


ChatBI 应该这么玩,中小用户才是主战场
聊到 ChatBI,很多人的第一反应往往是“百亿参数大语言模型(LLM)”、“动辄上百万的智能项目”。行业的热烈讨论,制造了一种错觉:这项能力是财力雄厚、技术栈成熟的大型企业的专属品。
但一个被忽略的真相是:恰恰是那些没有专业数据分析师、没有复杂数据仓库的广大中小企业,才是 ChatBI 最应该被普惠的用户。
为什么说中小企业才是 ChatBI 的“主战场”?
对中小企业来说,ChatBI 的价值在于应用门槛极低——普通人用说话的方式就能问数据,不用学复杂的操作流程,也无需配备专门的数据团队。这正是他们需要的,因为他们既建不起传统 BI 所需的数据平台,也养不起专业分析人员。
当管理者面对“这个月哪款产品利润最高?”或“为什么华东区库存周转慢了?”这类具体问题时,他们需要的不是炫酷的 AI 概念,而是能像问一位懂业务的同事那样,从日常使用的业务系统中立刻获得清晰、准确的答案。
大型企业拥有数据团队和成熟数仓,引入 ChatBI 更多是为了给已有的 BI 系统提升效率,ChatBI 对他们来说是“锦上添花”。而中小企业缺乏这些基础,加之本来就没有 BI 系统,拥有 ChatBI 才是真正的“雪中送炭”。
但是,照搬大企业的那套 ChatBI 方案又不可行,因为中小企业真实的需求场景完全不同:
老板、店长就是一线用户,他们不擅长复杂工具,唯一自然的交互方式就是“提问”。
数据就在业务系统里,所有经营数据都产生于正在使用的 ERP、进销存、财务软件中,没有能力也不必要再建独立数据仓库。
对成本和速度极度敏感,必须“开箱即用、快速见效、结果可信”,承受不起重投入和长周期。
所以,面向中小企业的 ChatBI,并不是再建一套独立的 BI 平台,而是应该将问数能力做成一个“智能模块”,直接嵌入他们现有的、熟悉的业务系统内部,与日常工作流无缝融合。
