


SPL 常规数据表运算
在SPL中,从数据源将数据读成序表以后,就可以进行所有SQL式的运算,如过滤、汇总、跨列计算、排序、分组汇总、分组过滤、Top-N、分组Top-N、去重、分组去重、关联查询等。本文以文件数据源举例讨论序表上的SQL式运算。
1. 过滤
从数据表中筛选出满足条件的记录。
示例:从学生成绩表Students_scores.txt中筛选出10班的学生成绩,文件中第一行是列名,第二行开始是数据,如下图所示。
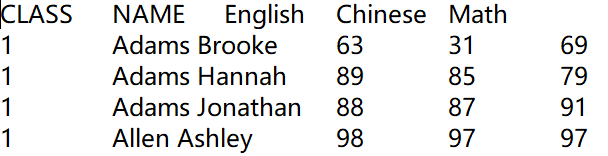
A |
|
1 |
=T(“E:/txt/Students_scores.txt”).select(CLASS==10) |
A1 读取文件中数据,然后选出班级为10的数据记录。T函数会自动根据文件扩展名选用适合的分隔符。
2. 汇总
对数据表中的数据进行汇总。
示例:计算学生成绩表中全体学生的语文平均分、数学最高分、英语总分。
A |
|
1 |
=T(“E:/txt/Students_scores.txt”) |
2 |
=A1.avg(Chinese) |
3 |
=A1.max(Math) |
4 |
=A1.sum(English) |
A1 读取文件中数据,T函数会自动根据文件扩展名选用适合的分隔符。
A2 计算语文平均分
A3 计算数学最高分
A4 计算英语总分
3. 跨列计算
对数据表中的数据进行跨列计算。
示例1:计算学生成绩表中每位学生的总分。
A |
|
1 |
=T(“E:/txt/Students_scores.txt”) |
2 |
=A1.derive(English+Chinese+Math:total_score) |
A1 读取文件中数据,T函数会自动根据文件扩展名选用适合的分隔符。
A2 在A1中新增一列total_score,其值为英语、语文、数学3列之和
A2中结果如下:
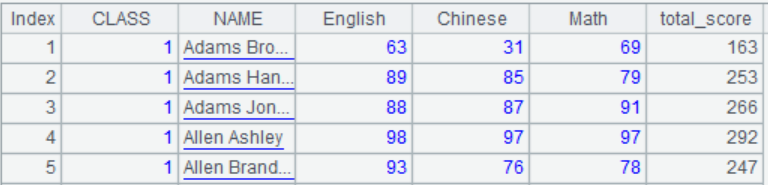
示例2:计算学生成绩表中每位同学的语文成绩评级。
A |
|
1 |
=T(“E:/txt/Students_scores.txt”) |
2 |
=A1.derive(if(Chinese>=90:"Excellent",Chinese>=80:"Good",Chinese>=60:"Pass","Fail"):Chinese_evaluation) |
A1 读取文件中数据,T函数会自动根据文件扩展名选用适合的分隔符。
A2 在A1中新增一列Chinese_evaluation,当语文成绩在90以上时评级为Excellent,80以上时评级为Good,60以上时评级为Pass,否则评级为Fail。
A1中结果如下,增加了一个新的计算列Chinese_evaluation:
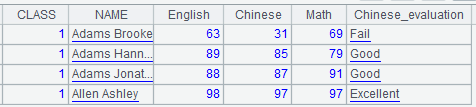
4. 排序
对数据表中的数据进行升/降序排序。
示例:将学生成绩表按照班号升序、总分降序的顺序排列。
A |
|
1 |
=T(“E:/txt/Students_scores.txt”) |
2 |
=A1.sort(CLASS) |
3 |
=A1.sort(CLASS,-Math) |
A1 读取文件中数据,T函数会自动根据文件扩展名选用适合的分隔符。
A2 按班级号升序排列
A3 先按班级号升序排列,班级内再按数学成绩降序排列
5. 分组汇总
对数据表中的数据进行分组汇总。
示例:查询各班的英语最低分、语文最高分、数学总分。
A |
|
1 |
=T(“E:/txt/Students_scores.txt”) |
2 |
=A1.groups(CLASS;min(English),max(Chinese),sum(Math)) |
A1 读取文件中数据,T函数会自动根据文件扩展名选用适合的分隔符。
A2 按班级分组,计算各班英语最低分、语文最高分、数学总分
6. 分组后过滤
对数据表中的数据分组汇总后再过滤。
示例:找出英语平均分低于70分的班级。
A |
|
1 |
=T(“E:/txt/Students_scores.txt”) |
2 |
=A1.groups(CLASS;avg(English):avg_En) |
3 |
=A2.select(avg_En<70) |
A1 读取文件中数据,T函数会自动根据文件扩展名选用适合的分隔符。
A2 按班级分组,计算各班英语平均分命名新列名为avg_En
A3 从A2中选出英语平均分低于70的
A3中查询结果如下:

7. Top-N
对数据表中的数据求TOP-N。
示例:查看英语成绩最高的3个同学成绩。
A |
|
1 |
=T(“E:/txt/Students_scores.txt”) |
2 |
=A1.top(-3;English) |
A1 读取文件中数据,T函数会自动根据文件扩展名选用适合的分隔符。
A2 按英语降序排列后,取出前3个英语成绩最高的同学成绩记录
8. 分组Top-N
对数据表中的数据分组后求各组TOP-N。
示例:查看各班英语成绩最低的3个同学的英语成绩。
A |
|
1 |
=T(“E:/txt/Students_scores.txt”) |
2 |
=A1.groups(CLASS;top(3,English)) |
A1 读取文件中数据,T函数会自动根据文件扩展名选用适合的分隔符。
A2 按班级分组,各组英语升序排列后,取出前3个最低的英语成绩。
这里的top函数与前例的参数分隔符不同,逗号分隔时,返回前n个排序表达式的值组成的序列;分号分隔时,返回前n个记录组成的序列。
9. 去重
对数据表中的数据进行去重查询。
示例:查询所有班级编号。
A |
|
1 |
=T(“E:/txt/Students_scores.txt”) |
2 |
=A1.id(CLASS) |
A1 读取文件中数据,T函数会自动根据文件扩展名选用适合的分隔符。
A2 查出所有不重复的班级编号。
10. 去重计数
对数据表中的数据进行去重计数。
示例:查询共有多少个班级编号。
A |
|
1 |
=T(“E:/txt/Students_scores.txt”) |
2 |
=A1.icount(CLASS) |
A1 读取文件中数据,T函数会自动根据文件扩展名选用适合的分隔符。
A2 查出所有不重复的班级编号的个数。
11. 分组去重计数
对数据表中的数据进行分组后去重计数。
示例:产品销售记录文件sales.txt如下图,查询每个产品有销售记录的天数。

A |
|
1 |
=T(“E:/txt/sales.txt”) |
2 |
=A1.groups(PID;icount(DATE):days) |
A1 读取文件中数据,T函数会自动根据文件扩展名选用适合的分隔符。
A2 按产品编号PID分组,统计本组不同日期个数命名为 days
12. 外键关联
两个数据表,表A中的某些字段与表B的主键关联,B称为A的外键表,称此关联为外键关联。
示例:销售订单信息和产品信息分别存储在两个Excel文件中,计算各订单的销售额。两个文件数据结构如下图:
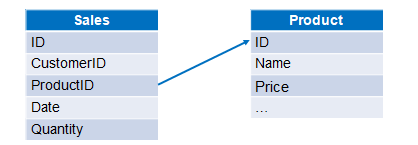
对于这种单外键关联有两种方法实现,方法一:
A |
|
1 |
=T(“e:/orders/sales.xlsx”) |
2 |
=T(“e:/orders/product.xlsx”).keys(ID) |
3 |
=A1.switch(ProductID,A2:ID) |
4 |
=A3.derive(Quantity*ProductID.Price:amount) |
A1 读取销售订单数据
A2 读取产品信息数据,并设ID为主键
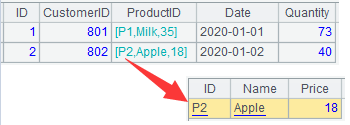
A3 用switch函数将A1中ProductID与A2中的ID进行关联(ID为主键时也可省略不写),此时ProductID列转换成了指向与它对应的产品记录,如下图所示
A4 A3中新增一列amount,其值为销售数量Quantity与产品价格Price的积,表达式ProductID.Price表示ProductID列指向的记录的Price列值
方法二:
A |
|
1 |
=T(“e:/orders/sales.xlsx”) |
2 |
=T(“e:/orders/product.xlsx”).keys(ID) |
3 |
=A1.join(ProductID,A2:ID,Name,Price) |
4 |
=A3.derive(Quantity*Price:amount) |
A1 读取销售订单数据
A2 读取产品信息数据,并设ID为主键
A3 用join函数将A1中ProductID与A2中的ID进行关联(ID为主键时也可省略不写),同时引入A2中Name、Price列数据,如下图所示
A4 A3中新增一列amount,其值为销售数量Quantity与产品价格Price的积

