


全链ChatBI不止Text2SQL,还有Text多维分析
如今,“用大白话分析数据”成了 BI 领域的热门趋势。但市面上许多“chatBI”方案,能力往往止步于 Text2SQL——也就是听懂一句话、查出一张表。比如你说“展示华东区上季度销售”,它能返回数据,这当然有用,可真正的分析才刚刚开始:怎么算增长、怎么排名次、怎么看趋势……这些关键步骤,依然需要回到传统界面去拖拽设置。
为什么会这样?
因为,对大多数基于 LLM 的 ChatBI 方案而言,Text2SQL 的准确性尚未解决,还顾不上琢磨后半截。面对业务场景中的语义歧义、行业特定用语以及复杂的数据模型关联,LLM 即使在注入领域知识后,仍可能生成看似合理实则错误的 SQL,存在难以完全避免的“幻觉”现象。因此,许多方案将首要资源集中于提升查询环节的可靠性,而尚未稳健地覆盖后续的分析交互。
而且,既使想做多维分析,也会发现无从下手。多维分析是个“动作序列,是一连串的交互操作:先按什么分组、再对什么汇总、如何排序、是否计算衍生指标……这些步骤之间存在逻辑依赖和状态传递,且高度依赖具体的 BI 工具上下文。但是,现实中缺乏大量公开、高质量、标准化的“BI 操作 - 自然语言”配对训练数据,以数据驱动的 LLM 方案也就难以可靠复现整个分析流程。因此,许多方案选择先攻克相对明确的“查询”环节,而将更复杂的分析交互留给用户手动完成。