然而,实现这种“嵌入式”智能面临很大的技术难题。当前主流基于大语言模型的 ChatBI 方案,虽然应用起来简单,但实施门槛其实还远高于传统 BI。为了让 AI 理解业务,必须向 LLM 注入领域知识,对模型进行昂贵的再训练或实施复杂的 RAG,这很容易走向私有化部署,带来惊人的 GPU 成本、难以解决的“幻觉”问题,以及持续的算法调优需求。这些技术壁垒和成本门槛,把最需要数据赋能的中小企业,直接挡在了门外。
那么还有出路吗?
有。润乾 ChatBI 方案走了一条务实而巧妙的路线:以“规则引擎”为核心,同时搭配“公共大模型”处理口语化问题。不追求无所不能的“通用智能”,而在明确的业务范围内,做到精准查询、结果可靠。这样不仅在成本、准确性和实施门槛上找到了平衡,而且采用嵌入式设计,能让软件厂商像插芯片一样,为自己的产品快速添加“智能问答数据”的能力。
可嵌入的“规则引擎”,低成本、高可靠的 ChatBI
面向“嵌入”而非“独立平台”的需求,润乾方案的架构核心是一个基于“规则引擎”的“编译式”自然语言处理系统。如同一个高度定制化的翻译机,将用户的自然语言问题,通过预先定义的“业务词典”(映射业务术语到数据库字段)和“语法手册”(解析查询意图的规则),像编译器一样精准“翻译”成可执行的 SQL,并进一步驱动后续的自助报表分析。其技术架构天然适合与现有系统融合,而非替代。
对于应用软件厂商(如 ERP/MIS 开发商)而言,集成润乾 ChatBI 引擎,相当于为自己的系统嵌入一个“智能数据助手”核心,其架构与集成关系可以简化为以下层次。
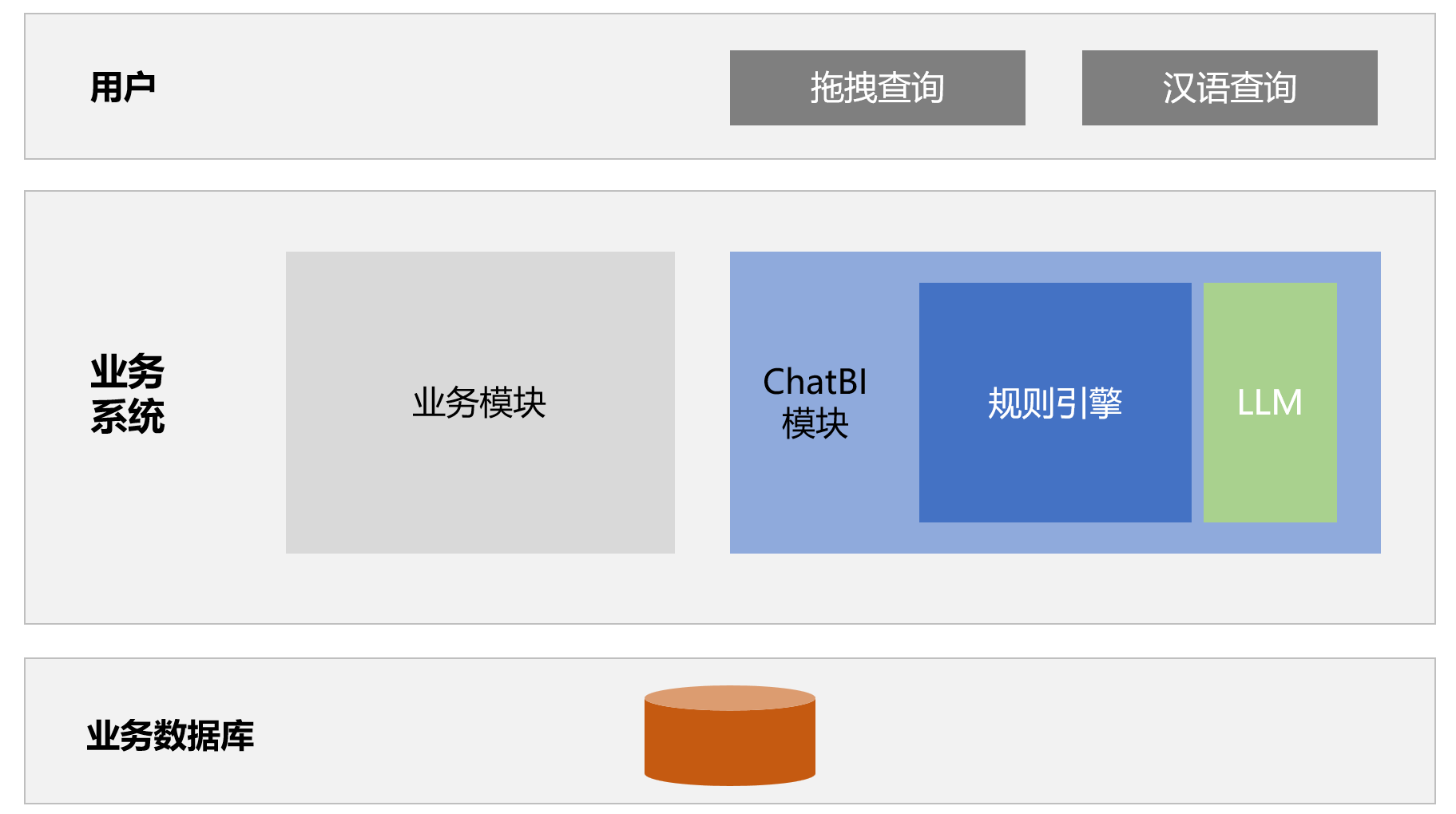 润乾 ChatBI 嵌入业务系统内使用,用户输入汉语命令,比如:“帮我查一下去年北京发往青岛的订单”。规则引擎接收命令后进行一系列翻译动作,最终生成 SQL 提交给数据库查询数据,将结果返回给用户,完成自然语言到数据的查询。
