


SPL:结构化文本文件读写
结构化文本也就是行式文本文件,是很常见的文件格式,比如TXT、CSV。结构化文本文件通常每行对应一条记录,各行有相同的列,相当于数据库中的一张数据表。读写时需要注意如下一些问题:
1、 标题行:此行是各字段的名称,总是位于第一行。也可以没有标题行,第一行就是数据记录。
2、 分隔符:用此符号分隔开每行中各字段的值,标题行也是如此。常用的有逗号、Tab键(\t)、竖线等。
3、 字符集:保存文件数据时使用的字符集名称,如UTF-8、ISO8859-1、GBK等。
4、 特殊字符:字段数据中含有一些特殊字符,如引号、括号、转义符等,常见的转义符如\”、\t、\n、\r和Excel中的两个双引号。
5、 大文件:文件数据很多,不能全部装入内存中。
SPL在读写结构化文本数据时,可以很方便地处理以上问题。
1. 读取
SPL用file函数打开文本文件,读成序表或游标,然后就可以进一步计算了。当文件数据不大,能够全部装入内存时,用import函数将数据读成序表;当文件数据很大,不能全部装入内存时,用cursor函数将数据读成游标。
下面是一些读取例子,以import函数举例,用cursor函数时选项和参数也是相同的。
1.1 有标题行、Tab 键分隔
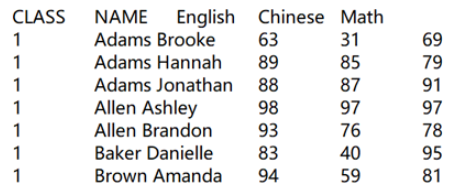
=file("scores.txt").import@t()
file函数的参数可以是文件的绝对路径,也可以是相对路径(相对于SPL配置文件中的主目录mainPath),import函数选项@t表示有标题行,默认分隔符为Tab键(\t)。
1.2 无标题行、逗号分隔
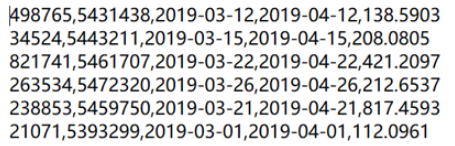
=file("d:/order/orders.txt").import@c()
选项@c表示是逗号分隔的CSV文件,没有选项@t表示无标题行。无标题的文件读出来没有列名,就用#1、#2等序号方式来引用列。
1.3 有标题行、竖线分隔、utf-8 字符集

=file("d:/txt/employee.txt":"utf-8").import@t(;,"|")
在file函数上可以增加字符集参数,字符集不对时,可能会读出乱码。如果没写字符集,则会使用操作系统默认的。import()选项@t表示有标题行,参数"|"表示用竖线分隔。
=file("d:/txt/employee.txt":"utf-8").import@t(EID,NAME,GENDER,DEPT;,"|")
增加列名参数,表示只读出EID,NAME,GENDER,DEPT字段的值。
1.4 有标题行、有 JSON 格式数据
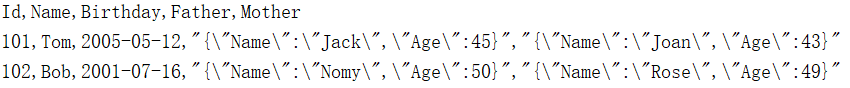
=file("d:/txt/employee.txt").import@tcq()
选项中的t表示有标题行;c表示是逗号分隔;q表示剥离数据项两端引号,包括标题,处理转义,中间的引号不管。
读入以后的序表数据如下图所示:

1.5 有标题行、数据含有括号

=file("d:/txt/measure.txt").import@tcp()
选项中的t表示有标题行;c表示是逗号分隔;p表示解析时处理括号和引号匹配,忽略括号内分隔符,包括@q功能,同时引号外转义也处理。
读入以后的序表数据如下图所示:
1.6 类型指定和日期时间格式

如果按默认方式读入这个文件数据,Phone列会读成长整数,Birthday会读成字符串。要正确读入,需要指定字段数据类型和日期格式。
=file("d:/txt/empinfo.txt").import@t(ID,Name,Phone:string,Birthday:date:"dd/MM/yyyy")
在需要读入的字段参数中,指定Phone的数据类型为字符串(string),Birthday的数据类型为日期(date),格式为dd/MM/yyyy。
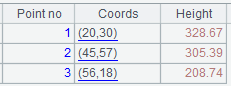
1.7 有单引号、续行和转义符

