


HTTP 调用 SPL
【摘要】
集算器产品中提供了 HTTP 服务,用户可以通过 url 的方式读取 SPL 的结果集
HTTP 调用 SPL
实现思路如下:

部署服务
部署服务器操作可分为两步,首先是配置服务器参数,其次是启动服务器。
服务器配置
在集算器安装目录的 esProc\bin 路径下,找到 esprocs.exe 文件,可以直接运行它来启动或配置服务器,运行后,打开窗口如下:
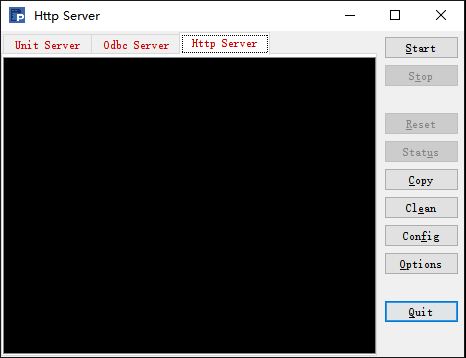
在 esprocs.exe 执行时,窗口中会显示加载初始设定的信息,这些设定实际上是由配置文件 raqsoftConfig.xml 决定的。在右侧的菜单栏中点击 Options,可以配置服务器的相关信息,点击后弹出服务器配置窗口如下:
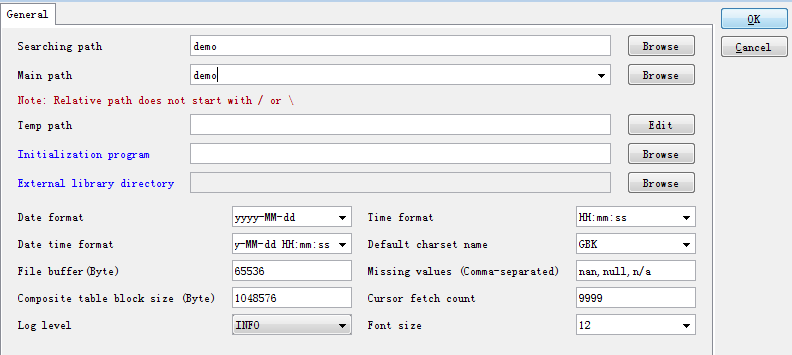
在该界面中,可以配置主路径、寻址路径、日期时间格式、默认字符编码、日志等级、文件缓存区字节数等信息。
下面我们继续来了解服务器的配置,选择 Http Server ,在右侧的菜单栏中点击 Config,可以打开集算器 HTTP 端口设置窗口如下:
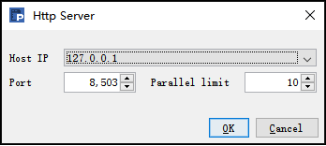
在该界面中,可配置服务器的 IP 地址、端口号和最大并行数,服务器设定完成后,点击 OK,此时可以自动设定对应的配置文件 HttpServer.xml,如下:
<?xml version="1.0" encoding="UTF-8"?>
<!--Note: In order to avoid problems while the program is running, the charset of HttpServer.xml must be UTF-8 -->
<Server Version="1" host="127.0.0.1" port="8503" parallelNum="10"/>
运行服务器
服务配置完成后,在 Http Server 窗口点击 Start 即可开始运行服务器,如下:
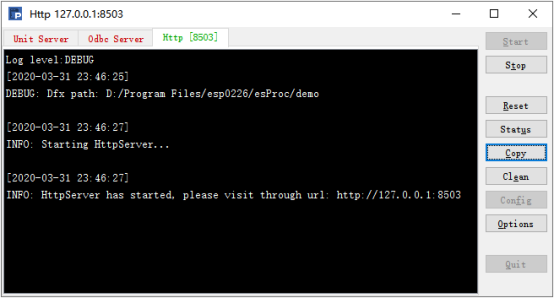
需要停止服务可以点击 Stop,服务器停止后可以点击 Quit 退出。如果点击 Reset,服务将初始化重新启动,清除所有的全局变量以及内存区。
在 Linux 系统中,可以运行 ServerConsole.sh 来启动服务器类,打开的服务器运行窗口和在 Windows 下是相同的。
此外,还可以在执行命令时添加 -h 参数,非图形启动服务器,此时可直接执行命令:
./ServerConsole.sh -h
HTTP 调用
HTTP 调用 SPL,原理上就是通过 url 读取 splx 文件的结果集,被调用的 splx 脚本中,结果要求用 return 语句返回,下面来看下具体是怎样实现的:
调用单个 splx
比如通过 HTTP 服务读取 HSQL 数据库中的员工表,首先需要在 raqsoftConfig.xml 的 < Runtime ></ Runtime > 节点中配置数据源信息:
<DB name="HSQLDB"> <!-- 数据源名称-->
<!-- url连接-->
<property name="url" value="jdbc:hsqldb:hsql://127.0.0.1/demo" />
<!--数据库驱动-->
<property name="driver" value="org.hsqldb.jdbcDriver" />
