


如何利用历史数据预测异常罕见现象
在《 怎样利用历史数据做商业预测 》(以下简称前文) 一文中我们介绍了如何使用历史数据进行商业预测的过程。不同的商业需求,还会有些各自的特殊性。例如,在很多业务场景中,存在一种数据不平衡的现象,比如银行贷款违约,违约的人只是很小一部分人;保险欺诈,欺诈者也是个别现象;还有产品质量中不良品的比例、工业生产中非计划停车现象……。这些罕见现象的发生比率很低,但一旦发生就会产生较大的损失,所以要尽量能预测出来并避免。本文将介绍如何来预测这些罕见发生的现象。
1. 准备历史数据
数据准备的过程如前文所述,但是对于这种需要预测罕见现象的场景,就要考虑数据不平衡的问题。我们把历史数据中发生过罕见现象的记录称为阳性样本,数据不平衡就是指阳性样本在总数据中过于稀少。这时,即使总数据量很多也很难建出有效模型。因此,在准备数据时就要尽量多提取阳性样本,具体多少并没有固定要求。一般来讲,问题越复杂,需要的数量就越多,不过即使很简单的问题通常至少也需要几百条阳性样本才可能建出可用模型。反之,也不能只取阳性样本。例如,要建模预测贷款用户的违约情况,要保证违约客户的数据达到一定数量,但也不能全部都是违约客户的数据,正常客户的数据也要采集。
2. 建立模型
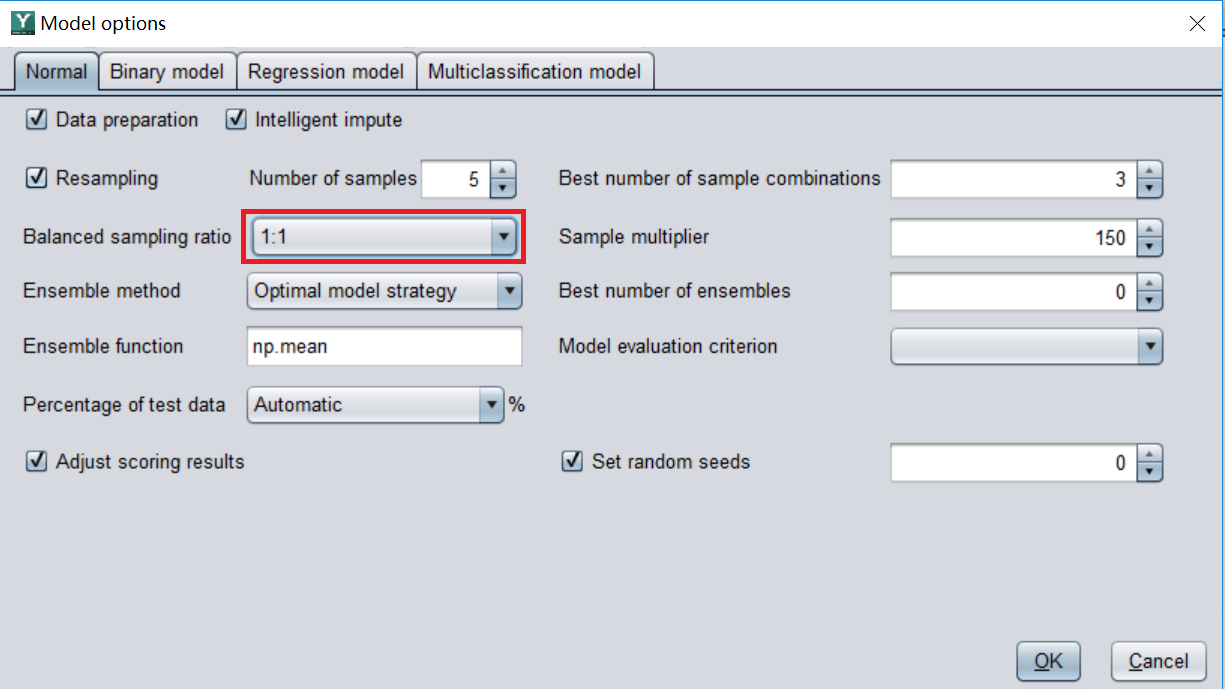
按前文所述即可。对于不平衡的的数据集,YModel 会自动进行抽样来使阳性样本和阴性样本(即正常的样本)的比例达到平衡,使用者不用自己操作。但是我们可以自己修改和设置需要的配平比例,如下图,对于初学者通常建议采取默认的比例就好。
3. 预测
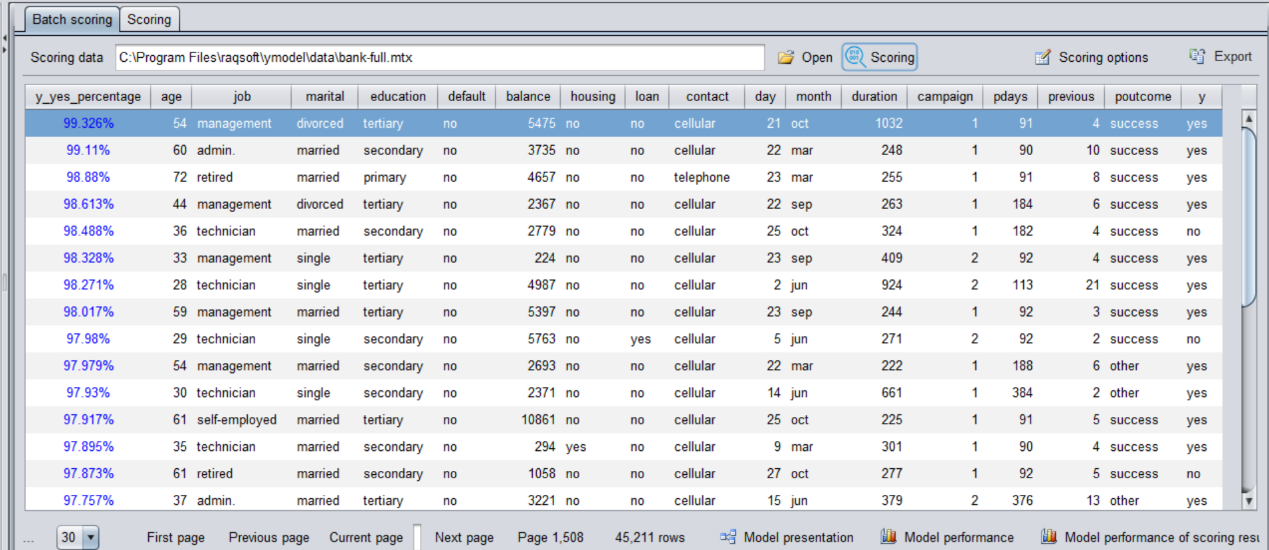