为了使Phone的值为字符串,值两端加了单引号,文件中第2行末的\表示续行,最后一行中有转义符\r\n表示Comments列的值是两行组成。
=file("d:/txt/room.txt").import@tclqa()
选项中的t表示有标题行;c表示是逗号分隔;l(字母)表示行尾是转义字符\时为续行,下一行与本行内容连接起来解析;q表示剥离数据项两端引号,处理转义;a表示在使用选项q时把单引号也作为引号处理,没有a选项时只处理双引号。
读入以后的序表数据如下图所示:

在第 3 行 3 列上点击右键查看长文本,显示:

1.8 Excel 规则转义的文本

=file("d:/txt/race.txt").import@tcqo()
选项中的t表示有标题行;c表示是逗号分隔; q表示剥离数据项两端引号,处理转义;o表示使用Excel标准转义,串中两个引号表示一个引号,其它字符不转义。
读入以后的序表数据如下图所示:
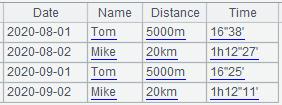
特别地,在 Excel 导出的 CSV 中,TAB、回车都不需要转义,会直接写在文本中,文本值两端加上双引号。比如在这个文件中再加一列Comments,内容如下:

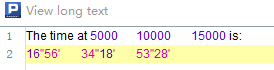
第2行的Comments中包含了回车和4个Tab键,读入以后查看它的内容如下:
1.9 错误数据处理
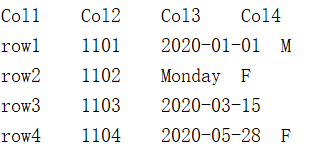
这个文件中,第2行第3列的数据类型不对,第3行少一列。
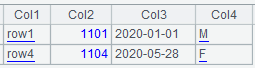
=file("d:/txt/data.txt").import@tdn()
选项中的t表示有标题行;d表示行内有数据不匹配类型和格式时删除该行,如果有选项p或q时括号和引号不匹配也删除该行;n表示列数比第一行少时也作为错误处理,将删除该行。
读入以后的序表数据如下图所示,第2行和第3行被删除:
如果希望在选项d或n检查到数据错误时中断脚本运行,抛出异常,那么可以加上v选项。
=file("d:/txt/data.txt").import@tdnv()
此时会抛出错误信息:

更多读取用法请参考SPL资料中import和cursor函数说明。
2. 写出
将SPL中计算处理后的序表、序列或排列写入文本文件时,用file函数打开文本文件,然后用export函数写入。对于游标中的大数据,采用循环分批取数,追加写入的方式。
下面是一些写入例子,假定A1是需要写入文件的序表。
2.1 有标题行、Tab 键分隔
=file("d:/txt/scores.txt").export@t(A1)
选项@t表示输出标题行,默认分隔符为Tab键(\t)。
=file("d:/txt/scores.txt").export@t(A1,CLASS,Name,English)
指定了字段名参数,表示只写入A1中的CLASS,Name,English字段的值。
2.2 无标题行、指定分隔符
=file("d:/txt/scores.txt").export@c(A1)
没有选项@t表示不输出标题行,直接从数据行开始写入。选项c表示用逗号作为分隔符。
=file("d:/txt/scores.txt").export@c(A1;"|")
指定了分隔符参数,表示用竖线作为分隔符。此时虽然也有选项c,但以分隔符参数优先,忽略选项c。
2.3 追加写入
=file("d:/txt/scores.txt").export@ta(A1)
选项a表示在文件末尾追加写入,追加的内容要与原文件内容结构相同,否则报错;文件已有内容时忽略选项t。
2.4 加引号
在字段值是数字串时,写入文件想标明它是字符串而不是数字,需要在值两端加上引号;或者字段值比较复杂,比如是多行文本、含有分隔符、JSON串等,也需要在两端加上引号表明它是一个字段值。
=file("d:/txt/empinfo.txt").export@tcq(A1)
选项q表示导出的字符串字段值和标题都带有引号,同时添加转义符。如下图所示:

2.5 按 Excel 规则转义
=file("d:/txt/empinfo.txt").export@tco(A1)
选项o与选项q一样,也会给字符串型字段值和标题加上引号,但它使用Excel规则转义,串中双个引号表示一个引号,其它字符不转义。如下图所示:

更多写出用法请参考SPL资料中export函数说明。


英文版