<property name="type" value="13" /> <!--数据库类型-->
<property name="user" value="sa" /> <!-- 用户名称 -->
<property name="password" value="123456"/> <!-- 密码 -->
<property name="batchSize" value="1000" />
<property name="autoConnect" value="true" /> <!--是否自动连接-->
<property name="useSchema" value="false" />
<property name="addTilde" value="false" />
<property name="dbCharset" value="UTF-8" />
<property name="clientCharset" value="UTF-8" />
<property name="needTransContent" value="false" />
<property name="needTransSentence" value="false" />
<property name="caseSentence" value="false" />
</DB>
splx 脚本内容如下:
A |
|
1 |
=connect("HSQLDB") |
2 |
=A1.query("select * from employee") |
3 |
=A1.close() |
4 |
return A2 |
splx 文件命名为emp.splx并保存在主目录下,HTTP 调用时 URL 写法为:
http://127.0.0.1:8503/emp.splx
其中 127.0.0.1:8503 为前面服务器中配置的 IP 及端口号,后面连接带扩展名的 splx 名称。
如果 splx 文件保存在主目录下的子目录中,调用时加上子目录就可以了 (下同),比如保存在 subdir1 中,则 URL 写法为:
http://127.0.0.1:8503/subdir1/emp.splx
浏览器访问 URL 结果如下:
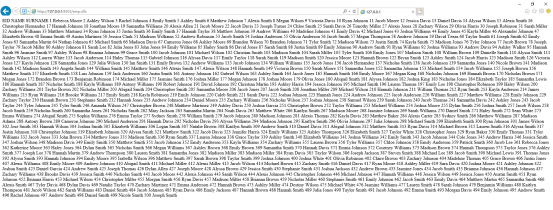
通过浏览器访问 URL 时,返回结果显示为无格式的文本,所以浏览器常用作调试使用。日常业务中,用户可在自己的程序中调用 URL,结果集可自由使用。下面我们以 java 程序为例,访问上面的 URL:
java 代码如下:
URL url = new URL("http://127.0.0.1:8503/emp.splx"); //传入URL串
HttpURLConnection urlcon = (HttpURLConnection)url.openConnection();
urlcon.connect(); //获取连接
InputStream is = urlcon.getInputStream();
BufferedReader buffer = new BufferedReader(new InputStreamReader(is));
StringBuffer bs = new StringBuffer();
String l = null;
while((l=buffer.readLine())!=null){
bs.append(l).append("\n");
}
System.out.println(bs.toString());
结果如下:
