发现”shop_name”列是乱码,这和默认的字符格式不一致。因此需要修改一下字符格式的配置,文字就可以正常识别了。
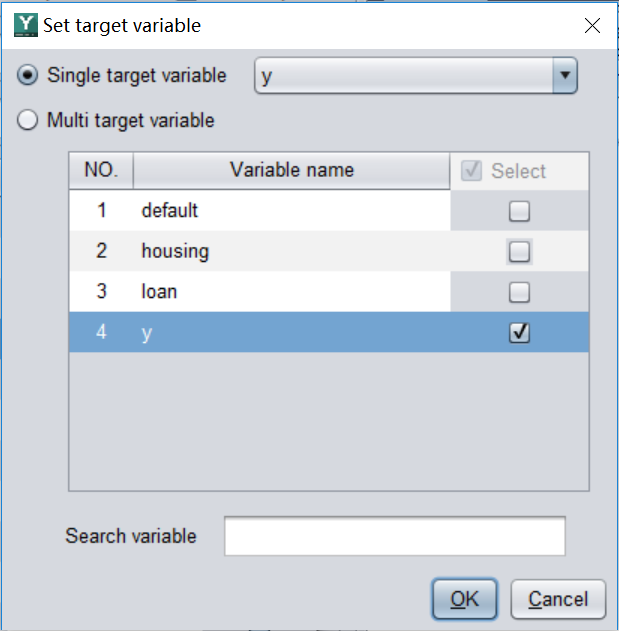
(2) 配置预测目标
导入数据后,配置预测目标。称为目标变量。
(3) 建立模型
配置好目标变量,点击”Modeling”  按钮,就可以了。整个数据预处理和建模过程都是自动进行的不需要人工操作。
按钮,就可以了。整个数据预处理和建模过程都是自动进行的不需要人工操作。
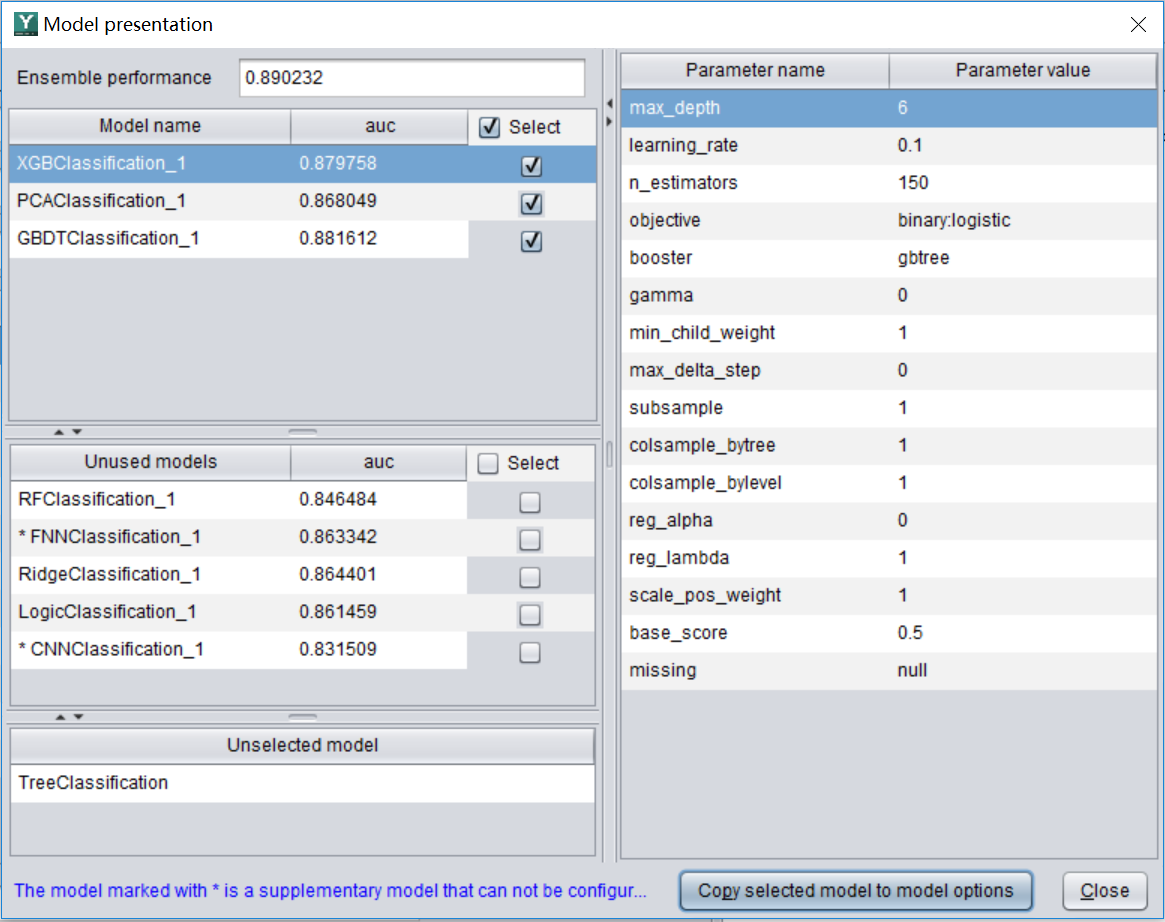
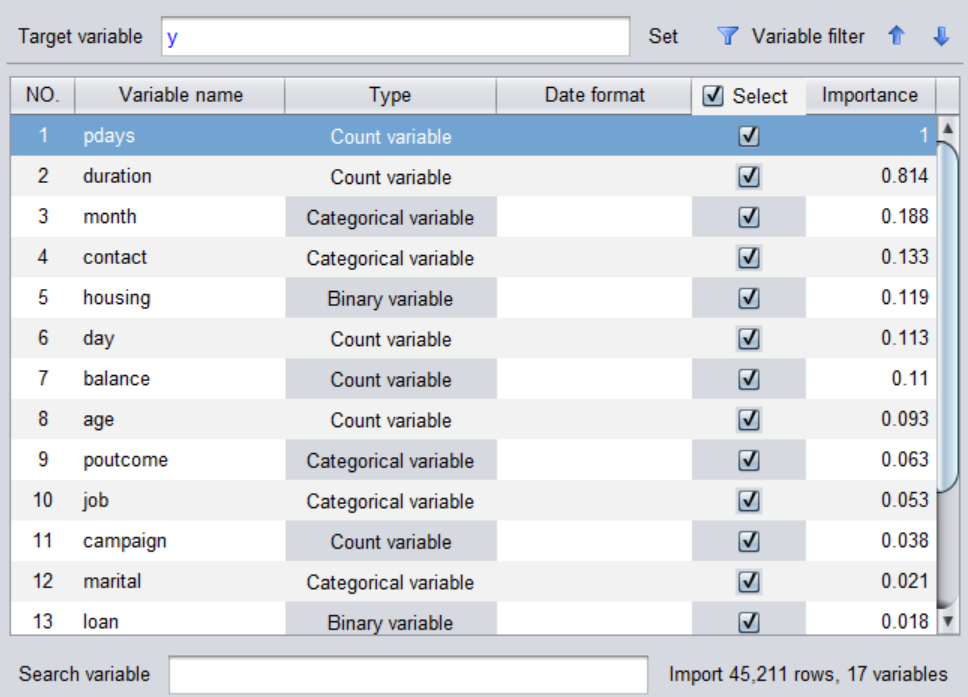