经过前两步的处理后,建立出来的模型就可以实现预测了,同样是按照预测的概率从高到低排序,找前面概率较高的客户或样本来重点排查就可以了。排在前面的样本发生罕见现象的可能性更大。
4.Recall 查全率指标
在数据分布不平衡的场景中,只看预测的准确率是没有意义的,对我们更有意义的是 Recall 查全率。查全率表示在所有的阳性样本,有多少被正确的预测了。举个夸张点的例子,机场识别恐怖分子,在 100 万人里只有 5 个恐怖分子,因为恐怖分子是极少数,如果使用准确率来评估模型的话,那只要把所有人都识别成正常人,其准确率可以达到 99.9995%,但显然没什么意义,一个恐怖分子都没有抓到,也就是说这个模型虽然准确率很高但是查全率为 0/5=0。反之,另一个模型预测出 100 个人为高风险人群,5 个恐怖分子都就包含在这 100 人里,这时候准确率降为 99.9905%(有 95 人预测错误),但查全率为 5/5=1,恐怖分子都能抓到了。这样的模型就是更有意义的。
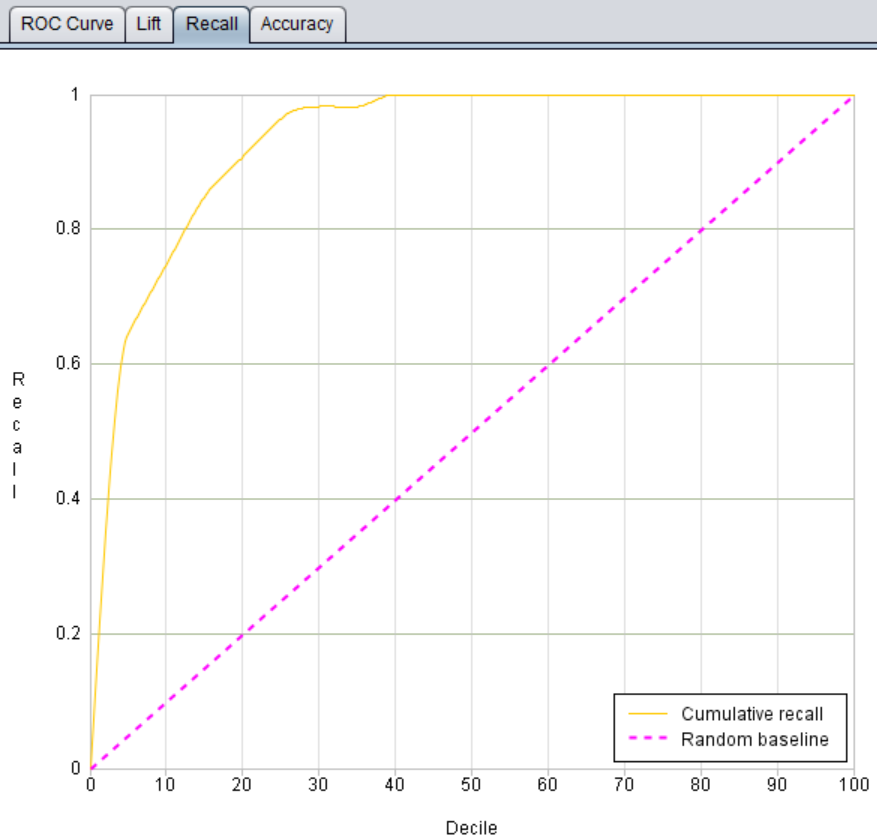
在 YModel 中我们会用 Recall 曲线来判断查全率,如下图,横坐标表示将发生罕见现象的预测概率按照从高到低排序取数,10,20……分别表示概率排名前 10%,20%……的样本,纵坐标表示在各排名阶段对应的查全率值。图中横坐标 10 对应的查全率约为 0.75,表示在预测概率排名前 10% 的数据中,能捕获 75% 的罕见现象,也就是说相比于全部排查,我们用 10% 的工作量就能找到 75% 的罕见(异常)情况。Recall 曲线越靠近左上角表示模型的捕获罕见现象(违约、欺诈、不良品、设备异常……)能力越强。


英文版