调用带参数的 splx
HTTP 还可以调用带有参数的 splx 文件,比如从数据源中查询 SALES 表,过滤出 SELLERID 为 3 的员工,在 2014 年 11 月 11 号到 2014 年 12 月 12 号期间的所有订单信息。
splx 脚本内容如下:
A |
|
1 |
=connect("HSQLDB") |
2 |
=A1.query("select * from SALES where SELLERID = ? and ORDERDATE>? and ORDERDATE<?",arg1,arg2,arg3) |
3 |
=A1.close() |
4 |
return A2 |
网格参数:
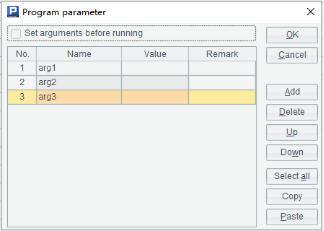
splx 文件命名为 sales.splx 并保存在主目录下,此时,HTTP 调用时 URL 写法为:
http://127.0.0.1:8503/sales.splx(3,2014-11-11,2014-12-12)
其中,splx 后括号中的内容为各个参数所对应的值,多个参数值之间用逗号分隔。
调用两个 splx
使用 HTTP 调用 splx 时,如果返回的结果集格式不理想,还可以通过另一个 splx 文件格式化当前的结果集,此时可同时调用两个 splx。
该用法中 URL 调用时格式为
http://IP:port/splx1.splx(...)splx2.splx
其中 splx1.splx 被 splx2.splx 引用,要求 splx1 返回结果必须为单结果集,splx2 中必须有一个参数,且参数值为 splx1 的返回值。
比如,在 splx1 中查询本地数据文件 Sales.txt,统计所有的 STATE 字段值:
p1.splx脚本内容如下:
A |
|
1 |
$()select * from D:\Sales.txt |
2 |
=A1.(STATE) |
3 |
return A2 |
缺省返回由 STATE 字段值组成的序列,但是用户期望的效果是以逗号作为分隔符以字符串的形式返回,此时就可以使用 p2.splx 对 p1.splx 的结果进行格式处理:
p2.splx脚本内容如下:
A |
|
1 |
=arg1.concat@c() |
2 |
return A1 |
网格参数:
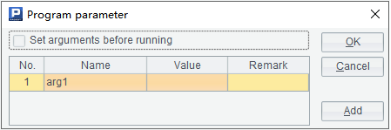
HTTP 调用时,URL 写法:
http://127.0.0.1:8503/p1.splx()p2.splx()
SAP 风格
集算器中提供了类似 SAP 的 restful 风格的用法,首先,必须在 httpServer.xml 的 sapPath 属性中配置 splx 相对于主目录的路径,可以是多层目录结构,多个路径间用逗号隔开,比如:
<?xml version="1.0" encoding="UTF-8"?>
<Server Version="1" host="127.0.0.1" port="8503" parallelNum="10"sapPath="/sf,/sr/pm"/>
该 xml 中,sapPath 配置了两个相对路径,分别表示 [主目录]/sf、[主目录]/sr/pm。
该风格调用无参数的 splx 时,URL 格式为:
http://IP:port/sapPath/splxName
splx 带参数时,URL 格式为:
http://IP:port/sapPath/splxName/arg1[value1]/arg2[value2]/...
