


JasperReport 调用 SPL 脚本
【摘要】
集算器提供了 JDBC 驱动,可以很方便与其他报表工具集成使用。本文就 JasperSoft Studio 6.19.1 开发环境为例,介绍 JasperReport 中如何调用 SPL。去乾学院看个究竟:JasperReport 调用 SPL 脚本
集成集算器 JDBC
首先将集算器 JDBC 集成到 JasperReport 设计器中,简单来说就是,将集算器 JDBC 所需的 jar 包及配置文件添加到 JasperReport 的 JDBC 数据源中。需要注意的是,集算器 JDBC 所要求的 JDK 版本不得低于 1.8。
实现思路如下:

1. 创建配置文件
创建集算器 JDBC 必须的配置文件 raqsoftConfig.xml,可以在 [安装目录]\esProc\config 下找到,配置文件的名称不可改变。
在 raqsoftConfig.xml 文件中,配置了集算器主路径、splx 文件寻址路径等各类信息。
2. 加载驱动 jar
集算器 JDBC 类似一个不带物理表的数据库 JDBC 驱动,可以把它简单的看成是一个只有存储过程的数据库。另外,集算器 JDBC 是个完全嵌入式计算引擎,已经在 JDBC 中完成了所有运算,不像数据库那样 JDBC 只是个接口,实际运算在独立的数据库服务器完成。
以下用到的第三方 jar 文件都可以在 [安装目录]\esProc\lib 目录下找到。
集算器 JDBC 需要两个基础 jar 包:
esproc-bin-xxxx.jar //集算器计算引擎及JDBC驱动包,注意:社区版时使用esproc-xxxx.jar
icu4j*.jar //处理国际化
除了以上的必需 jar,还有一些为完成特定功能的 jar 包:
比如数据库作为数据源,那么还需要相应数据库的驱动 jar 包;
要读写 Office 文件,则需要加入 poi*.jar 和 xmlbeans*.jar;
要使用绘制图形功能,则需要加入 SVG 图形处理相关的 jar 包,包括 batik*.jar 和 xml-apis*.jar。
在 JasperSoft Studio 安装目录下新建 SPL-jdbc 目录,将以上所需 jar 包添加到此目录中。除了以上包,还需要将第一步中创建的配置文件 raqsoftConfig.xml 压缩到 config.jar 中,也添加到 SPL-jdbc 目录。
JasperReport 调用 SPL
JasperReport 调用 SPL,其原理就是将集算器 JDBC 作为数据源,然后将类似 SQL 语句的集算器 SPL 语句作为数据集,从而在报表中调用 SPL 语句执行后的结果集。
新建数据源
选择菜单 File->New->Data Adapter,文件名输入 SPLJdbc.jrdax
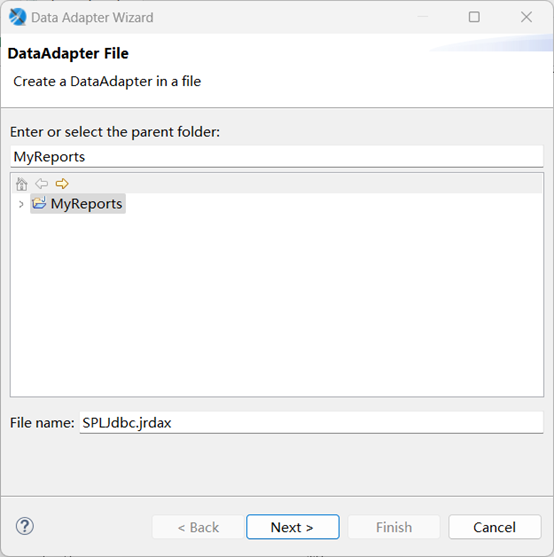
点击 Next 后,选择如下图
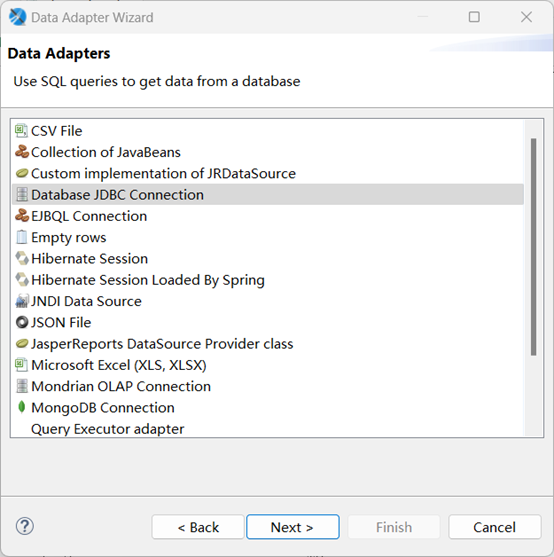
点击 Next 后,输入 Adapter 名称 SPLJdbc,在 Driver Classpath 选项界面中,加入前面创建的 SPL-jdbc 目录中的 jar,如下图
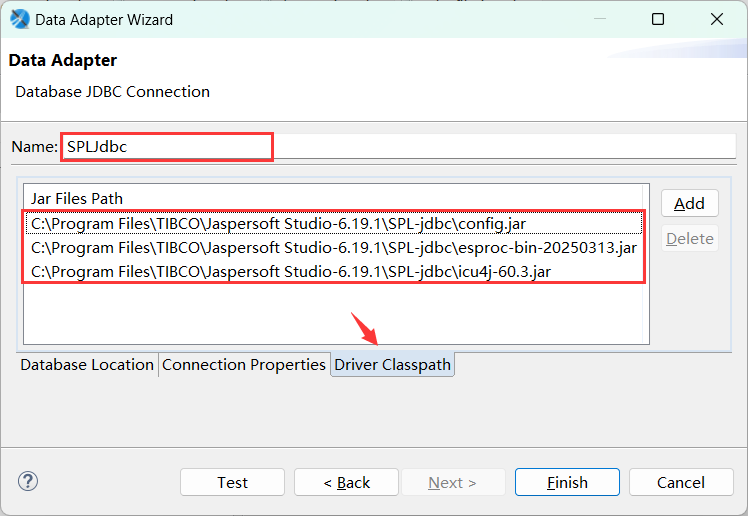
在 Database Location 选项界面中,填写驱动类名:com.esproc.jdbc.InternalDriver,填写 JDBC URL:jdbc:esproc:local://,用户名和密码为空,如下图