润乾 BI 选择了一条更为务实的路径。它基于已在 Text2SQL 场景中得到验证的润乾 NLQ 规则引擎( 万字长文解析 Text2SQL 破局,兼得灵活复杂准确 ),将“自然语言转精准操作”的能力,从数据查询无缝延伸至后续的多维分析阶段。这套机制不依赖概率生成“猜测”,而是依靠规则与语义库进行精准匹配,从而将用户的自然语言分析意图,“翻译”成一系列稳定、可执行的操作指令。这不仅从根本上杜绝了“幻觉”,确保了结果的确定性,也使得系统能够可靠地处理复杂的分析逻辑,实现了从“问数据”到“操作数据”的全链条自然语言交互。
这才是全链的 ChatBI。
润乾 BI 的自然语言分析模块,已覆盖数据呈现、计算、排序、格式化等关键环节。指令设计贴近业务直觉,响应迅速且结果确定。
现在,只需输入一句汉语指令,就能直接驱动报表变化。下面,让我们通过具体场景,抢先体验这种“说人话,做分析”的流畅感。
先从 NLQ(自然语言查询)开始,得到查询结果:
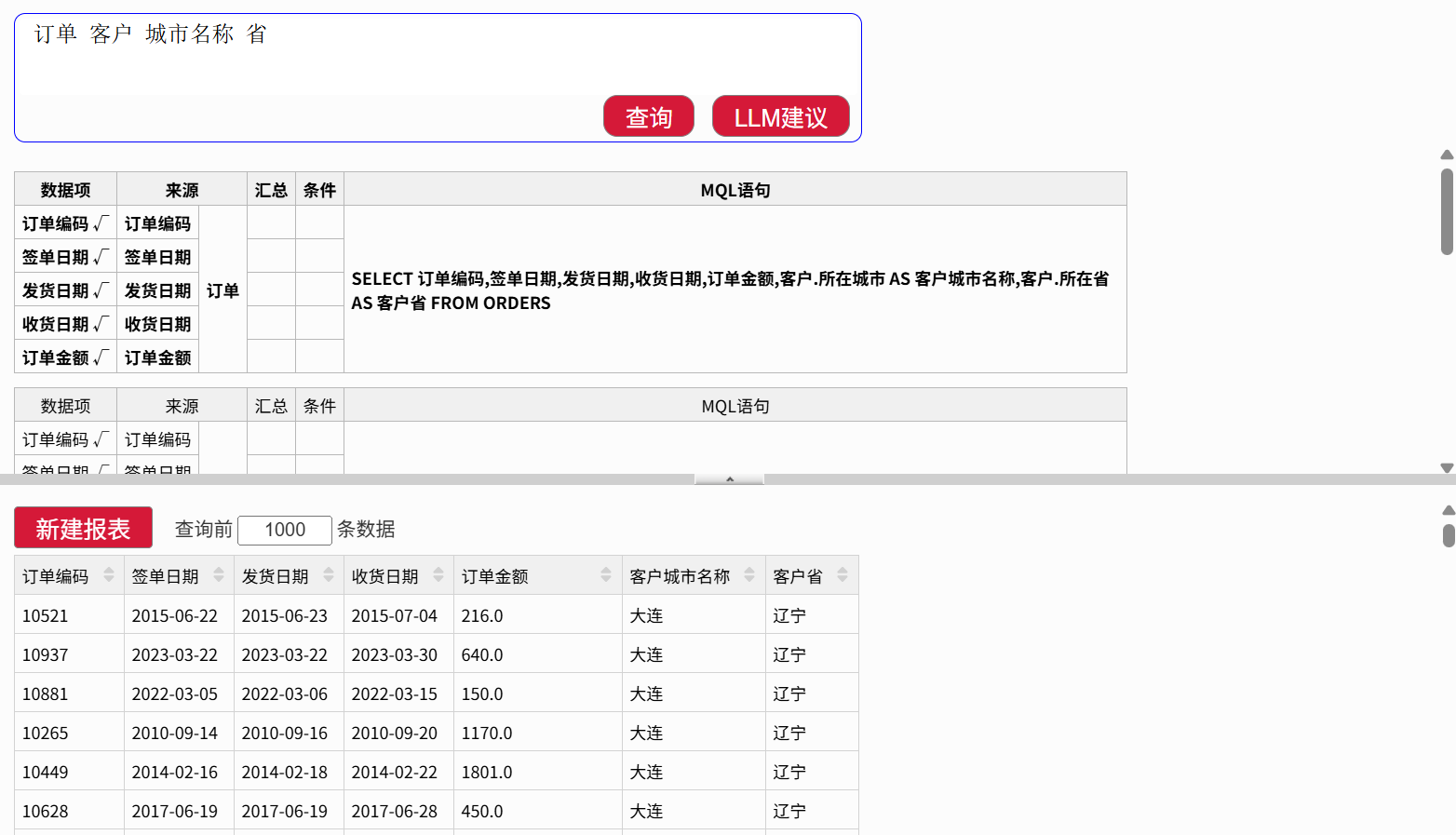
接下来针对这个结果做进一步分析,点击“新建报表”,进入多维分析界面:
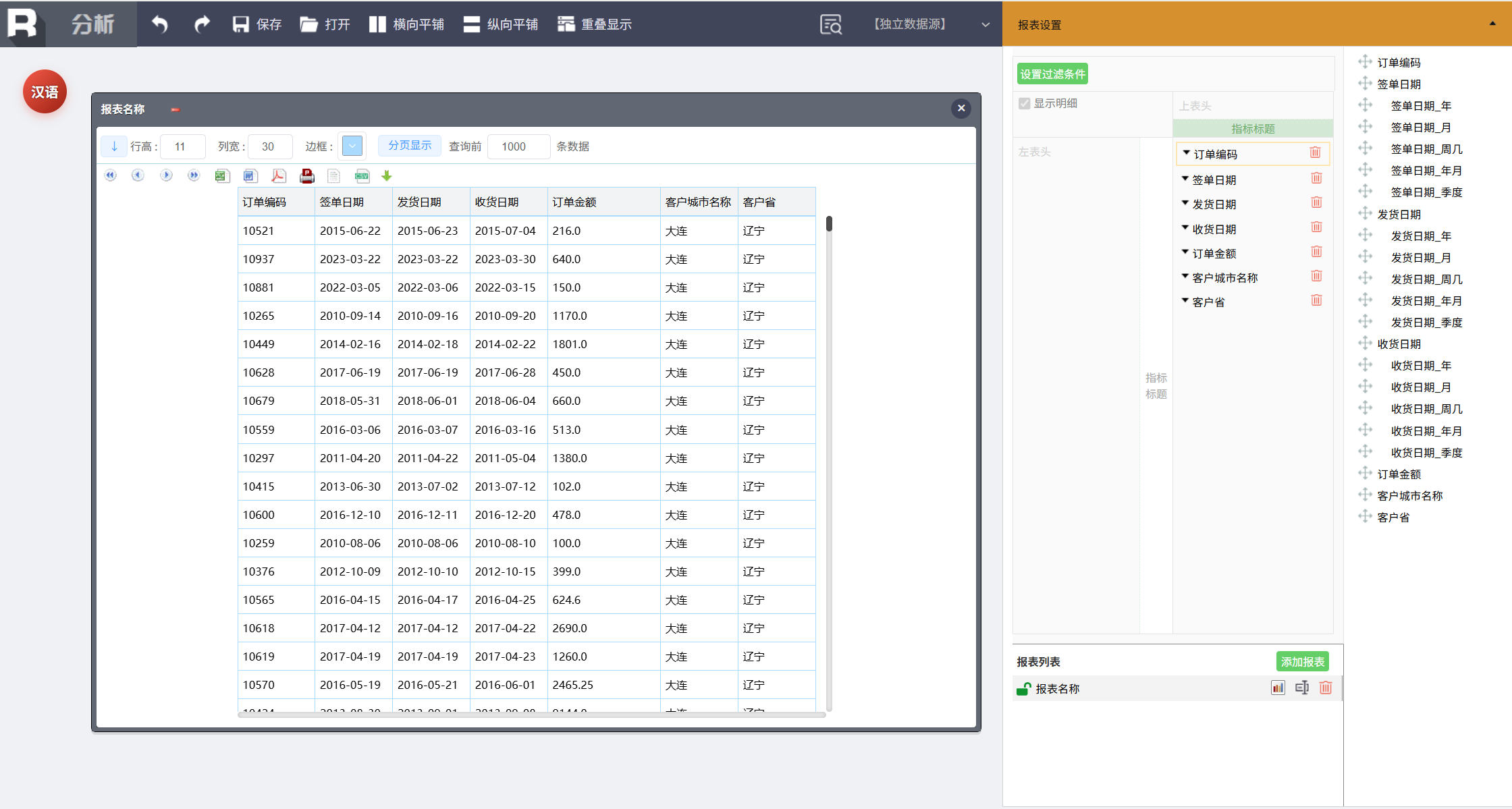
下面我们通过汉语命令来指挥数据分析工作。
【注】传统拖拽分析的方式仍然支持
