


【程序设计】9.4 [分类别] 扩展与转置
9.4 扩展和转置
分组后再汇总,通常会得到一个比原集合更小的集合,相当于做了聚合。那么,有没有分组的逆运算,用一个较小的数据表通过某种规则计算出一个更大的数据表呢?
我们把这类运算称为扩展或者逆分组。
不过,汇总后的数据一般已经失去明细信息了,不能实现逆向计算。进行扩展运算需要有明确的扩展规则。
序表中存有一些客户的的贷款信息,有贷款期数、金额。现在要按等额本息方法计算出这些人每月的还款金额,利率是个常数。
A |
B |
|
1 |
=10.new(string(~):id,rand(20):number,rand(100):amount) |
>rate=0.05/12 |
2 |
=A1.news(number;id,month@y(elapse@m(now(),#)):ym,amount*(1-rate*power(1+rate,number)/power(1+rate,number)):payment) |
|
A2 中的 news 函数将针对 A1 的每一个成员生成 number 条记录,字段名和计算式由后面的参数描述。这个分期贷款的计算公式是网上抄的,它不是重点。
体会一下参数中的 #。news 函数本质上会是一个两层循环函数,先针对 A1 做循环函数,再针对第一个参数 number 做循环函数,分号后面的参数实质上针对内层循环函数的,即这里的# 是针对 number 这一层而言的,也就是第几期贷款,而不是第几个 A1 的成员。
这个代码的计算量有点大,因为等额本息方法时,每个月还款金额实际上一样的,没有必要重复计算这么多次,只要针对每个 A1 的成员计算一次就行了。
A |
B |
|
1 |
… |
… |
2 |
=A1.(amount*(1-rate*power(1+rate,number)/power(1+rate,number))) |
|
3 |
=A1.news(number;id,month@y(elapse@m(now(),#)):ym,A2(A1.#):payment) |
|
注意,这里就要用 A1.# 来引用外层循环函数的序号了。
我们再来实现前一节字符串合并时的逆运算。
A |
|
1 |
=100.new(string(~):name,if(rand()<0.5,"Male","Female"):sex) |
2 |
=A1.group(sex;~.(name).concat@c():Names) |
3 |
=A2.news(Names.split@c();~:name,sex) |
A3 将把 A2 中拼起来起来的字符串再拆分开,扩展成与 A1 同样行数的记录。
再体会一下 news 本质是个两层循环函数,后面参数中的 sex 是外层循环函数的字段,因为内层找不到这个字段,SPL 会自动到外层找,就可以不必写 A2.sex 了。而 ~ 则是内层循环函数的当前成员,也就是拆开后的名字。
还有更常见的扩展运算:将数据表的列(字段)扩展成行(记录)。
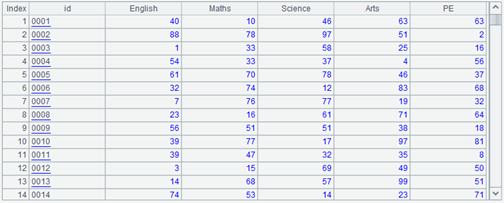
我们需要再次使用前面用过一次的学生成绩表:
A |
|
1 |
[English,Maths,Science,Arts,PE] |
2 |
=A1.("rand(100):"+~).concat@c() |
3 |
=100.new(string(~,"0000"):id, ${A2}) |
A3 会生产一个有 6 个字段的数据表,除 id 字段外,其它都是一个学科(的成绩)。
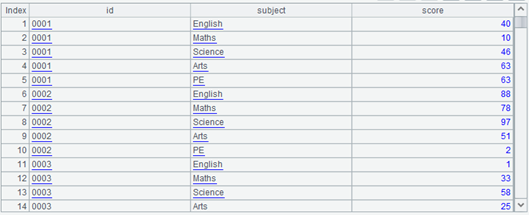
在讲结构化数据概念时,我们曾经提过,由于这些学科都是同等地位的,有可能发生针对这些学科(成绩)的统计,所以,更常见的数据结构会是 3 个字段的:id,subject,score。现在数据表的字段名将变成新数据表 subject 的字段值,原表每条记录将变成新表的 5 条记录(有 5 个学科),这就发生了扩展运算。
我们可以用 news 写出来
A |
|
… |
… |
4 |
=A3.fname().to(2,) |
5 |
=A3.news(A4;id,~:subject,A3.~.field(~):score) |
A4 列出所有的科目字段,然后在 A5 执行扩展运算。注意后面那个 A3..field() 中的两个 ~,前者是 A3.即 A3 当前的记录,也就是现在正在被扩展的记录,后者是 A4 的,也就是某个科目字段。
现在的 A5 变成这样的数据结构:
这种运算很常用,SPL 中给了个专门的函数来处理:
A |
|
… |
… |
4 |
=A3.fname().to(2,) |
5 |
=A3.pivot@r(id;subject,score;${A4.concat@c()}) |
对于这种除 id 外其它字段都要被扩展的情况,还可以进一步简化写成:
A |
|
… |
… |
4 |
=A3.pivot@r(id;subject,score) |
细心的读者可能发现这个 pivot 函数用了个 @r 选项,那么没有 @r 选项的会计算出什么呢?
没有 @r 时是它的逆运算,相当于分组。
A |
|
… |
… |
4 |
=A3.pivot@r(id;subject,score) |
5 |
=A4.pivot(id;subject,score) |
我们会发现,A5 又回到了 A3,但字段次序发现了变化,学科字段变成按字母次序排列了, 不过数据都没有问题。如果希望按原来的字段次序,那需要把字段列表写到参数里:
5 |
=A4.pivot(id;subject,score;${A1.concat@cq()}) |
concat 加 @q 表示将多拼上引号,下面会解释为什么。
pivot 函数又称为转置运算,有 @r 则称为逆转置。
转置是分组运算的变种,也可以用分组实现出来:
A |
|
… |
… |
4 |
=A3.pivot@r(id;subject,score) |
5 |
=A4.id(subject) |
6 |
=A4.group(id;${A5.("~.select@1(subject==\""+~+"\").score:"+~).concat@c()}) |
可以看出来,这里的 A6 也回到了 A3(学科字段也被排序了,如果要用原序,在 A6 表达式中用 A1 替换 A5 即可)。
A6 表达式中的宏较复杂,但仔细研究也能看明白,也就是将当前分组子集中与某个学科名称相同的分数取出来作为分组后序表该学科字段的取值。因为在 A4 中学科是个字符串,分组子集是由 A4 中的记录构成的,所以比较时也要加上引号。前面用 pivot 的代码中使用是相同原理,所以 concat 时要加 @q 选项。这个写法确实有点麻烦,所以 SPL 提供了 pivot 函数直接完成这种分组及汇总。
也就是说,转置只是一种分组汇总运算;相应的,逆转置也就是扩展运算。
需要强调的是,这个转置和 Excel 里的转置并不一样,Excel 那个相当于矩阵的转置,就是简单的行列互换(行变列,列变行)。这里的转置其实是多维分析中的旋转。它是分组运算的延伸变种(逆转置则是逆分组的变种),通常要有个字段充当分组键,而这个字段是稳定的,不会被转移成列。英语中本来也是两个词 transpose 和 pivot,汉语也常常会把这种运算叫旋转,但通俗地称为转置的情况更多。
不过,SPL 的转置和常规的分组还是略有不同,从上面 A6 的表达式可以看出来,它不会再对分组子集进行聚合,而只是简单取第 1 条。事实上,这个运算是假定每个分组子集中再用目标表的字段名过滤后,只有一条记录(或者一条也没有)。如果这个时候还有多条记录(理论上是可能的),pivot 函数已经没有地方来描述如何聚合这些记录了,比较好的办法是事先先做一轮分组汇总,然后再做 pivot 函数。
A |
|
1 |
[English,Maths,Science,Arts,PE] |
2 |
=100.new(string(rand(10),"0000"):id, A1(rand(5)+1):subject,rand(100):score) |
3 |
=A2.pivot(id;subject,score) |
4 |
=A2.groups(id,subject;sum(score):score) |
5 |
=A4.pivot(id;subject,score) |
6 |
=A2.pivot@s(id;subject,sum(score)) |
我们在 A2 中生成的序表有重复的 id 和 subject,这样 pivot 时就会发生分组子集被字段名过滤后还有多条的记录,直接做 pivot 很可能得不到期望的结果(A3);需要先做一轮分组聚合(A4),然后再用 pivot(A5);如果所有字段的聚合方式都相同,也可以简写成 A6 的样子,用选项 @s 表示需要多做一步聚合,聚合函数写在参数上。如果不相同(比如有的算 sum,有的算 max),就只能先做一步 A4 这样的聚合了。
使用没有第三段参数(第 2 个分号之后)的 pivot 很方便,但可能会因为数据的缺失而导致结果序表中有些希望有的字段没有生成。
A |
|
1 |
[English,Maths,Science,Arts,PE] |
2 |
=100.new(string(~,"0000"):id, A1(rand(5)+1):subject,rand(100):score) |
3 |
=A2.select(subject!="Arts") |
4 |
=A3.pivot(id;subject,score) |
5 |
=A3.pivot(id;subject,score;${A1.concat@cq()}) |
A3 把 Arts 学科都过滤掉之后再做 pivot,结果会少一列,没有 Arts 学科。要按 A5 的写法强制列出所有学科,结果序表中缺失数据的字段的相应值会填成 null。


文中 pivot 称为透视列功能更合适些,而 pivot@r 我们一般称为逆透视列😄
Excel 叫透视,数据库术语应该是旋转 (pivot 这词的英文就是旋转的意思),也俗称是转置。中文世界没啥标准,叫啥的都有,随便取一种
您的帖子写的很好,我是比照着 excel 里面的 power query 对照看的,看到很多功能二者异曲同工,非常巧妙。
我的感受是 SPL 的设计者是非常懂 EXCEL 表格的😋