润乾 ChatBI 嵌入业务系统内使用,用户输入汉语命令,比如:“帮我查一下去年北京发往青岛的订单”。规则引擎接收命令后进行一系列翻译动作,最终生成 SQL 提交给数据库查询数据,将结果返回给用户,完成自然语言到数据的查询。
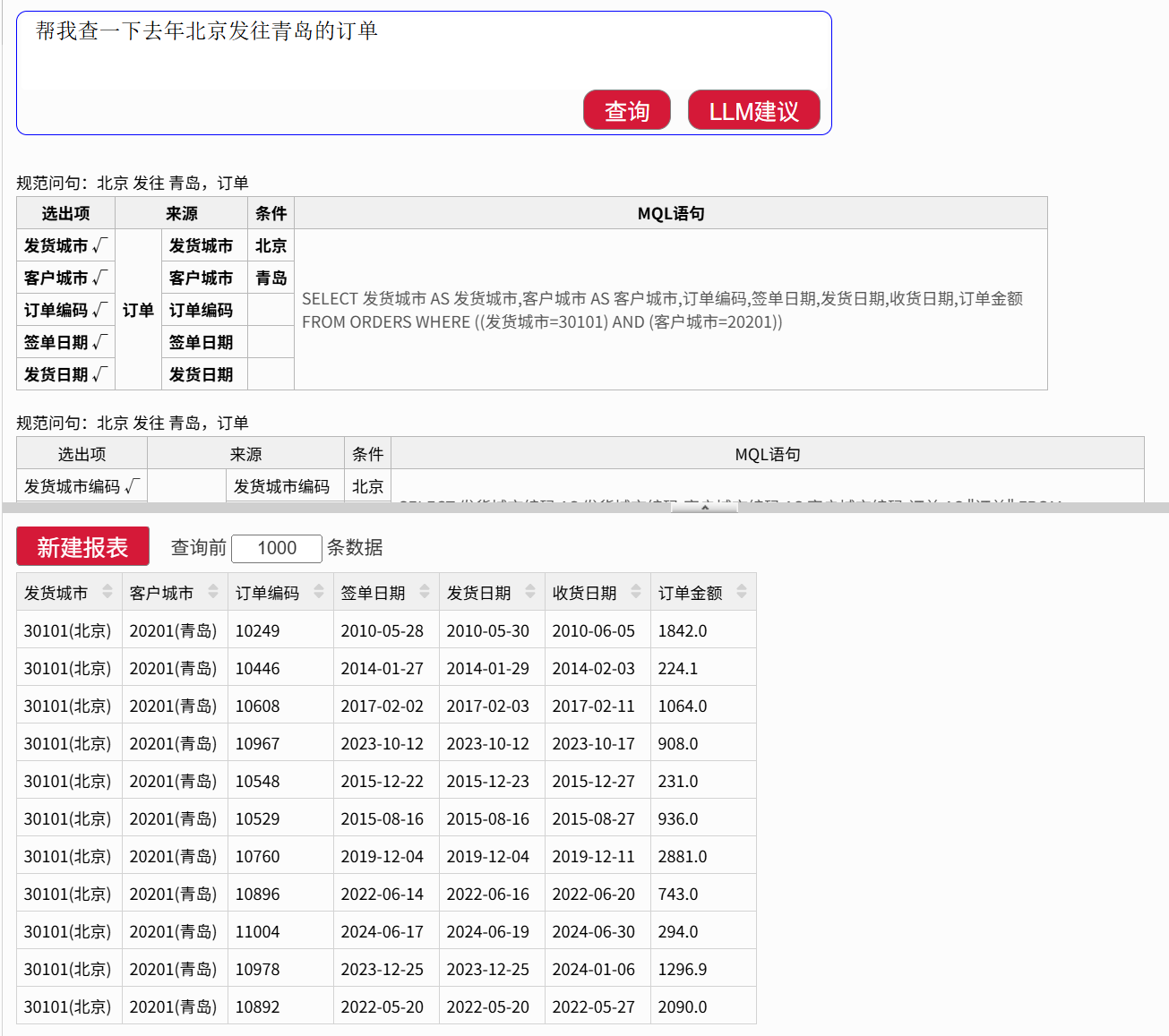
完整的查询路径流程包括:
自然语言 → 规范文本 → MQL(模型查询语言) → DQL(关联查询语言) → SQL
详细的技术原理可参考: 万字长文解析 Text2SQL 破局,兼得灵活复杂准确
更重要的是,这套能力并不止于查询。获取数据后,用户可以用同样的自然语言方式继续对结果进行自助报表分析,实现从“取数”到“洞察”的全链条覆盖。
例如,在得到订单明细后,用户可以输入:
“表头 产品类别,订单金额求和” → 立即生成汇总表。
“金额 计算占比 命名为类别占比” → 系统新增占比列。
“在产品类别范围内 订单金额 降序排名 命名为供应商排名” → 系统在各类别内对供应商进行排名。
“饼图 分类 产品类别 系列 订单金额” → 系统自动绘制饼图。
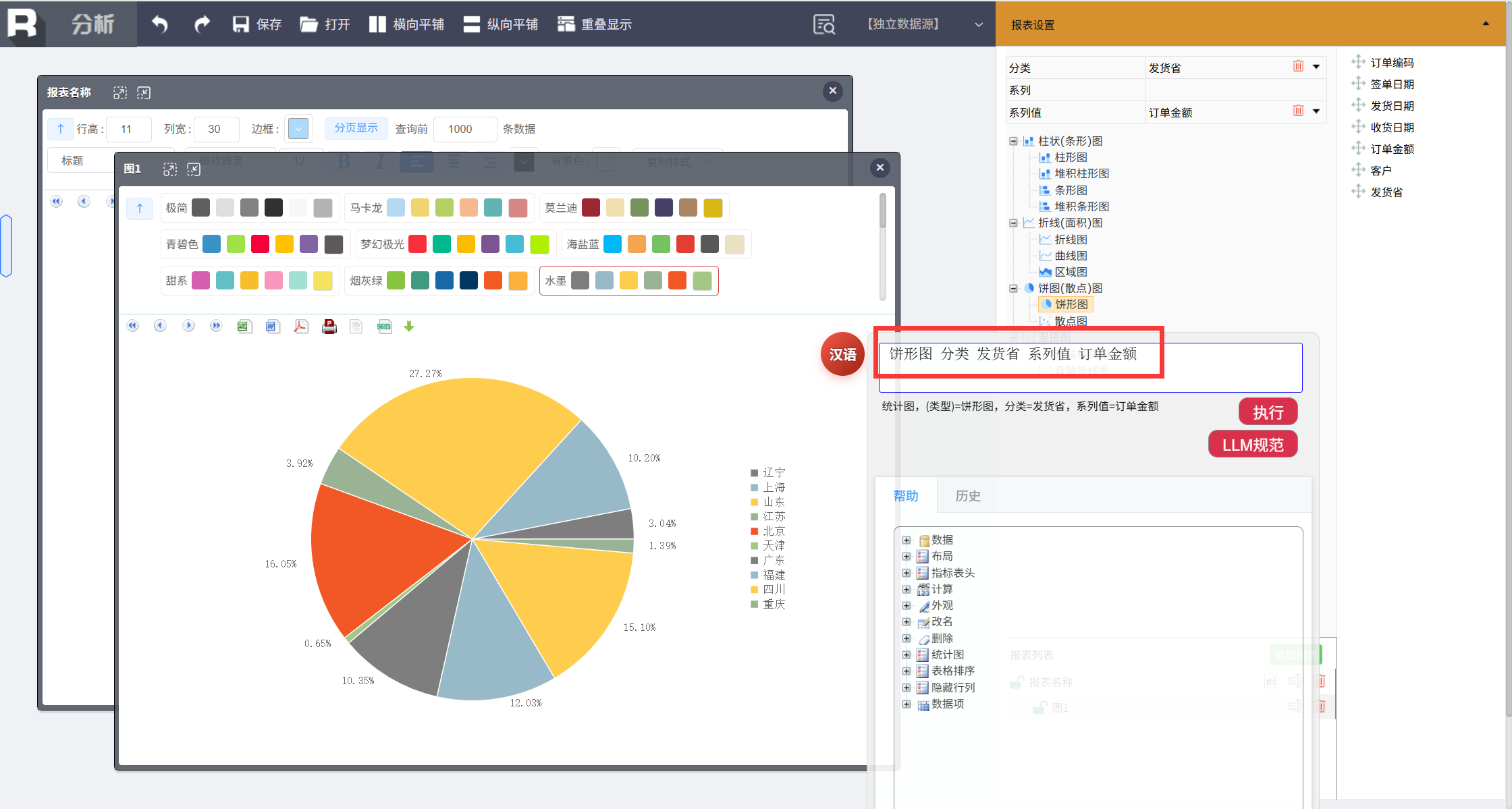
所有分析指令均由同一个规则引擎解析执行,结果确定、可解释,且无需任何拖拽操作。更多自助报表能力可参考: 全链 ChatBI 不止 Text2SQL,还有 Text 多维分析
这套嵌入式的做法,给软件厂商和最终用户带来几个实实在在的好处:
成本低,普通服务器就能跑:整个引擎完全依靠 CPU 运行,无需任何昂贵的 GPU 硬件,成本可比依赖大模型的方案降低 90% 以上。由于没有 Token 费用,长期使用成本透明可控。