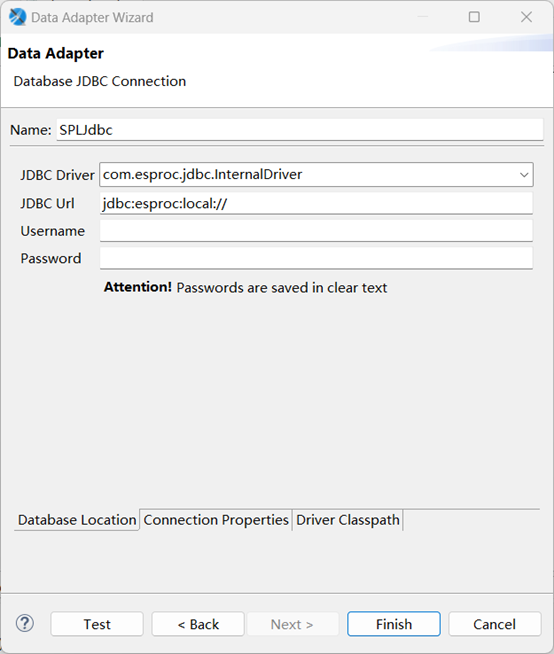
点击 Test 按钮,弹出 Successful 窗口。再点击 Finish 按钮,完成。
制作报表
接下来我们通过新建报表,设置不同的查询语句,了解 JasperReport 执行集算器语句的多种方式。
执行 SPL 语句
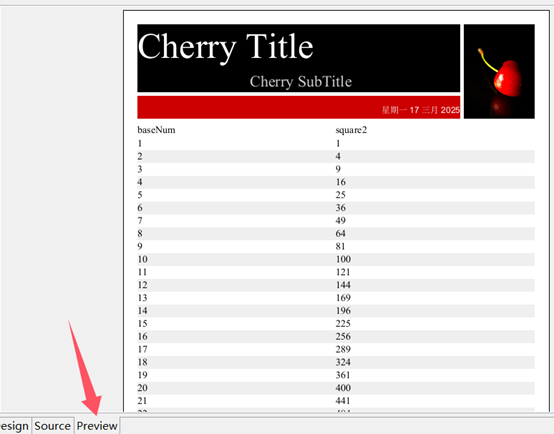
比如创建一个数据表,并添加两个字段 baseNum、square2,分别将 100 以内的自然数及其的平方值组成 100 条记录插入到数据表中,最后将表中的数据作为结果集返回。SPL 语句为:=100.new(~:baseNum,~*~:square2)。
点击菜单 File->New->Jasper Report,选择 Cherry 模板
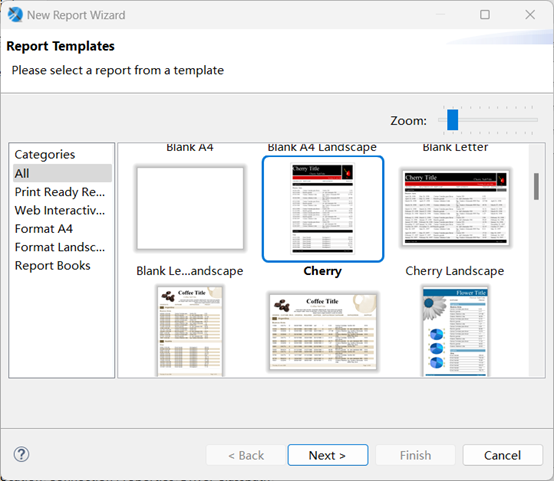
点击 Next,输入文件名 SPL1.jrxml,点击 Next,操作如下图
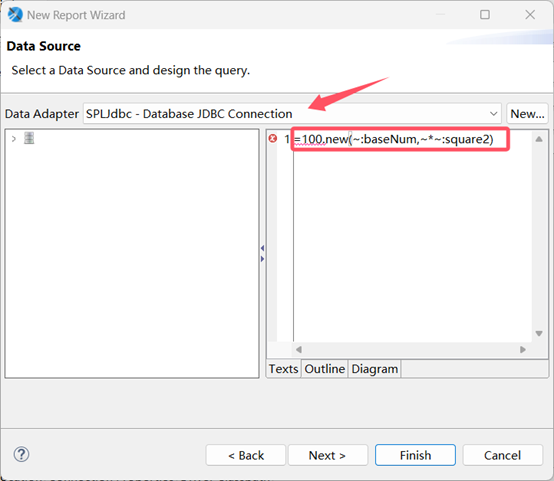
点击 Next,将两个字段都选择到右边,如下图
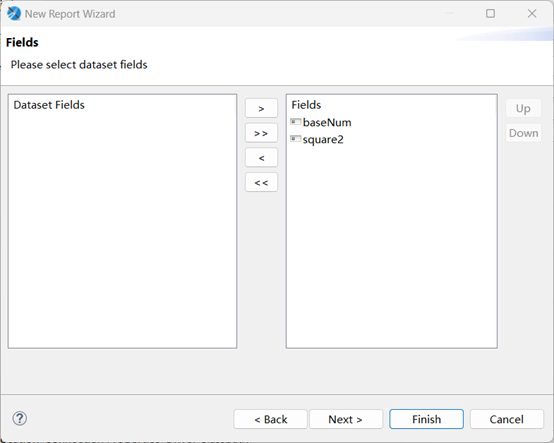
点击 Next,再点击 Next 后,完成新建报表如下图
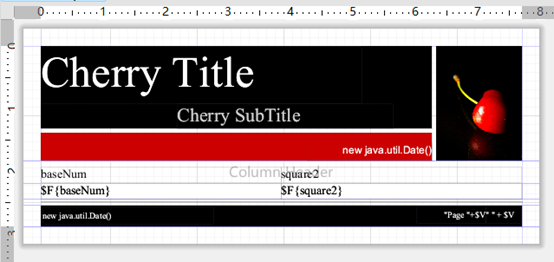
点击 Preview,则可看到报表如下
通过 SPL 访问本地文件
还可以通过 SPL 访问本地多种类型的文件,其中包括 txt、excel、json、csv、ctx 等。访问时可以通过绝对路径查文件位置,也可以通过相对路径查找,使用相对路径时,则是相对于配置文件中的主目录,所以,首先我们来配置下主目录:
在 raqsoftConfig.xml 文件的节点 < esProc></esProc> 中添加以下节点:
<!--集算器主路径,该路径为单一的绝对路径-->
<mainPath>C:\Program Files\TIBCO\Jaspersoft Studio-6.19.1\SPL-jdbc</mainPath>
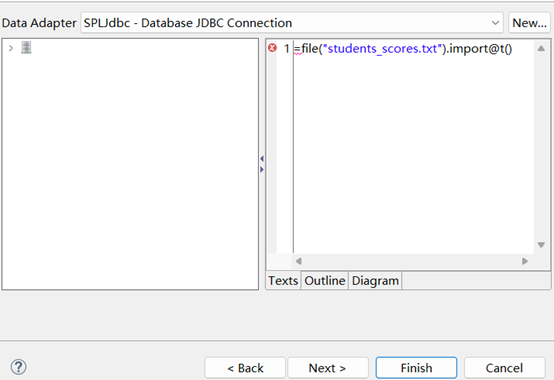
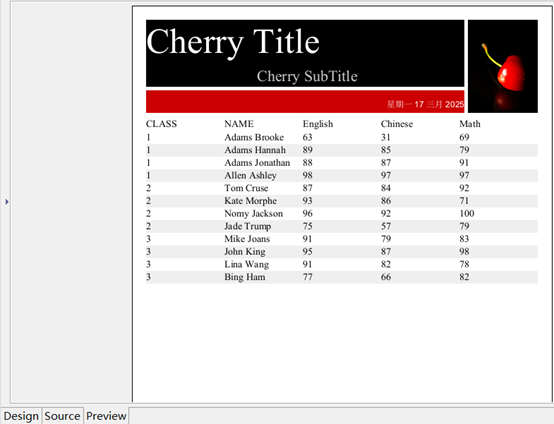
我们把要调用的文件 students_scores.txt 放到主目录下面,其中创建报表的操作与上例完全相同,查询语句:=file(“students_scores.txt”).import@t()
报表预览如下
对于这种简单运算,还可以使用简单 SQL 语法:$()select * from students_scores.txt
其中 $() 表示访问本地文件系统,两种写法的结果集相同。
带参数的 SPL 语句
参数是 SQL 语句的一个重要组成部分,同样,SPL 语句也支持参数的使用,例如,像上例中,要查询 students_scores.txt 文件中的数据,但是要求只查询数学成绩在 75 到 95 之间的记录,并根据数学成绩升序排序:
打开上例,增加两个参数 Parameter1,Parameter2,并设置参数的数据类型为 Integer,缺省值分别为 75,95。拖拽参数到查询语句的指定位置。查询语句:$()select * from students_scores.txt where Math>$P{Parameter1} and Math<$P{Parameter2} order by Math