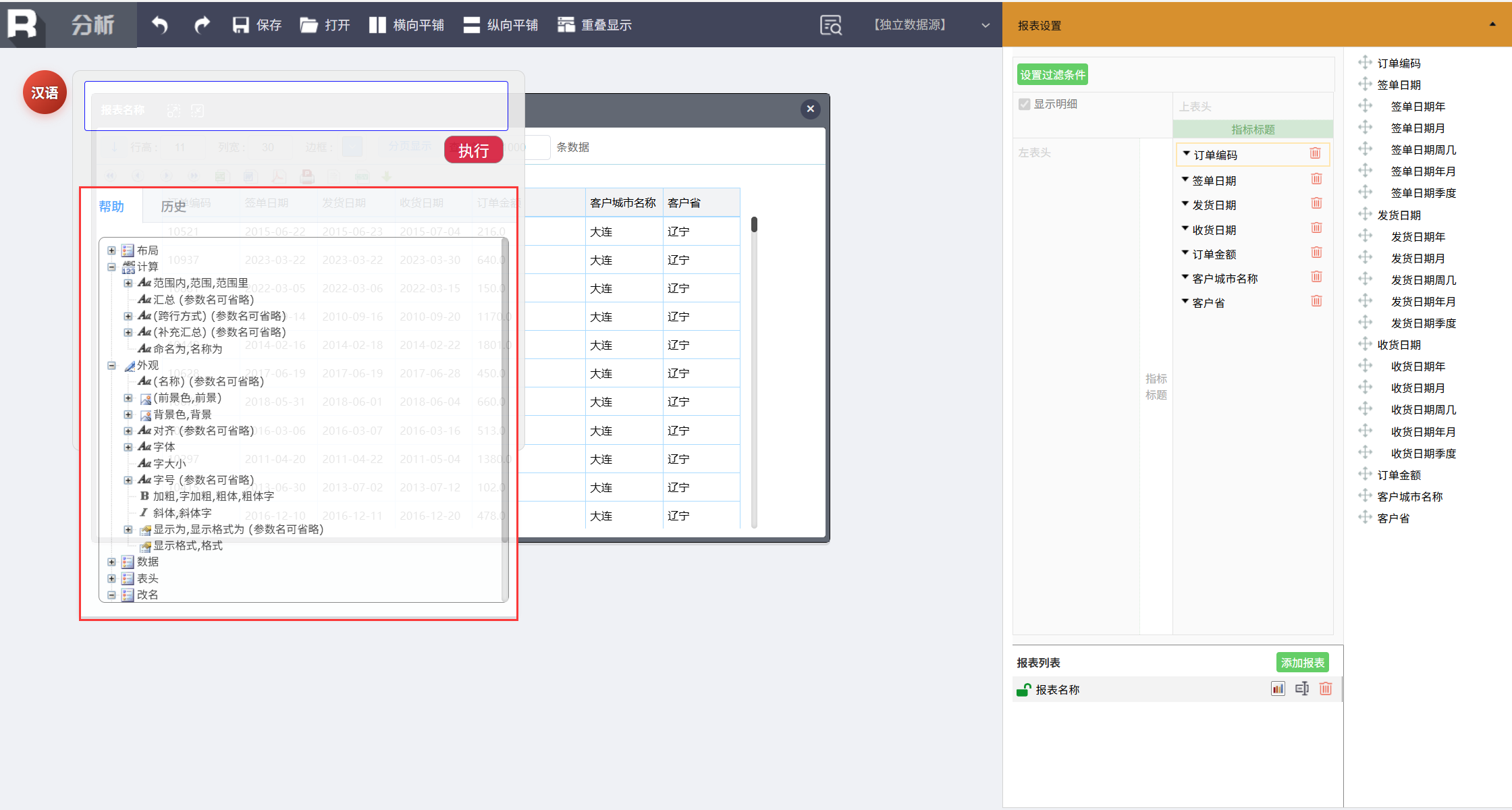
点击 按钮调出输入框,可以看到下面的帮助有很多丰富功能。
按钮调出输入框,可以看到下面的帮助有很多丰富功能。
生成分组报表
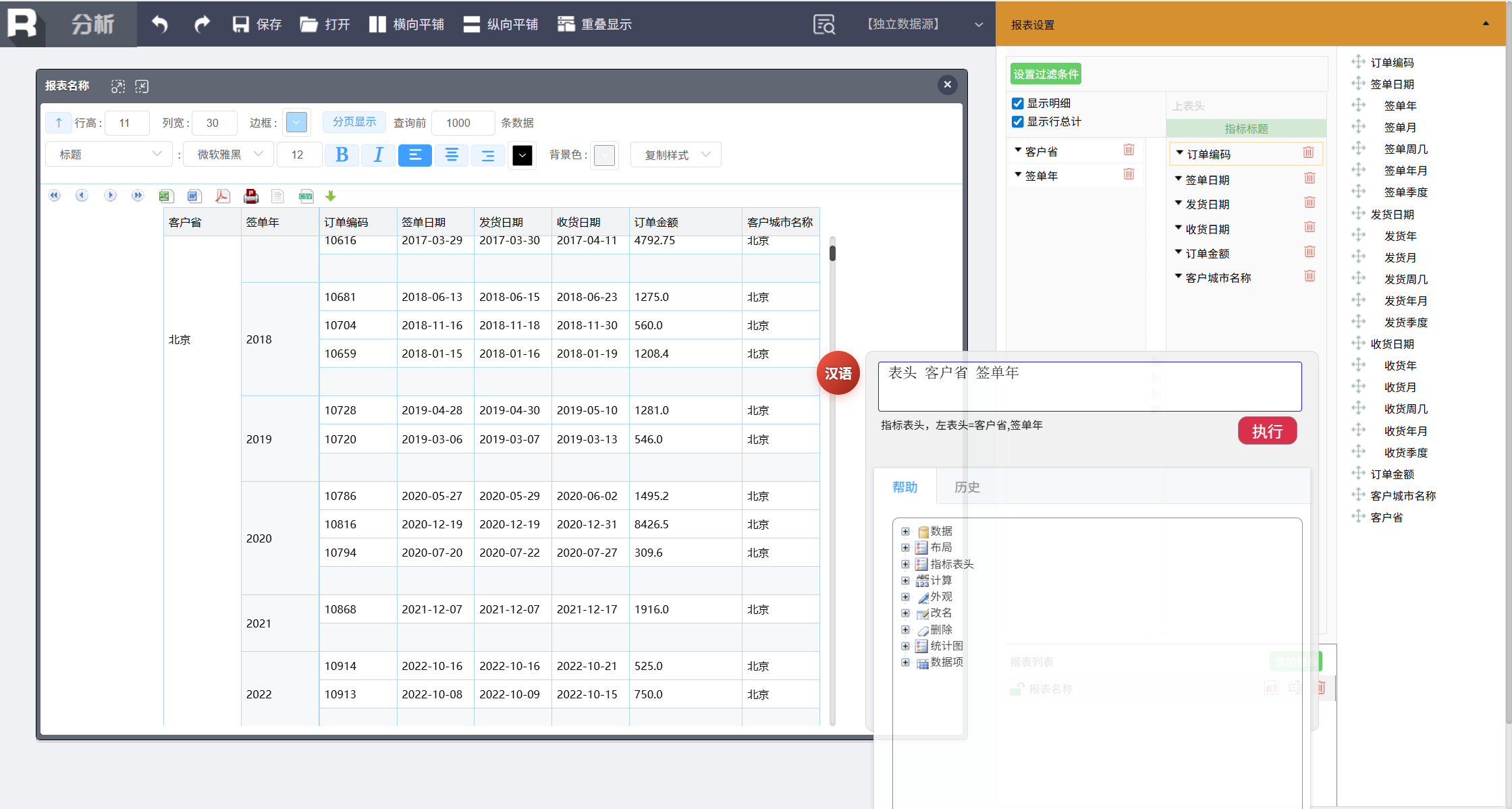
我们首先来生成一个分组报表(按省份和年份汇总订单金额)。在输入框中输入:
表头 客户省 签单年
点击执行,立即就得到了一张分组报表。
上面报表的指标部分不太符合我们预期,需要进一步调整,输入:
删除订单编码 签单日期 发货日期 收货日期 客户城市名称
将多余的列删除。
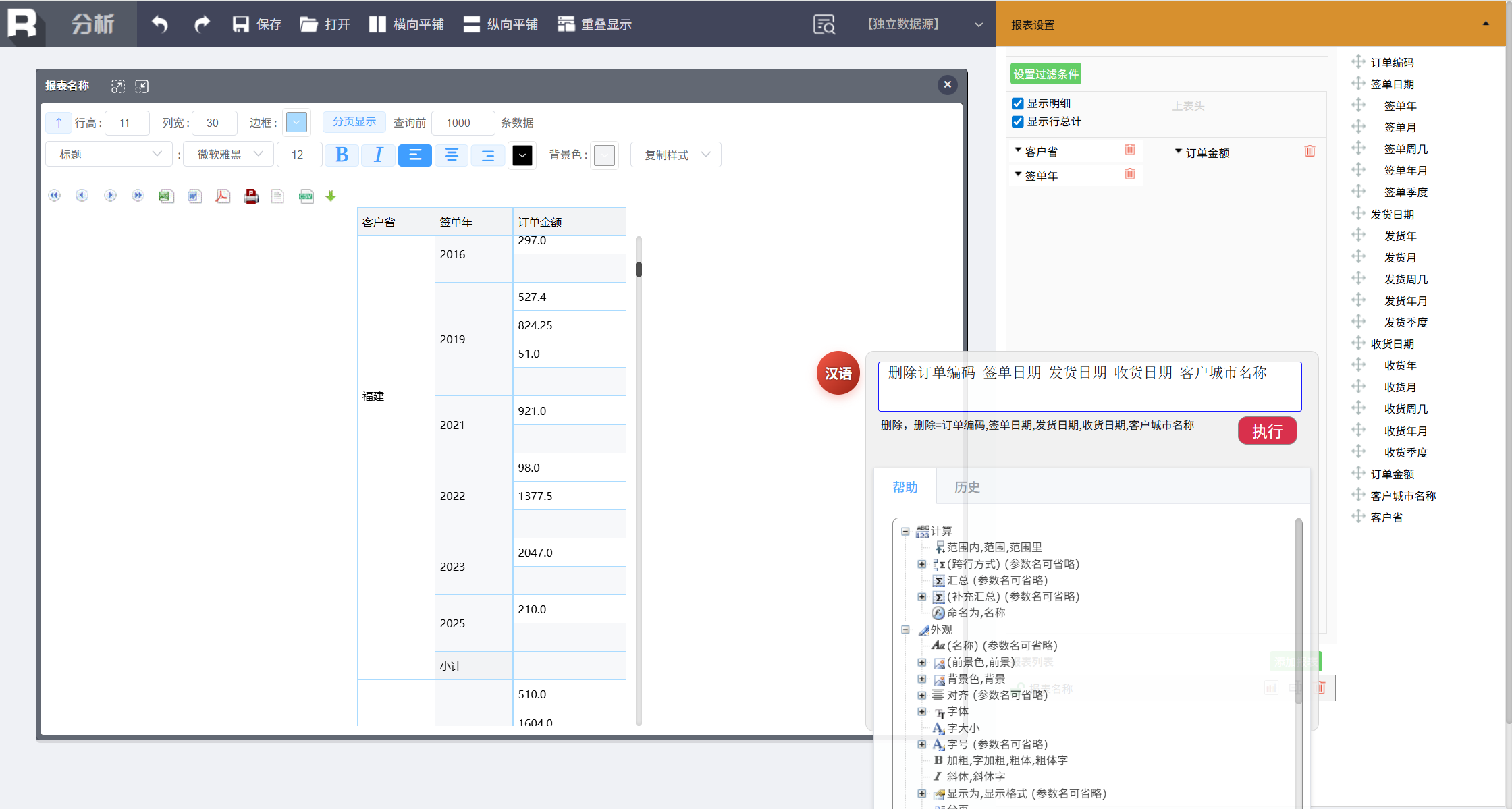