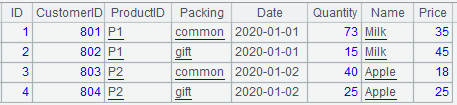
而对于多个外键字段关联的情况,就不能用switch函数了,只能用join函数来关联。假如产品包装方式不同时,定价Price不同。在产品信息和销售订单信息表中加上Packing字段,产品信息的主键变成了ID和Packing,部分数据如下图:

此时再计算订单销售额的示例如下:
A |
|
1 |
=T(“e:/orders/sales.xlsx”) |
2 |
=T(“e:/orders/product.xlsx”).keys(ID,Packing) |
3 |
=A1.join(ProductID:Packing,A2,Name,Price) |
4 |
=A3.derive(Quantity*Price:amount) |
A1 读取销售订单数据
A2 读取产品信息数据,并设ID、Packing为主键
A3 用join函数将A1中ProductID、Packing与A2中的主键进行关联,同时引入A2中Name、Price列数据,如下图所示
A4 A3中新增一列amount,其值为销售数量Quantity与产品价格Price的积
13. 主键关联
表A的主键与表B的主键关联,A和B相互称为同维表。同维表是一对一的关系,逻辑上可以简单地看成一个表来对待。同维表都是按主键关联,相应记录是唯一对应的。
例如有员工信息表employee.xlsx与员工工资表salary.xlsx,主键都是Eid,部分数据如下:
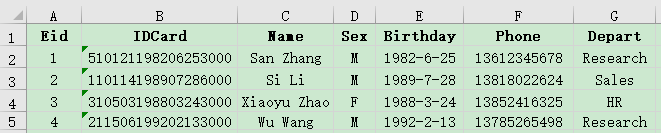
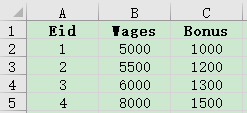
现需查出员工的基本信息和工资信息:
A |
|
1 |
=T("e:/work/employee.xlsx") |
2 |
=T("e:/work/salary.xlsx") |
3 |
=join(A1:emp,Eid;A2:salary,Eid) |
4 |
=A3.new(emp.Eid,emp.IDCard,emp.Name,emp.Sex,emp.Phone,emp.Depart,salary.Wages,salary.Bonus) |
A1 读取员工信息表数据
A2 读取员工工资表数据
A3 将A1与A2按照Eid进行关联,将A1命名为emp,A2命名为salary
A4 取出A3中emp的Eid、IDCard、Name、Sex、Phone、Depart和salary的Wages、Bonus列,构造一个新序表
还有一种主子表形式的主键关联。表A的主键与表B的部分主键关联,A称为主表,B称为子表。主子表是一对多的关系。
例如有员工家庭成员表family.xlsx部分数据如下,它有两个主键字段Eid、Fid,请查询家中有70岁以上老人的员工信息。
A |
|
1 |
=T("e:/work/employee.xlsx") |
2 |
=T("e:/work/family.xlsx").select(age(Birthday)>=70) |
3 |
=join(A1:employee,Eid;A2:family,Eid) |
4 |
=A3.conj(employee) |
A1 读取员工信息数据
A2 读取员工家庭成员数据,选出年龄70以上的成员
A3 将A1与A2按照Eid进行关联过滤,删除不匹配的记录,将A1命名为employee,A2命名为family
A4 取出A3中的employee列,连接为序表
附件:本文所用数据文件