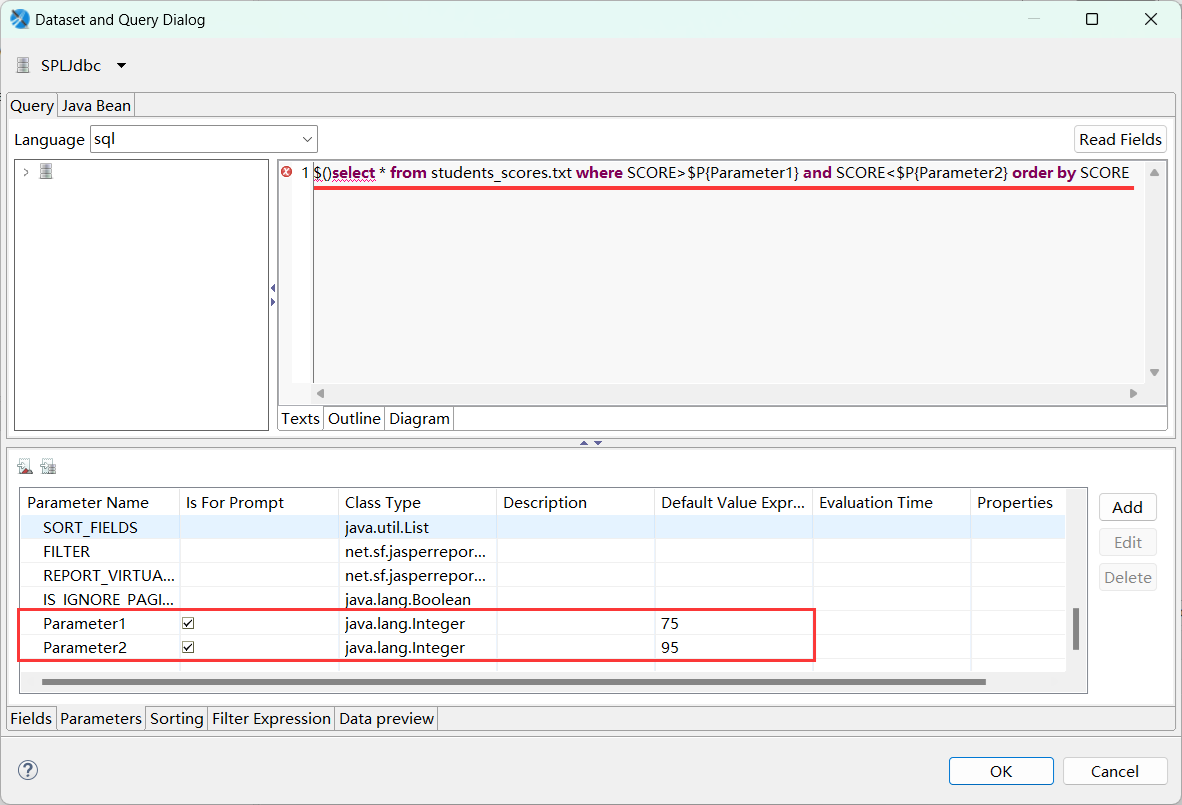
预览报表,输入参数 (或用缺省参数)
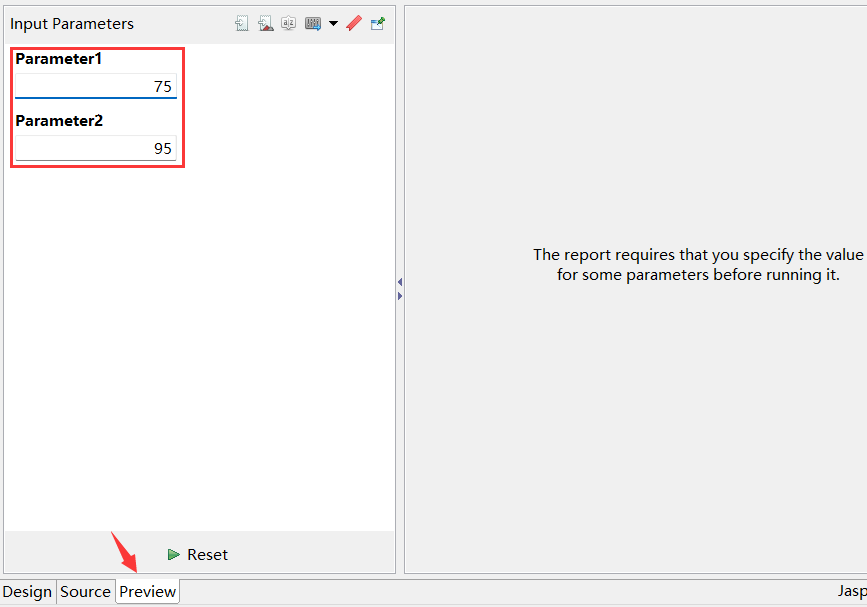
结果如下:
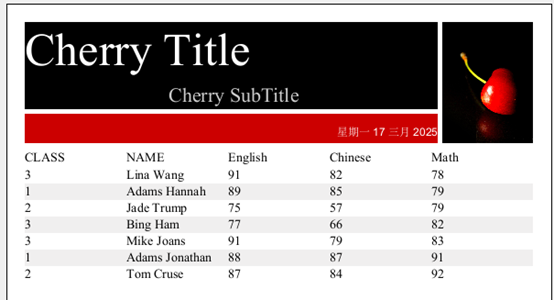
有数据源的 SPL 语句
集算器 JDBC 既然是个数据计算引擎,那么数据来源的重要途径之一就是数据库了,JasperReport 中如何来调用带数据源的 SPL 语句呢?往下看:
JasperReport 调用带数据源的 SPL 语句之前,需要先在应用项目中添加对应的数据库驱动,然后在配置文件 raqsoftConfig.xml 中配置数据源信息,例如:调用的 SPL 语句中使用的数据源名称为 demo,数据库类型为 HSQL,那么配置如下:
首先,将 HSQL 的数据库驱动 hsqldb-2.7.3-jdk8.jar 添加到 SPL-jdbc 目录中,打开 SPLJdbc.jrdax 加上这个 jar。
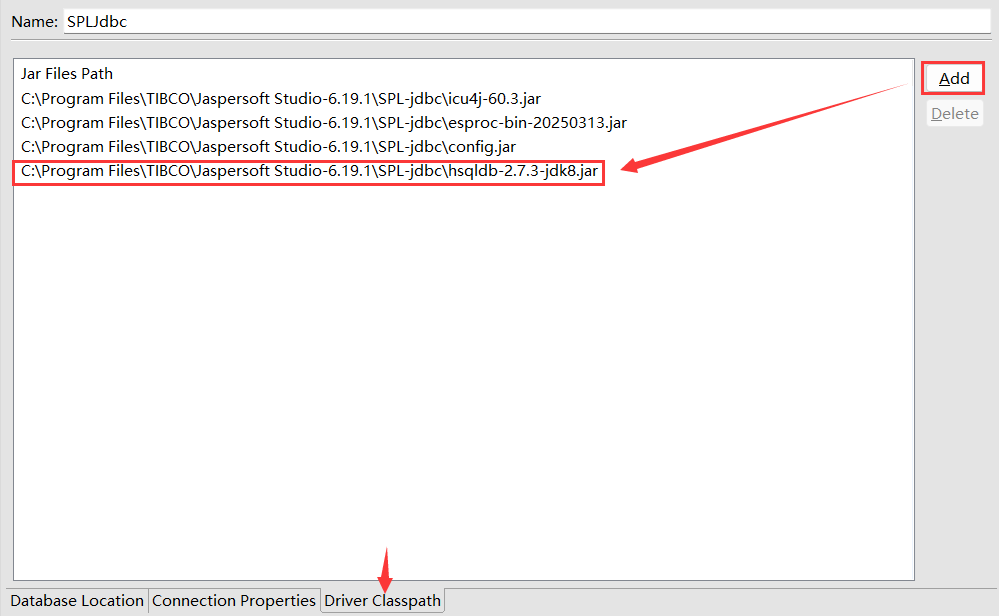
其次,在 raqsoftConfig.xml 的 < Runtime></Runtime> 节点中配置数据源信息:
<DBList>
<DB name="demo"> <!--数据源名称-->
<property name="url" value="jdbc:hsqldb:hsql://127.0.0.1/demo" /> <!-- url连接-->
<property name="driver" value="org.hsqldb.jdbcDriver" /> <!--数据库驱动-->