大概几分钟到几十分钟(有时会更短,看数据量)就能完成模型建立。界面会返回每个变量的重要度,重要度越大表示该变量越能影响预测目标。使用该功能可以帮我们做一些业务分析,比如预测目标是销量时,可以找到影响销量的一些重要因素。
模型建好后,系统会写出.pcf 后缀的模型文件,用来做预测。如果还需要保存建模过程,可点击“Save”  按钮,生成.mcf 后缀的建模文件。pcf 模型文件中只有模型没有数据,mcf 文件中含有数据和建模配置信息。
按钮,生成.mcf 后缀的建模文件。pcf 模型文件中只有模型没有数据,mcf 文件中含有数据和建模配置信息。
3. 使用 YModel 预测
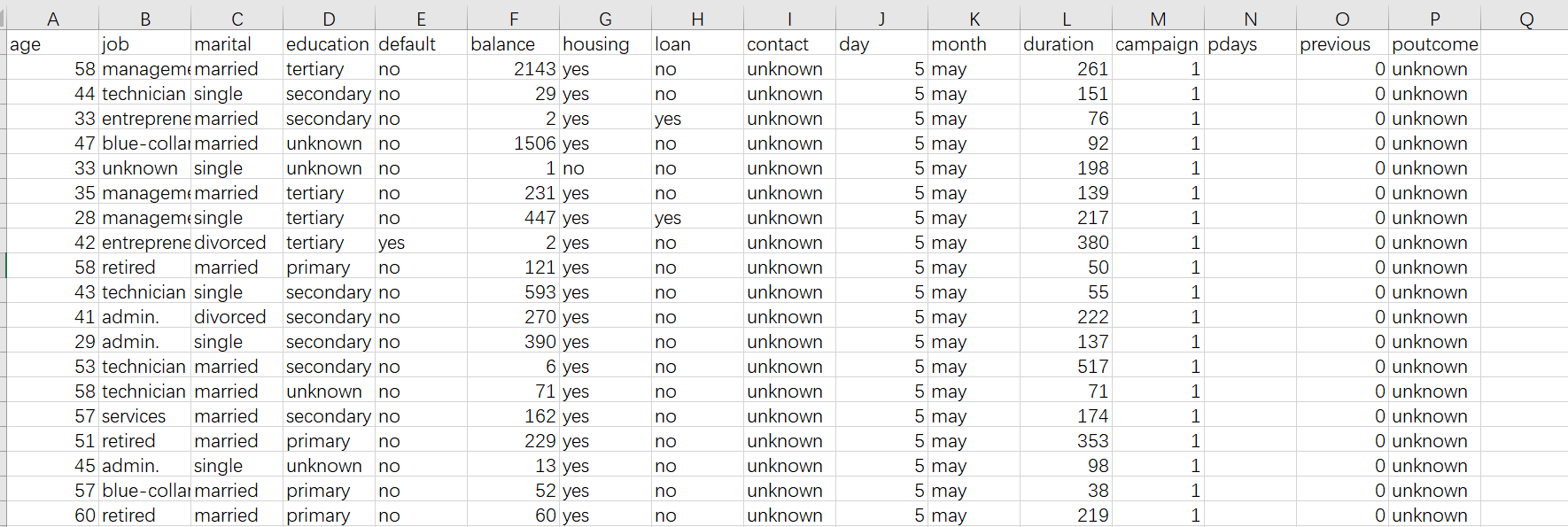
点击 YModel 界面左上方的 Scoring” 按钮,打开步骤 2 生成的 pcf 模型文件,导入要预测的数据集(这些数据还是用 csv 格式,和建模用的变量(csv 中的列)必须一样,但是没有预测目标)进行预测,比如下图两张表,区别就是一个有 y,一个没有 y。
按钮,打开步骤 2 生成的 pcf 模型文件,导入要预测的数据集(这些数据还是用 csv 格式,和建模用的变量(csv 中的列)必须一样,但是没有预测目标)进行预测,比如下图两张表,区别就是一个有 y,一个没有 y。