接着调整订单金额的汇总方式为求和,输入:
订单金额求和
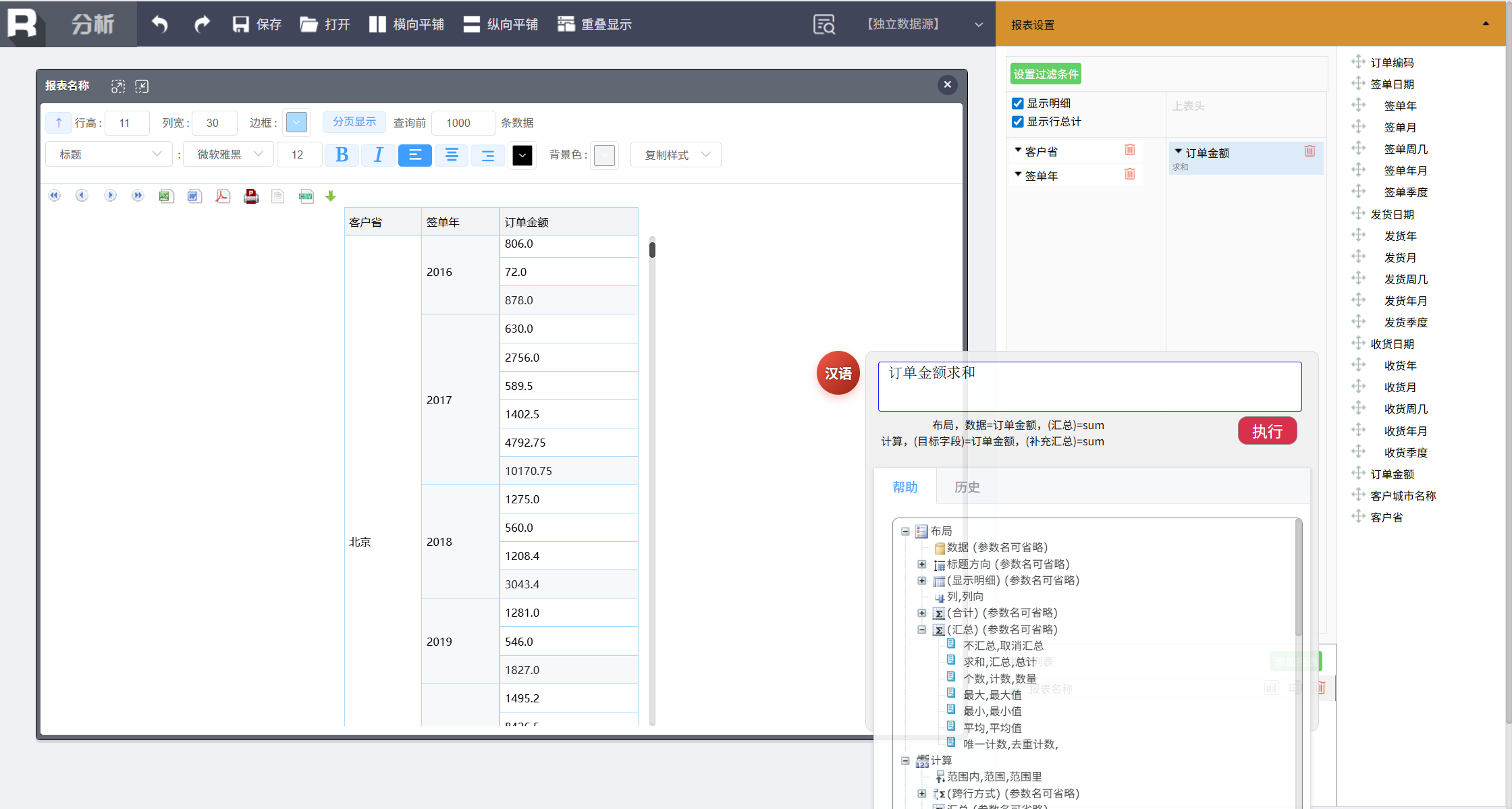
得到的分组报表默认会显示明细,可以通过命令隐藏掉。输入:
不显示明细
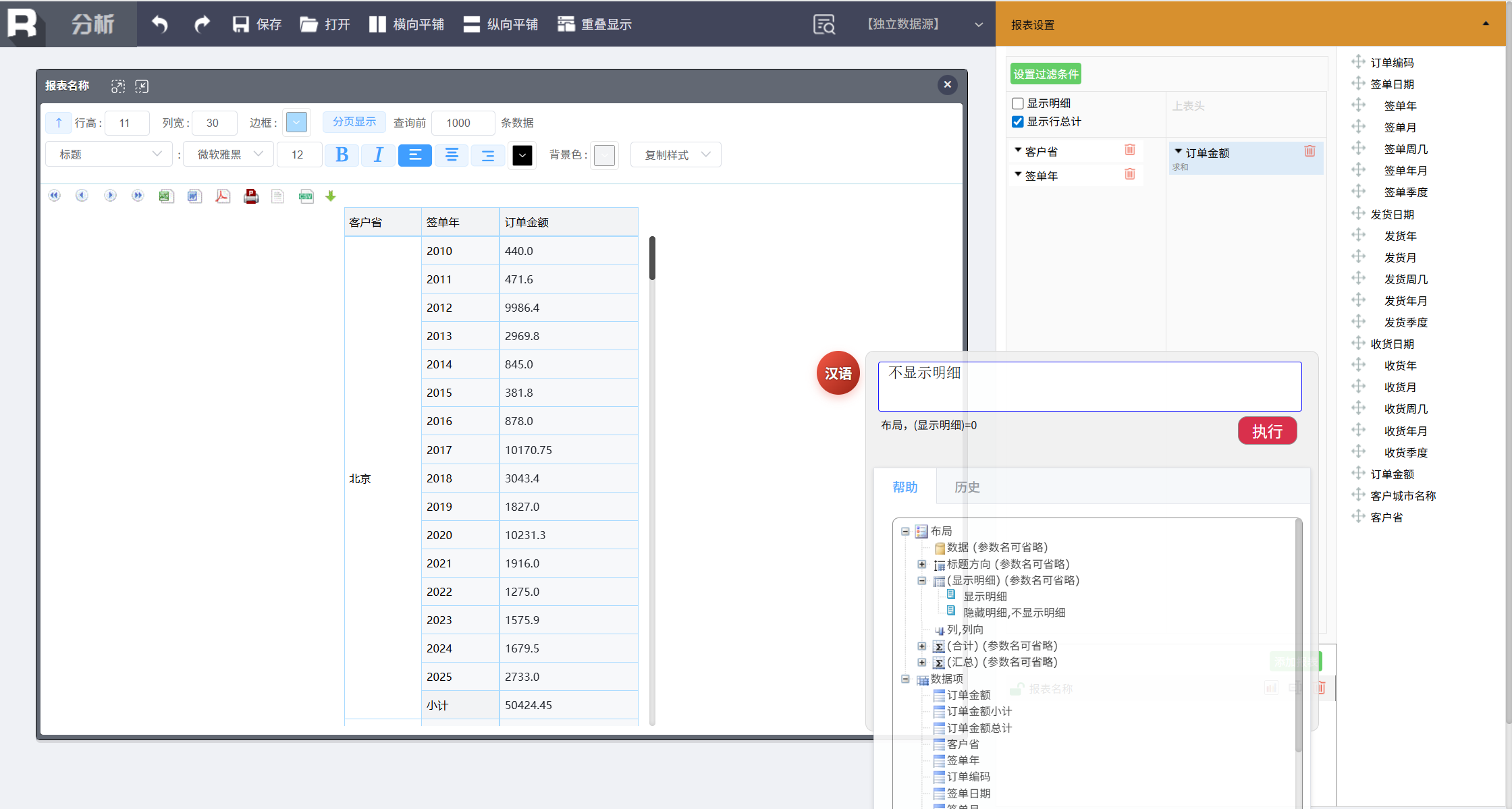
修改表头名称,分别执行两条命令:
客户省改为省份
签单年改为年份
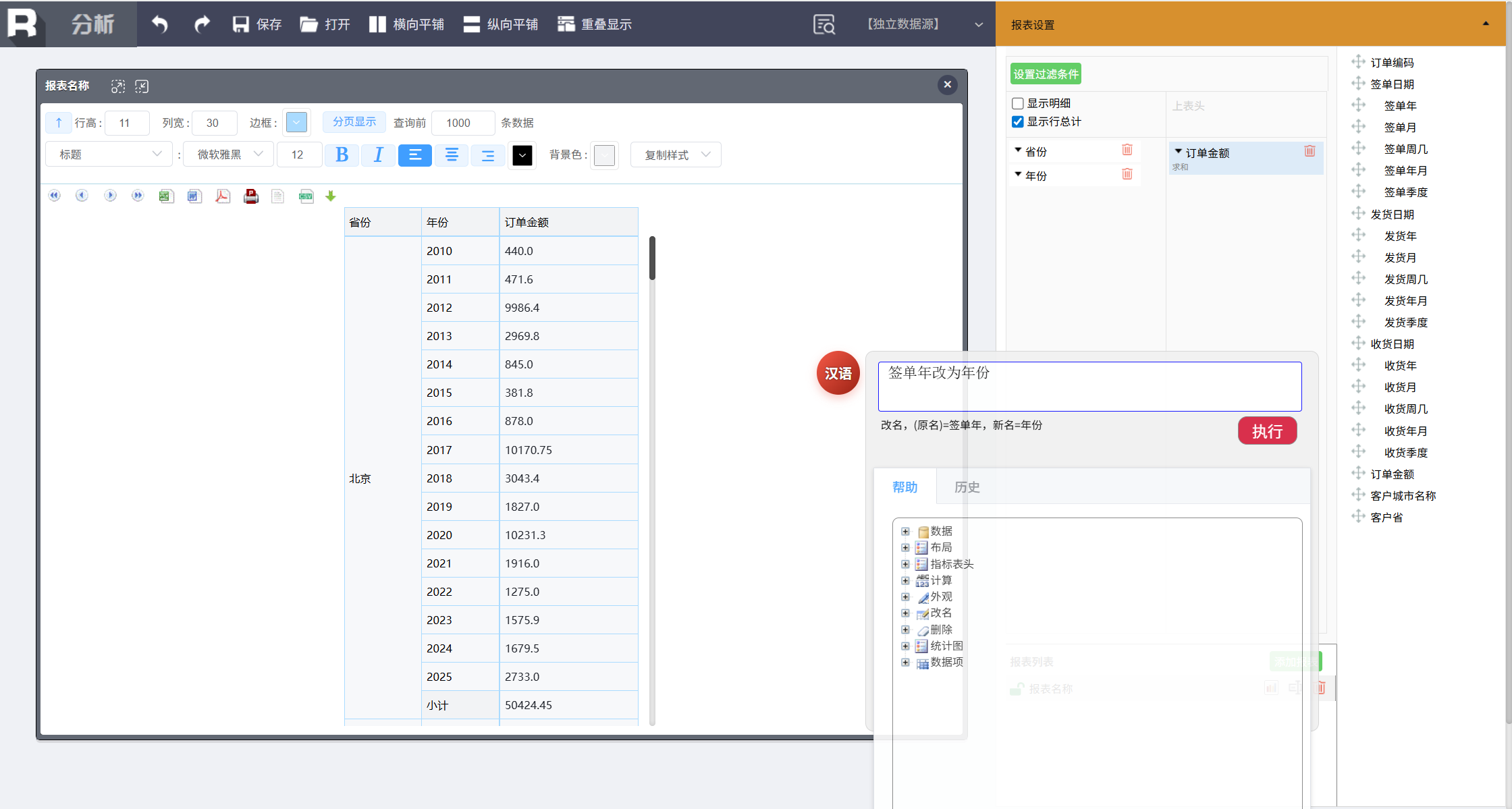
这样我们就得到了一张基于省份和年份分组汇总订单金额的汇总表。
排名
接下来使用命令做跨行组运算,这里想针对订单数量做排名:
订单金额 降序排名 命名为 “订单排名”
这里新命名的“订单排名”需要加引号,因为“排名”属于内置的关键词,如果不加引号会发生冲突。非关键词可以直接写,不用引号。
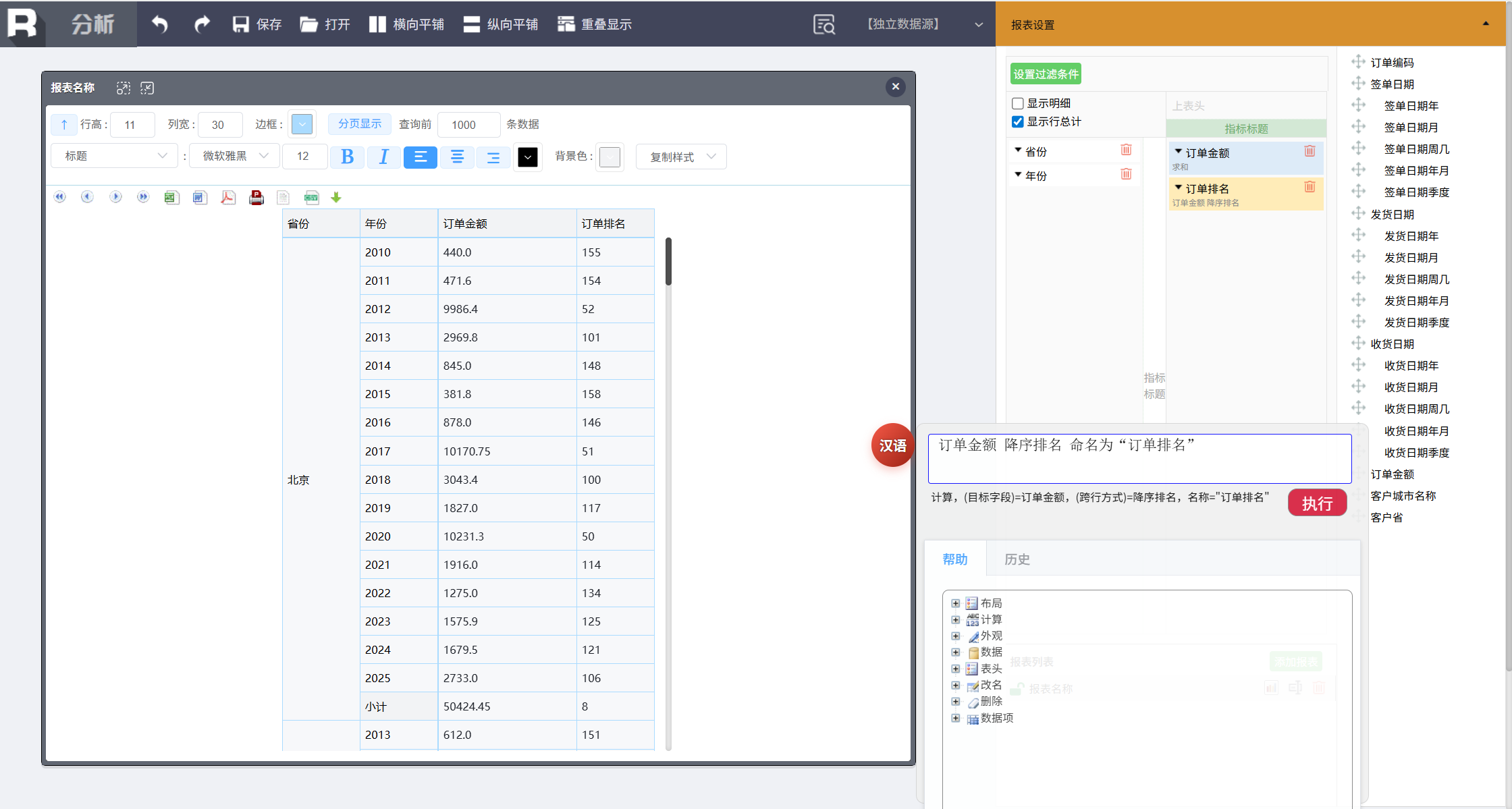
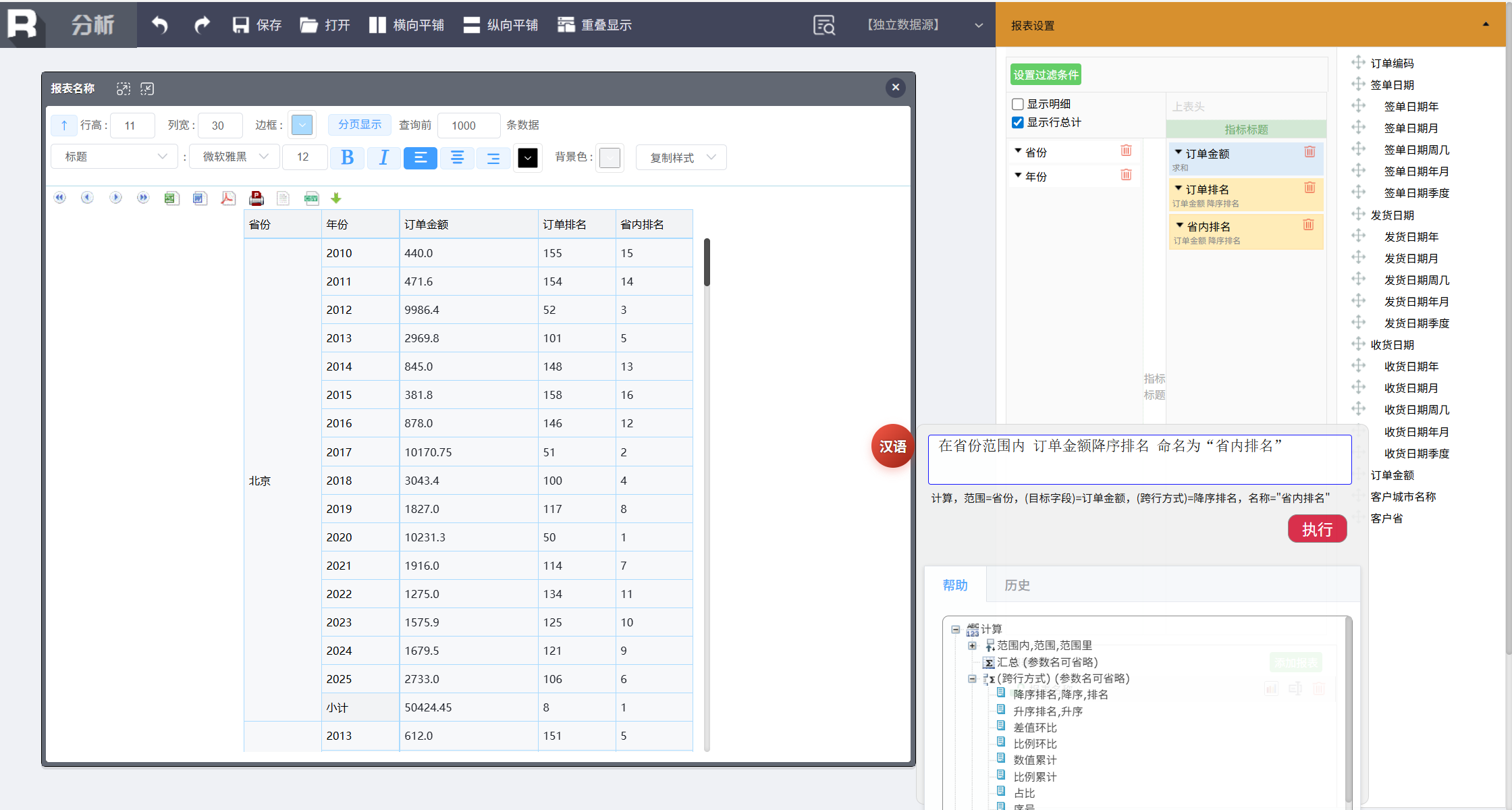
默认是针对所有行做的排名,还可以针对不同层次排名,比如想计算省内排名,输入:
在省份范围内 订单金额降序排名 命名为 “省内排名”
环比
使用命令还可以做很多其他跨行组运算,环比、同比、占比、累计、序号等。与排名类似,实现环比可以输入:
订单金额 比例环比 命名为 “环比”