<property name="type" value="13" /> <!--数据库类型-->
<property name="user" value="sa" /> <!--用户名-->
<property name="password" /> <!--密码-->
<property name="batchSize" value="1000" />
<property name="autoConnect" value="true" /><!--是否自动连接,如果设定为true,则可以直接以$开头的SQL语句来访问数据库,如果为false,则不会自动连接,使用前必须用connect(db)语句创建数据库连接 -->
<property name="useSchema" value="false" />
<property name="addTilde" value="false" />
<property name="dbCharset" value="UTF-8" />
<property name="clientCharset" value="UTF-8" />
<property name="needTransContent" value="false" />
<property name="needTransSentence" value="false" />
<property name="caseSentence" value="false" />
</DB>
</DBList>
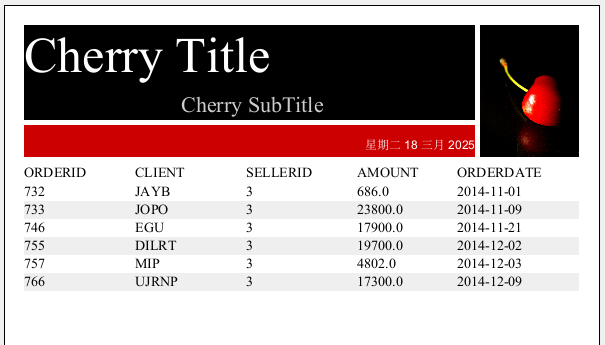