结果确定,没有“幻觉”:系统执行基于明确的规则映射与逻辑,而非概率生成。只要“业务词典”配置正确,查询和分析结果就是 100% 准确的,从根本上建立了企业最需要的“数据可信度”。所有转换路径都可追溯、可解释,当业务逻辑变化时,只需修改词典配置即可完善。
私有化部署,数据安全:整个方案可完全部署在企业内部服务器,数据无需出域,满足中小企业在数据隐私和合规方面的要求。相比云端 LLM 方案,避免了数据外传风险。
低延迟,体验流畅:基于本地规则引擎的解析与计算,通常在毫秒级响应,用户从输入指令到获得结果都能获得即问即答的流畅体验。
实施门槛低,现有团队就能做:对软件厂商来说,核心技术工作并非高深的 AI 算法,而是由最懂自身产品业务逻辑和数据结构的工程师,进行“业务词典”的配置。这完全在现有技术团队的能力范围内,无需组建昂贵且稀缺的 AI 技术团队。
体验连贯,从问到分析一气呵成:该引擎的能力远超简单的查询。它实现了从“查询”到“分析”的全链条覆盖。用户在一次对话中,即可完成从数据提取、多维分组、计算衍生指标(如排名、环比)到可视化图表生成的全部操作,体验流畅而强大。
“规则引擎”与“公共 LLM”协同
规则引擎虽然又准又省,但如果用户问的是“帮我瞅瞅上个月卖得最火的是啥?”这种特别口语的表达,规则引擎可能直接理解不了。这时就需要大模型(LLM)来帮忙了。
在润乾 ChatBI 的架构中,公共 LLM 是一个重要的协同组件,扮演“智能翻译官”的角色。工作流程如下:
用户输入口语化问题。
公共 LLM 在简单的提示词引导下,将其“翻译”成规则引擎能理解的规范指令,比如:“过滤:时间为上月;聚合:按产品汇总订单金额;排序:金额降序”。
规则引擎接到这条清晰指令后,执行确定的查询逻辑,保证结果准确。
系统把数据结果连同翻译后的指令一起返回给用户。
这样做的好处很明显:
既灵活又可靠:用户可以用最自然的话提问,享受大模型的便利;核心查询则由规则引擎确保 100% 准确。
中间结果是“人话”,可确认可修改:LLM 输出的规范指令是用户能看懂的自然语言,而非难以验证的 JSON 或 SQL。用户可以在执行前确认指令是否正确,发现不对立即纠正,极大降低了幻觉风险。因为 LLM 只需完成“从口语到书面语”的转换,这是它的母语强项,出错概率远低于直接生成代码。
成本可控、风险透明:只有遇到特别口语化的句子时才调用按次收费的 LLM 接口,大部分查询走本地引擎,整体成本很低。即使 LLM 翻译偶尔有偏差,也能通过中间指令立刻发现和修正。而且这种简单的文字重组任务,用一个私有化部署的小参数模型就能胜任,进一步降低了对 LLM 的依赖。
软件厂商容易上手:只需要编写简单的提示词模板来引导大模型,普通开发人员就能完成,完全不用碰模型训练、微调那些复杂技术。
目前,自助报表部分的 LLM 规范能力也已增加,支持用户用口语发出分析指令(如“把销售额最高的几个产品用红色标出来”),系统自动转换为规范的分析命令,扩展了 LLM 在分析阶段的辅助作用。
未来展望:一步生成查询 + 报表的综合能力
在即将推出的下一版本中,我们将更进一步,实现真正的“综合能力”。届时,系统不仅能处理规范的查询和分析指令,还能应对更模糊的任务指令。例如,用户可以说“分析一下上个月的销售情况”,系统将自动分解任务:
首先,利用 LLM 理解意图,生成规范的自然语言查询(如“查询上个月的订单数据,返回订单金额、产品类别、省份”),由规则引擎执行获取基础数据。
然后,基于预定义的规则或简单的指令理解,自动匹配合适的分析动作和图表类型(如按产品类别分组汇总、生成趋势图、计算环比),由规则引擎完成分析并呈现。
