


【程序设计】10.1 [找关联] 主键
10.1 主键
在讲结构化数据概念时,我们说过数据表的字段有名字,但记录却没有名字。那么我们用什么办法来标识一条记录和另一条记录的不同呢?我们知道,每条记录都对应着某个事物的信息,到底是哪个呢?怎么确定现在引用或操作的记录就是对应着期望事物的那一条呢?
使用记录在序表中的次序来标识经常是不太可靠的,因为随着插入删除动作,这个序号会改变。
在前面章节中例子,我们创建和引用的序表大多有一个字段的取值在整个序表中是唯一的,比如人员表里的 id 字段或股票表中的 dt 字段。结构化数据就是利用这种有唯一取值的字段值来标识记录的。
在数据表中,如果有一个或多个字段,任何两条记录在这个字段上的取值(多个字段就是取值构成的序列)都不相同,则可以设置这些字段为数据表的主键。
注意,主键是人为设定的,不是自动找出来的。一个数据表中可能有多个(或套)字段都满足主键的条件(唯一性),但我们只会选择其中一个(套)来作为主键。主键必须有唯一性,但有唯一性的字段未必是主键。
某条记录的主键的字段值,也称为该记录的主键值,在上下文无歧义时也会简称主键。
因为主键有唯一性,也就是说记录的主键值在整个数据表中不会有重复的,所以可以用主键来唯一标识一条记录。我们说现在引用或操作的记录是主键为 xxx 的记录,那就只会有一条这样的记录,不会搞错了。
对于一个设置了主键的数据表,原则上将不允许增加和已有记录主键相同的新记录。插入删除记录时,主键也不会改变,使用主键标识记录时比使用序号要稳定。
不过,主键不是必须要有的(之前的例子确实也都没有),没有主键的数据表通常只会追加记录而不会再修改删除已有记录或在前面插入新记录,因为这些动作都会导致序号改变。
其实,我们在日常生活中对主键的概念并不陌生。学校的学生都会有个唯一的学号,学号这个属性本身并没有什么有效的信息量,它的作用仅仅是用来唯一标识某个学生。直接使用学生的姓名是不行的,人的重名情况很多,很难准确地标识某个学生。而像订单这种事物,本来就没有名字,更需要有个(唯一的)编号来标识,否则根本不知道怎么确定在谈论哪个订单。其它类似的还有航班号、银行帐号、电话号码等等,都是起到主键的作用。
生活中的“主键”几乎无处不在,结构化数据的主键只是人们的日常经验在程序语言中的一个体现而已。主键就是记录的名字,设置主键就是给记录起个(唯一的)名字。
SPL 提供了一些针对主键的函数:
A |
|
1 |
=1000.new(string(1000+~):id,if(rand()<0.5,"Male","Female"):sex) |
2 |
=A1.keys(id) |
3 |
=A1(1).key() |
A2 用 keys 函数可以设置序表的主键为 id 字段,A3 中用 key() 计算某条记录的主键。
设置了主键的序表,在显示值时会在主键字段上画一个钥匙图标。
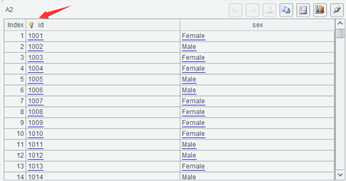
不过, SPL 并没有在设置主键时检查主键的唯一性,是否唯一由编程人员自己控制。
用我们学过的分组运算很容易判断某个字段在数据表中是不是唯一:
A |
|
1 |
=1000.new(string(rand(1000)):id,if(rand()<0.5,"Male","Female"):sex) |
2 |
=A1.id().len()==A1.len() |
看看 DISTINCT 后的序列是不是和原序表一样长就知道了。
插入记录时,SPL 也没有检查主键的唯一性,下面这样的代码不会报错。
A |
|
1 |
=1000.new(string(1000+~):id,if(rand()<0.5,"Male","Female"):sex) |
2 |
=A1.keys(id) |
3 |
=A1.insert(1,"1002") |
SPL 只是需要主键唯一性的时候才会来检查,这样的好处是能有更好的运算性能,每次检查是很耗时的动作,但坏处是会有出错的隐患。SPL 的原则充分相信程序员,是把自由留给程序员。