导入后,点击界面右上方的“Scoring”按钮进行预测,完成即可得下面的界面,最左侧的一列就是预测结果,在本例中百分数表示客户违约的概率,概率越大的客户违约的风险越高。我们可以按超过预测的违约概率超过某个阈值就认为高风险客户(具体用什么阈值,要根据业务经验来定,缺乏经验时也可以先简单粗暴地用 50% 来算)。
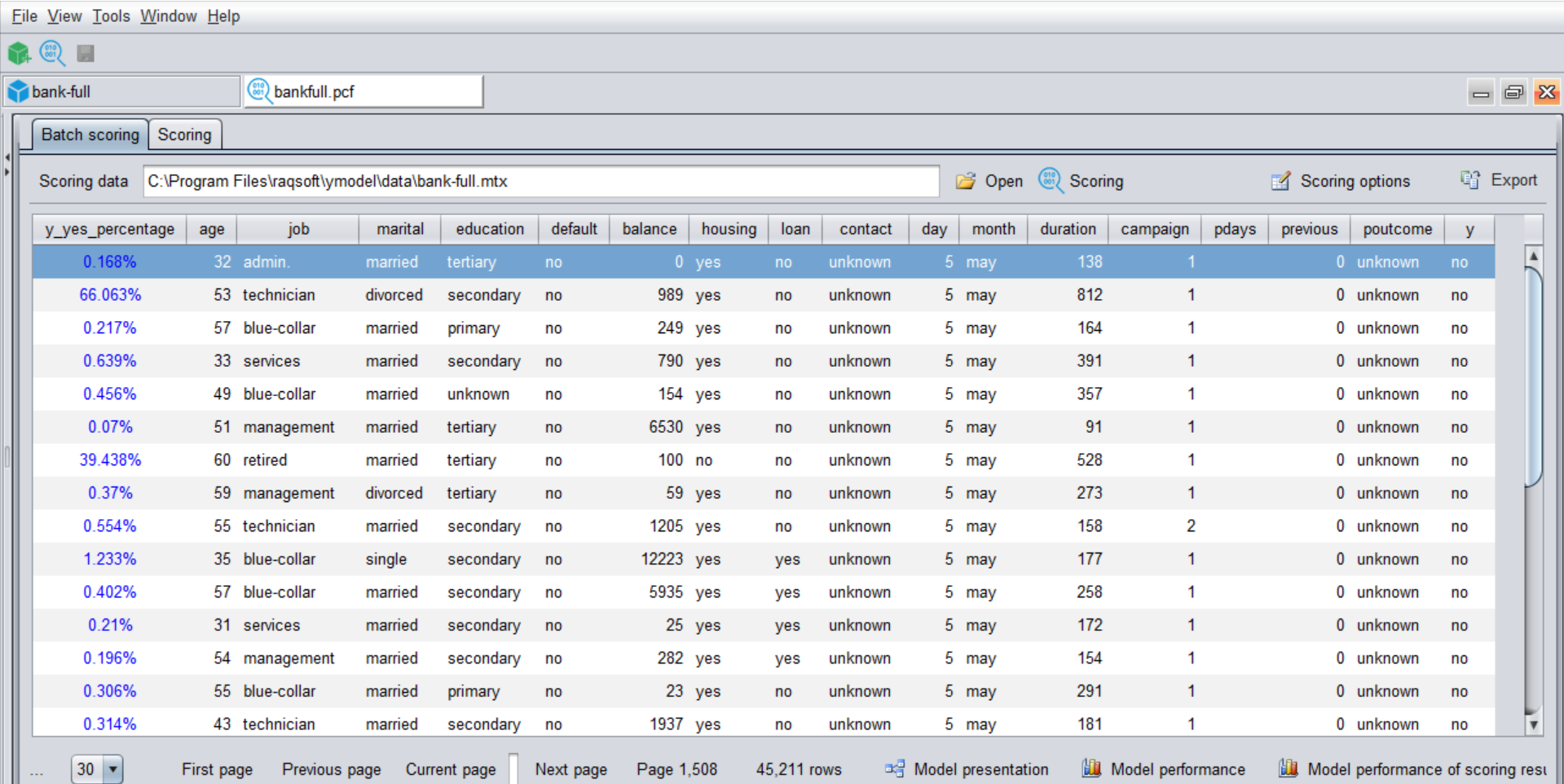
这个结果还可以导出成 csv,xls 等多种格式的结果文件。
到这一步,我们的预测就完成了,整个过程可以说是非常简单。
4. 模型表现
前面说了,预测不可能 100% 准确,但总得有个准确度吧,我们怎么知道呢?