现在我们通过 SPL 从 demo 数据源中查询 SALES 表,过滤出 SELLERID 为 3 的员工,在 2014 年 11 月 01 号到 2014 年 12 月 12 号期间的所有订单信息:
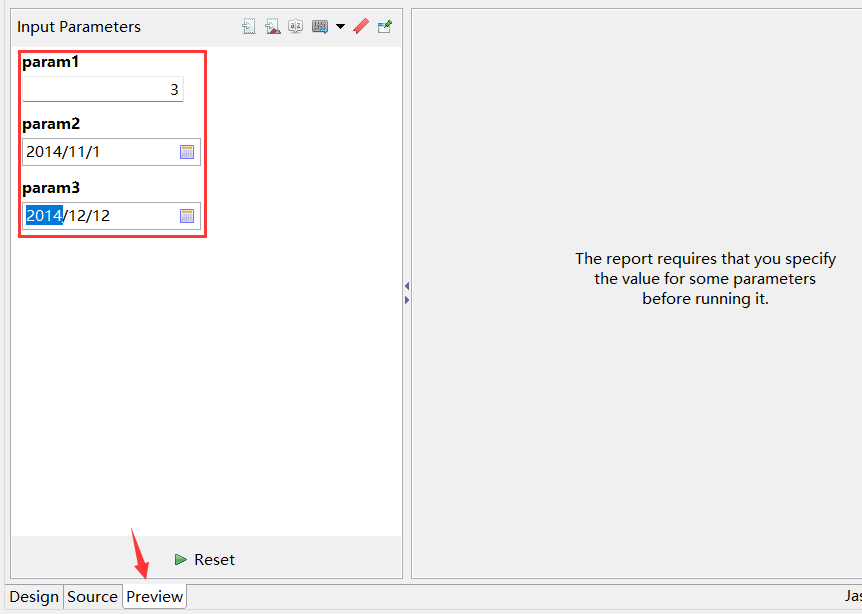
创建报表的操作可参考上面的例子,创建三个参数:param1、param2 和 param3。拖拽参数到查询语句的指定位置。查询语句:$(demo)select * from SALES where SELLERID = $P{param1} and ORDERDATE>$P{param2} and ORDERDATE<$P{param3}。
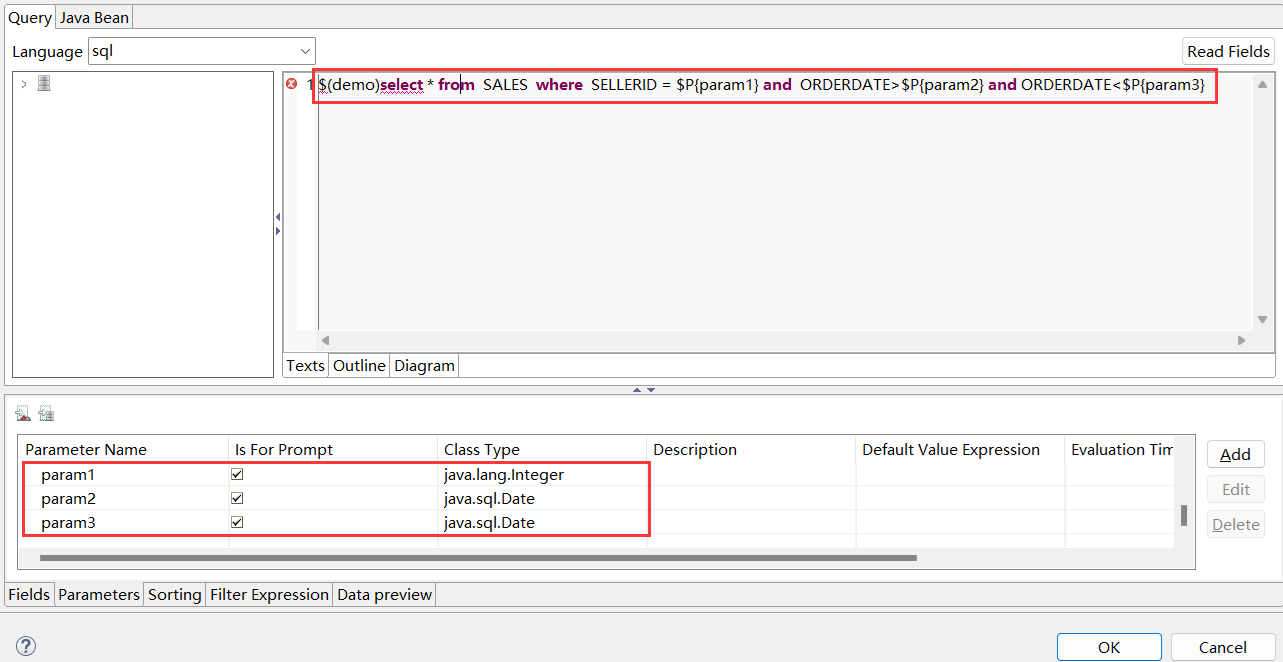
预览报表,输入参数:
即可看到查询后结果:
执行 SPL 脚本
JasperReport 集成集算器 JDBC 后,除了可以直接执行单句的 SPL 语句,还可以调用更复杂的 SPL 脚本(后缀为 splx 的文件)。
比如下面的 splx 文件:
| A | B | C | |
|---|---|---|---|
| 1 | =demo.query(“select NAME as CITY, STATEID as STATE from CITIES”) | [] | |
| 2 | for A1 | =demo.query(“select * from STATES where STATEID=?”,A2.STATE) | |
| 3 | if left(B2.ABBR,1)==arg1 | >A2.STATE=B2.NAME | |
| 4 | >B1=B1|A2 | ||
| 5 | return B1 |
SPL 脚本思路:
循环遍历 CITIES 表记录,通过 CITIES. STATES 过滤 STATES 表,若 STATES. ABBR 首字母为参数 arg1,则将 STATES 表中的 NAME 值赋给 CITIES.STATE,并将 CITIES 表中的这条记录拼接到 B1 格中,最终返回 B1 格的结果集。
在这个网格文件中,需要从数据源 demo 中获取数据,同时使用了参数 arg1:

数据源配置方法可以参考上面的示例,网格文件保存为 city.splx,splx 文件可以存放在 raqsoftConfig.xml 中配置的主目录下,当 splx 文件比较多的时候,为了便于统一维护和管理,我们还可以将 splx 文件放到 splx 寻址路径中,寻址路径的配置方式如下:
在 raqsoftConfig.xml 文件的 < esProc> </esProc> 节点中,添加以下内容:
<splPathList>
<splPath>C:\Program Files\TIBCO\Jaspersoft Studio-6.19.1\SPL-jdbc\splx</splPath>
</splPathList>
<!--配置splx文件寻址路径,可以设置多个路径,以“;”隔开。 -->
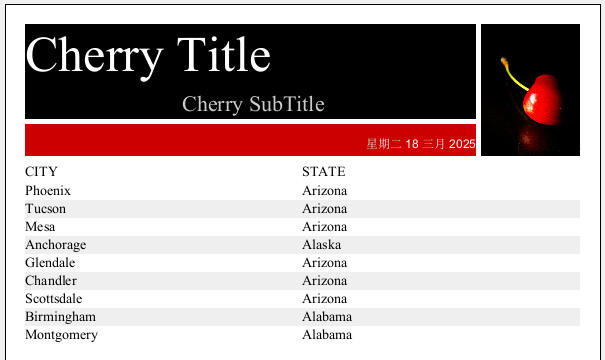
创建报表的操作可参考上面的例子,创建 1 个参数并设置参数的数据类型为 String。拖拽参数到查询语句的指定位置。查询语句:call city($P{Parameter1})。
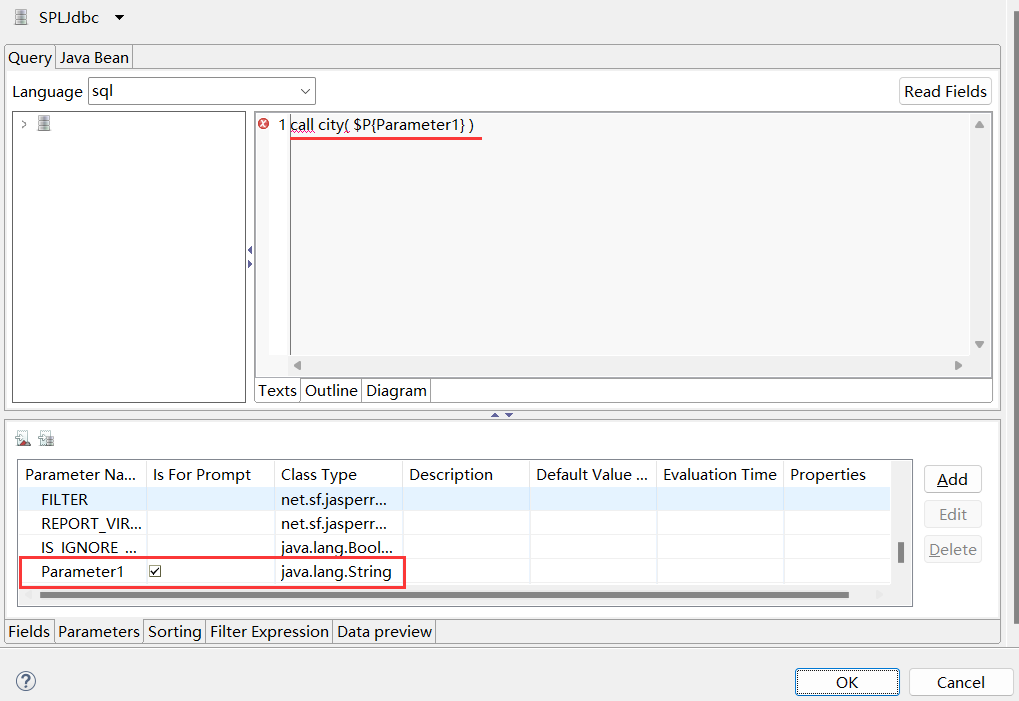
预览报表,输入参数
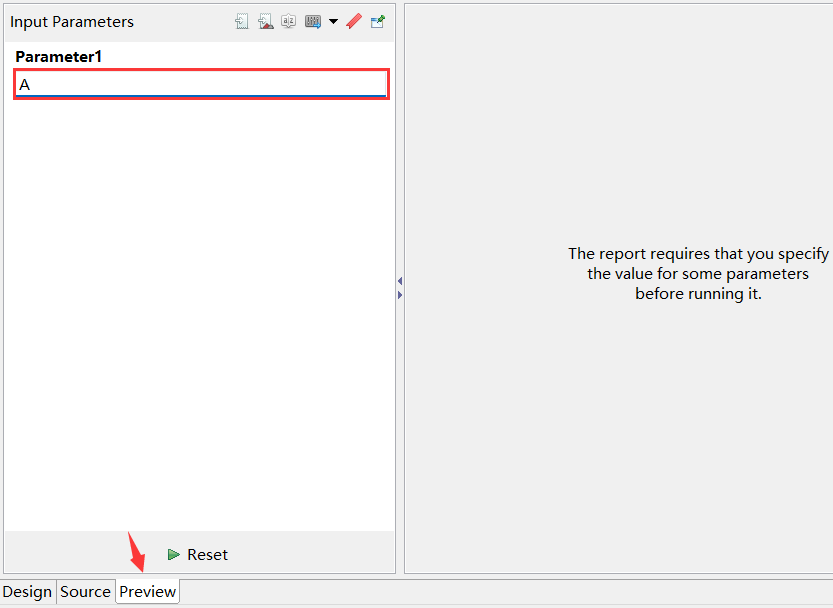
即可看到查询后结果如下:
其他程序调用 SPL 用法详见:

