


结构化文本文件上的 SQL 式运算
结构化文本也就是行式文本文件,是很常见的文件格式,比如TXT、CSV。在Java中可以硬编码处理,但比较繁琐。还可以使用Commons CSV、OpenCSV、SuperCSV等开源包来实现解析,但运算还经常需要导入数据库才行,这很不方便。SPL可以很方便地实现结构化文本的计算,并可以轻松集成到Java应用中。
1. 读取
结构化文本文件通常每行对应一条记录,各行有相同的列,相当于数据库中的一张数据表。
SPL用file函数打开文本文件,并用import函数将文件读成序表就可以进一步计算了。下面是一些读取例子:
1、txt格式,tab键(\t)分隔,有标题
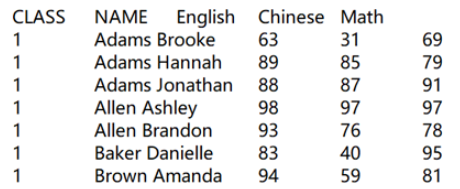
=file("scores.txt").import@t()
file函数的参数可以是文件的绝对路径,也可以是相对路径(相对于SPL配置文件中的mainPath),import函数选项@t表示有标题行,默认分隔符为tab键(\t)。
2、CSV格式、逗号分隔、无标题
=file("d:/order/orders.txt").import@c()
选项@c表示是逗号分隔的CSV文件,没有选项@t表示无标题行。无标题的文件读出来没有列名,就用#1、#2等序号方式来引用列。
3、txt格式、竖线分隔、有标题,使用了utf-8字符集

=file("d:/txt/employee.txt":"utf-8").import@t(;,"|")
在file函数上可以增加字符集参数,字符集不对时,可能会读出乱码。如果没写字符集,则会使用操作系统默认的。import()选项@t表示有标题行,参数"|"表示用竖线分隔。
更多读取介绍请参阅《SPL:结构化文本文件读取》
2. 运算
读入的数据就是内存中的序表,可以做任意的运算。比如过滤、聚合、分组汇总、排序、关联、去重、计算列等,下面举几种运算例子。
比如有学生成绩表Students_scores.txt数据如下:
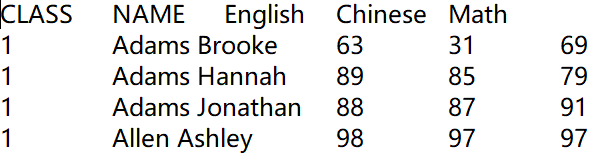
A |
说明 |
|
1 |
=file("Students_scores.txt").import@t() |
数据读成序表,@t表示第1行是标题行 |
2 |
=A1.select(CLASS==10) |
筛选出10班的学生成绩 |
3 |
=A1.groups(CLASS;min(English),max(Chinese),sum(Math)) |
计算各班的英语最低分、语文最高分、数学总分 |
4 |
=A1.sort(CLASS,-Math) |
按照班号升序、数学降序的顺序排列 |
更多运算介绍请参阅《SPL:常规 SQL 式运算》
3. 向Java返回结果
SPL可以用JDBC方式被Java调用,例如执行SPL脚本的代码如下:
Class.forName("com.esproc.jdbc.InternalDriver");
Connection con = DriverManager.getConnection("jdbc:esproc:local://");
Statement st = con.createStatement ();
ResultSet rs = st.executeQuery("=file(\"Students_scores.txt\").import@t().select(CLASS==10)");
更深入用法可参考《Java 如何调用 SPL 脚本》
4. 使用SQL
借助SPL,还可以直接对文本文件使用SQL,如:
A |
|
1 |
$select * from E:/txt/Students_scores.txt where CLASS=10 |
2 |
$select min(English),max(Chinese),sum(Math) from E:/txt/Students_scores.txt |
3 |
$select * from E:/txt/students_scores.txt order by CLASS, Math desc |
SPL会根据文件扩展名决定分隔符,使用SQL时要求文件必须要有标题。
在JAVA中也可以直接用JDBC执行上述SQL语句返回查询结果。
ResultSet rs = st.executeQuery("select * from E:/txt/Students_scores.txt where CLASS=10");
更多信息可参考《在文件上使用 SQL 查询的示例》
5. 大文本
SPL还可以用游标方式处理内存装不下的大文件,用法和前面的小文件类似,只要把import函数换成使用cursor函数即可返回游标,并支持在游标上附加各种运算。
如第2节中的几个例子:
A |
说明 |
|
1 |
=file("E:/txt/Students_scores.txt").cursor@t() |
数据读成游标,@t表示第1行是标题行 |
2 |
=A1.select(CLASS==10) |
筛选出10班的学生成绩 |
3 |
=A1.groups(CLASS;min(English),max(Chinese),sum(Math)) |
按班级分组计算,结果集不大时用groups返回序表 |
4 |
=A1.groupx(CLASS;min(English),max(Chinese),sum(Math)) |
结果集很大时用groupx返回游标 |
5 |
=A1.sortx(CLASS,-Math) |
排序后返回游标 |
大文件的运算结果也可能很大,可以返回成游标再进一步处理。例如从上表第4行的结果中取出前10个班级的结果:
=A1.groupx(CLASS;min(English),max(Chinese),sum(Math)).fetch(10)
把第5行排序后的结果保存到文件:
=file("E:/txt/sorted_scores.txt").export@t(A1.sortx(CLASS,-Math))
更多大文本读取介绍请参阅《SPL:结构化文本文件读取》
更多大文本运算介绍请参阅《SPL:游标上的常规 SQL 式运算》
SPL计算出的游标也可以返回给JAVA,用JDBC接口调用的方法和前面是一样的。
对于大文本也可以使用SQL,与小文本时没有区别。


英文版