在第 2 步模型建好以后,点击“Model Performance”按钮 ,可以看到关于这个模型的一些信息,称为模型表现,如下图。
,可以看到关于这个模型的一些信息,称为模型表现,如下图。
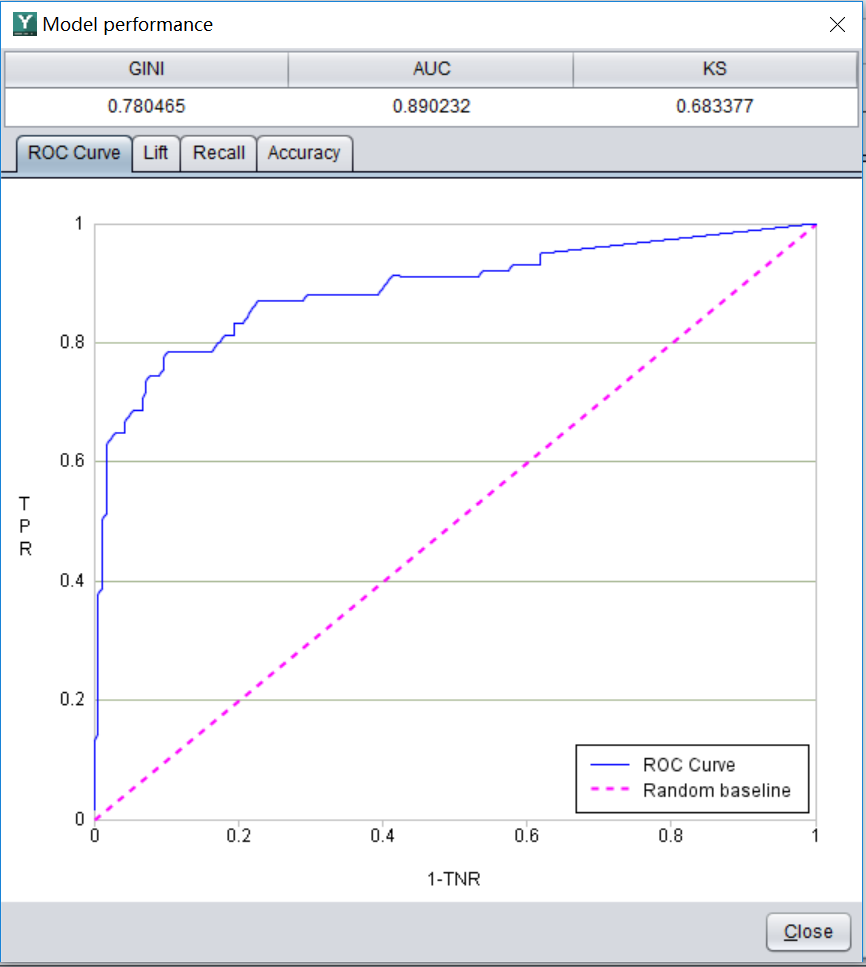
我们通常看这个叫 AUC 的指标,取值范围为(0.5-1),原则上越大越好,表示这个模型越准确。比如这个模型的 AUC 是 0.89,算是不错的模型,用这个模型去做预测的可信度是很好的。不过,这个 0.89 并不是指准确度是 89%(具体的预测准确度和前面说的那个阈值有关,在确定阈值之前是没法算出来的),AUC 的具体含义比较复杂,感兴趣的同学可以去参考数据挖掘的书籍( 这有一个浅显易懂的免费电子书http://www.raqsoft.com.cn/wx/course-data-mining.html )。
如果 AUC 很高,接近于 1,是不是说明这个模型特别好?也不一定,这可能会发生所谓的“过拟合”现象。这时,虽然 AUC 指标非常好,但真正拿来预测时可能准确率反而会非常差。至于为什么发生过滤以及如何识别和避免它,也可以参考上述的书籍。
总结:
最后我们再来总结下使用历史数据做商业预测的流程:
-
将历史数据和待预测的数据都整理成宽表,历史数据中必须要有目标变量,待预测数据则没有。
-
将历史数据导入 YModel,建立模型,生成.pcf 后缀的模型文件
-
打开 pcf 模型文件,导入待预测数据,完成预测,生成结果,然后就可以根据预测出来的结果(比如违约概率)去决定商业行动了。
还有些特殊场景的预测需要专门处理,可以参考


英文版