主键的主要用户是用来标识记录,也就是用主键值来查找记录。
A |
|
1 |
=1000.new(string(1000+~):id,if(rand()<0.5,"Male","Female"):sex) |
2 |
=A1.keys(id) |
3 |
=A1.find("1053") |
SPL 用 find 函数返回主键为其参数的记录,如果找不到则会返回 null。
现在用举例子的序表,记录的主键和记录的序号一样是从小到大排列的,这是为了方便生成有唯一性的字段(如果随机生成还得对比是不是重复了)。但 SPL 对于主键并没有这个要求,它可以是乱序的:
A |
|
1 |
=1000.(string(1000+~)).sort(rand()) |
2 |
=1000.new(A1(#):id,if(rand()<0.5,"Male","Female"):sex) |
3 |
=A2.keys(id) |
4 |
=A2.find("1053") |
A4 也可以正常找到以参数为主键的记录。
由于 SPL 不检查主键的唯一性,如果序表中有主键相同的记录,find 也不会报错,它会找到第 1 条返回,有点像 select@1。
顺便提一下,find 和 pos 类似,不是循环函数,它的参数会在调用它的时候就先计算出来,也不会再有 ~、# 之类的东西。
使用主键来查找记录是很常见的动作,如果序表稍大一点,那么查找速度就会比较慢,因为通常这种查找都需要逐个对比。
SPL 提供了为主键建立索引的机制,之后的查找速度就会快得多。
A |
B |
|
1 |
=1000.(string(1000+~)).sort(rand()) |
|
2 |
=1000.new(A1(#):id,if(rand()<0.5,"Male","Female"):sex) |
|
3 |
=A2.keys(id) |
|
4 |
=now() |
>10000.run(A2.find(string(1000+rand(1000)))) |
5 |
=now() |
=interval@ms(A4,A5) |
6 |
>A2.index() |
|
7 |
=now() |
>10000.run(A2.find(string(1000+rand(1000)))) |
8 |
=now() |
=interval@ms(A7,A8) |
index 函数将为有主键的序表建立索引,建过索引后的 find 会自动使用索引。
执行这段代码对比建索引之前和之后的运行时间,会发现性能差距非常巨大(不过也要执行 1 万次且用 interval@ms 才能捕捉到)。有索引之后不再使用逐个对比的办法来查找了,具体方法远远超出了本书内容,这里就不解释了。
SPL 建索引时要求主键的唯一性。在执行 index() 时,SPL 才去检查主键是不是唯一的。如果这时候发现主键不唯一,就会报出主键重复的错误信息。
SPL 看来有点懒,不到必要时刻不会主动做事。
和前面讲过的运算不一样,主键和索引只能建立在序表上,不能建立在排列上。它们是数据结构的一部分。
不过,find 却可以用到排列上,只是没法使用索引,只能一个个对比,找到哪个算哪个。
说句题外话,如果主键是按次序排列的,find 还支持一种叫二分法的快速查找技术,比逐个对比要快得多(接近索引,但还是赶不上),对于没有索引的排列或没有建索引的序表都可以使用。select 函数和 pos 函数也支持这个二分法,有兴趣的读者可以去参考 SPL 的相关资料,因为高性能计算不是本书的重点(刚才也没去讲索引的原理),这里就不再赘述了。
再回顾一下上一章讲过的分组运算。观察 groups 返回的序表,显然其中分组键值对应的字段具有唯一性,也就是说,这些字段天然能构成 groups 返回序表的主键。所以,我们把用来分组的依据称为键。细心的读者可能已经发现,查看 groups 的返回结果时,分组键上已经被画上了小钥匙图标。