其中,sapPath 表示 httpServer.xml 中 sapPath 属性中设置过的路径;
splxName 表示 splx 名称,调用时不带扩展名;
arg1[value1]/arg2[value2]/… 表示 splx 中的参数名称及参数值,要求参数名称必须为纯字母组成的字符串,参数值必须为首字符为数字的字符串,调用时参数名称与参数值拼接成一个字符串使用,多个参数之间用“/”隔开。
示例一:查询本地数据文件,gy.splx脚本内容如下:
A |
|
1 |
$()select * from Geography.txt |
2 |
return A1 |
http://127.0.0.1:8503/sf/gy
其中 /sf 表示 splx 文件相对于主目录的位置,gy 则表示调用的 splx 为 gy.splx。
示例二:带参数的 splx 文件,gypb.splx脚本内容如下:
A |
|
1 |
$()select * from Geography.txt where ID>? and Parent=?;id,parent |
2 |
return A1 |
网格参数:
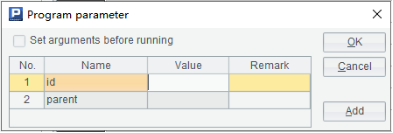
该 splx 中用到了两个参数,参数名称分别为 id、parent,splx 位于 [主目录]/sr/pm 下,调用时 URL 写法如下:
http://127.0.0.1:8503/sr/pm/gypb/id3/parent15
其中,/sr/pm 表示 splx 相对于主目录的位置,gypb 表示调用的 splx 为 gypb.splx,id3/parent15 表示参数 id 的值为 3,参数 parent 的值为 15。
IPV6 协议时的用法
服务器中配置的 IP 地址支持 IPV6 协议,使用 IPV6 协议时,要求的 JDK 版本最低为 1.8,HTTP 调用时 URL 写法也略有不同,需要在 IP 地址外加上“[]”。
例如服务器中配置:
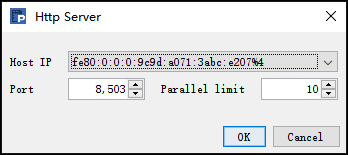
此时访问 splx 时 URL 写法为:
http://[fe80::9c9d:a071:3abc:e207]:8503/localData.splx
需要注意的是,把 IP 地址写入 URL 时,"%“为特殊符号,要用指定字符”%25" 来代替 ,由于 IPV6 地址末尾的 % 及其后内容是非必要的字符,所以也可以直接去掉不写。
接收 POST 方式传送的参数
以上例子中都是用 GET 方式传送的 splx 参数 (参数直接写在 url 中),有时会造成 url 太长而无法访问,此时就需要用 POST 方式来传送参数。SPL 中允许接收一个 POST 参数,参数名称固定为 argpost, 如下图所示的 p1.splx,添加一个网格参数 argpost:
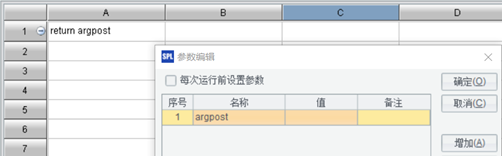
假如用浏览器中的 form 来传送 POST 参数:
<form method="post" action="http://127.0.0.1:8503/p1.splx">
<input type=hidden name=arg1 value="value1">
<input type=hidden name=arg2 value="value2">
<input type=submit value="submit">
</form>
提交以后,浏览器显示 splx 中接收到的 argpost 的值为:
arg1=value1&arg2=value2
返回特殊格式的内容
前面例子中讲的 splx 默认都是返回字符串格式的内容,我们也可以指定 splx 返回特殊格式的内容。下面以返回图片内容为例说明,pic.splx 脚本如下:
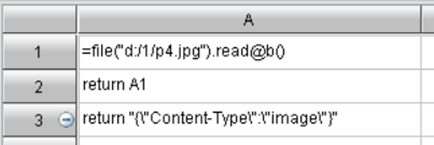
在 splx 中指定两个返回值,第一个是要返回的内容,此例中是从图片文件中读出来的字节数组,实际业务中可能是通过 SPL 的绘图函数画出来的统计图等。第二个返回值是一个 JSON 串,其中的 kv 键值对表示要放在 responseHeader 中的属性。此例中的 Content-Type:image 指明返回的内容为图片格式。如果是其它格式,只要指明 Content-Type 的相对应值就行了,如 application/excel、application/pdf、application/json 等;
特别地,如果要访问 SPL 主目录及其子目录中的图片文件,也可以直接用 url 访问,如要访问主目录下的子目录 dir1 中的 pic.jpg:
http://ip:8503/dir1/pic.jpg
以上就是 HTTP 调用 SPL 的全部用法了,想要更深入的学习 SPL 的小伙伴儿还可以去官网上的在线教程中查看。
其他程序调用 SPL 用法详见:
【Java 如何调用 SPL 脚本】
【Java 如何远程调用 SPL 脚本】
【BIRT 调用 SPL 脚本】
【C# 如何调用 SPL 脚本】
【JasperReport 调用 SPL 脚本】


英文版