这种能力的核心优势,依然建立在我们当前方案的基础上:中间环节的可读性和可干预性。无论是 LLM 对模糊任务的分解,还是系统推荐的报表动作,其过程和中间结果都可以被用户理解和调整。用户可以看到系统打算做什么,并在必要时修正,确保最终结果符合预期。这进一步放大了我们方案的优势——在拥抱 AI 灵活性的同时,牢牢把握住决策的“可解释”和“可控”的底线。
给应用软件厂商的实施蓝图
总结来说,以规则引擎为核心的 ChatBI 方案,真正在成本、准确性和实施难度上,为中小企业提供了可行的智能数据查询与分析能力。对广大应用软件厂商来说,这不仅是技术升级,更是一个清晰的产品战略机会,为自己的软件嵌入“智能问数”功能,在竞争中打造差异化优势。
具体实施方案清晰可落地:
能力内嵌,不是另建系统:与润乾这类技术方合作,通过 SDK 或 API,把 ChatBI 引擎作为标准模块,轻量集成到自己的 ERP、MIS、CRM 等系统里。用户不用部署新平台,而是在原来熟悉的界面里多一个“智能数据助手”。
配置知识,封装业务逻辑:由最懂自家产品业务和数据结构的工程师,完成“业务词典”的配置。这相当于把软件里的业务知识(比如“订单”“客户”“库存周转率”对应哪些数据库字段,以及“排名”“环比”等分析动作的含义)一次性数字化。配一次,所有客户都能复用。
场景赋能,提升用户体验:把“智能问数”功能以最自然的方式(比如侧边栏聊天框、报表页的提问入口)融入产品界面。让企业用户在不离开工作流程的情况下,随口一问就能获得数据支持,并进一步探索分析,显著提升软件黏性和价值。
ChatBI 的真正价值,就是让数据查询与分析像聊天一样简单、可靠、用得起来。以规则引擎为核心的务实路径,已经为此铺平了道路。现在,工具和方案都已就绪。对软件厂商而言,为产品增加“智能问数”能力,不再是一个技术难题,而是一个明确的产品竞争力选择。谁先帮助中小企业的业务系统“开口说话”,谁就能赢得这片广阔的主战场。