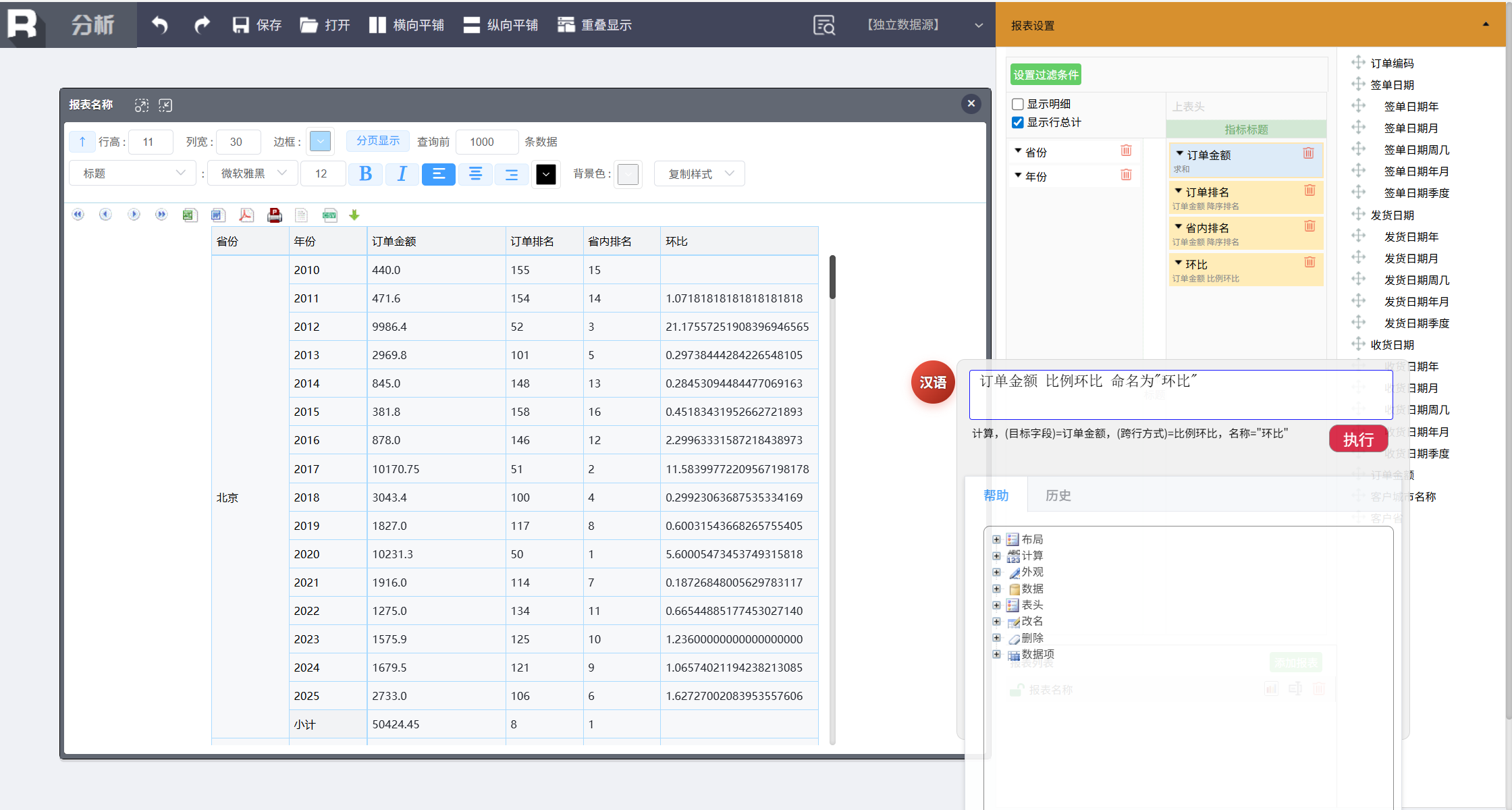
同样可以计算省内环比:
在省份范围内 订单金额 比例环比 命名为 “省内环比”
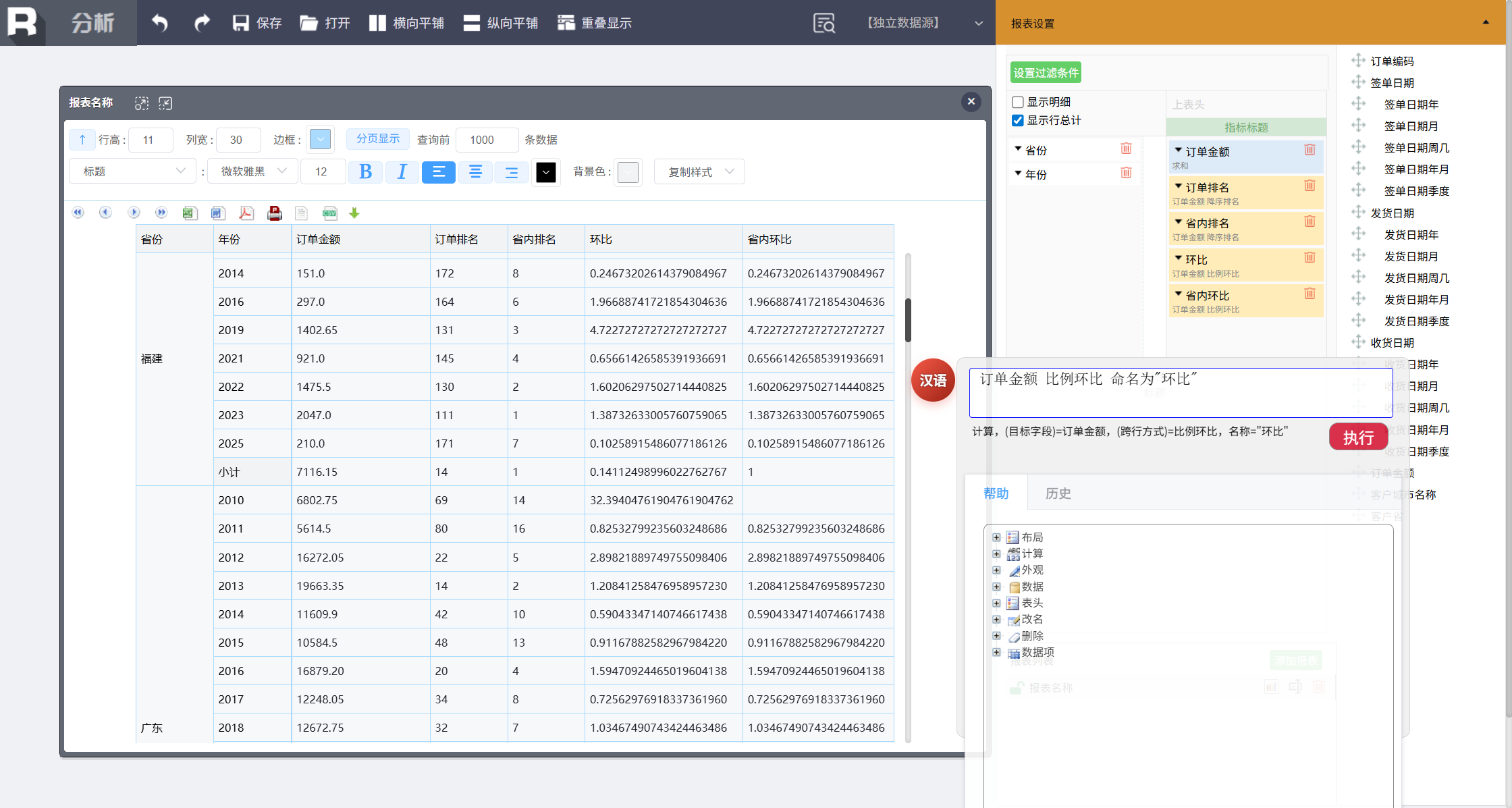
通过简单的命令轻松完成了复杂的跨行组运算。
外观控制
接下来要调整一下报表的外观。我们想把“订单金额”改为人民币显示格式,输入命令:
订单金额显示为货币格式
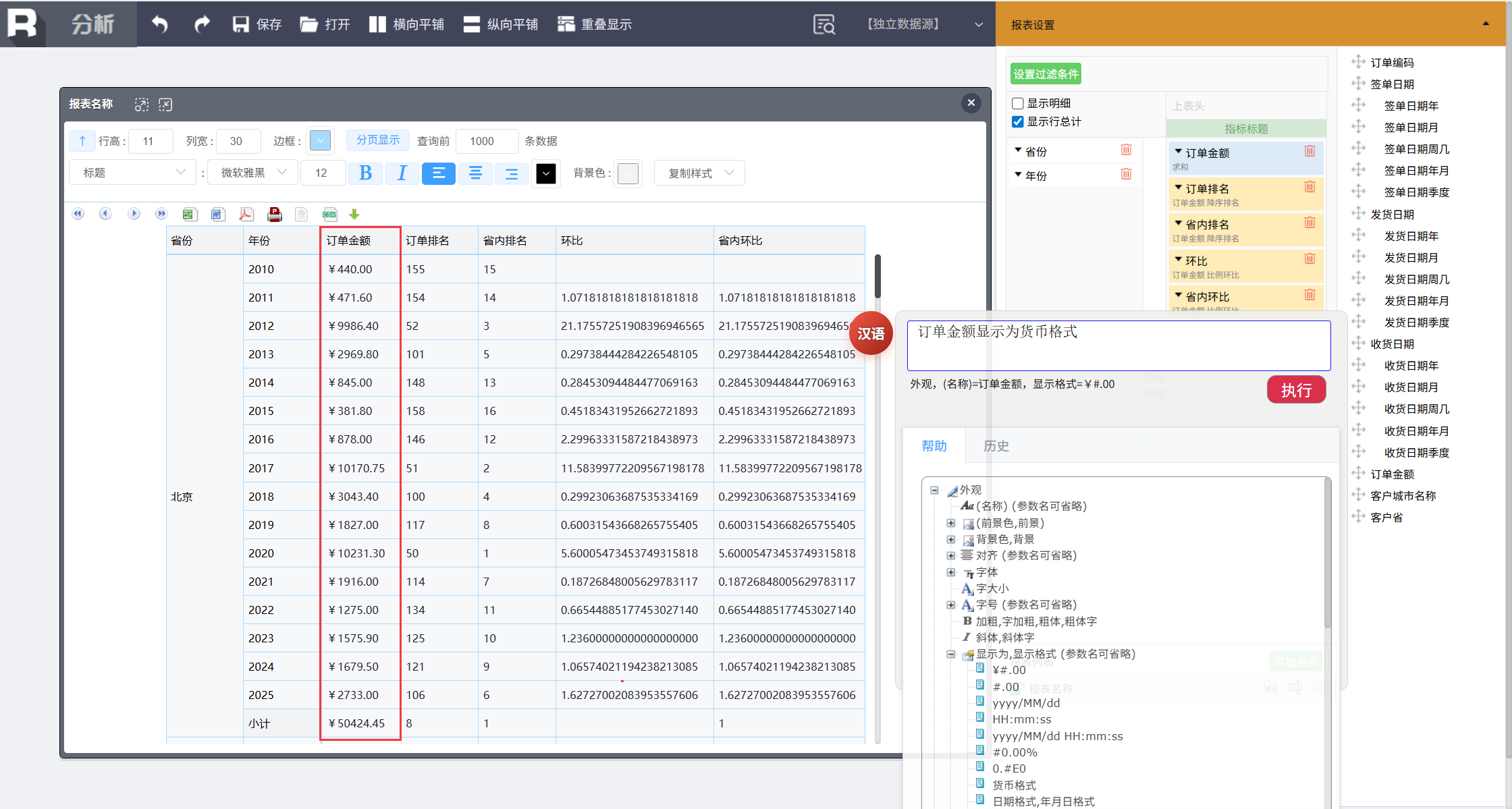
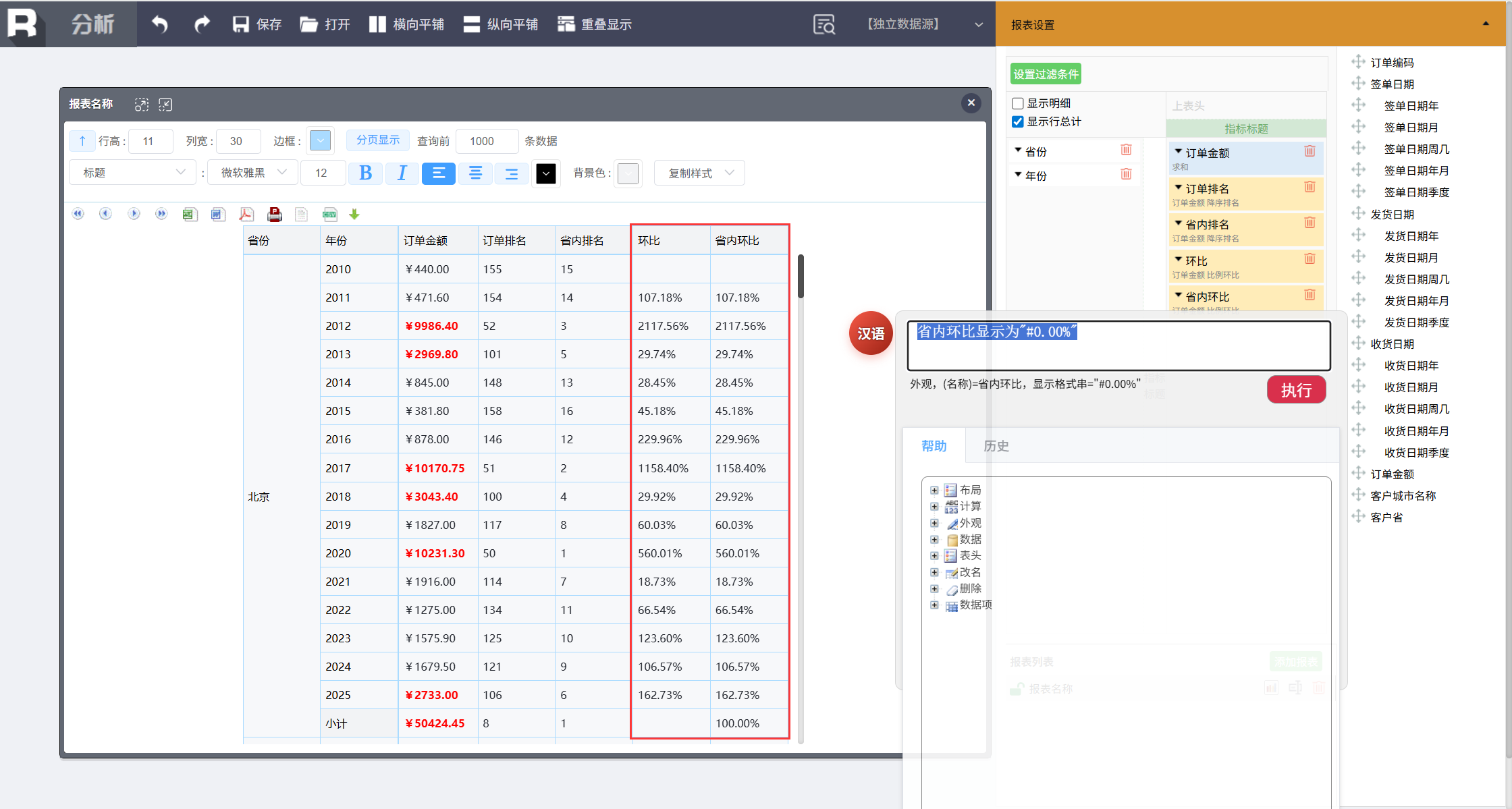
调整环比显示为百分比格式,输入:
省内环比显示为"#0.00%"
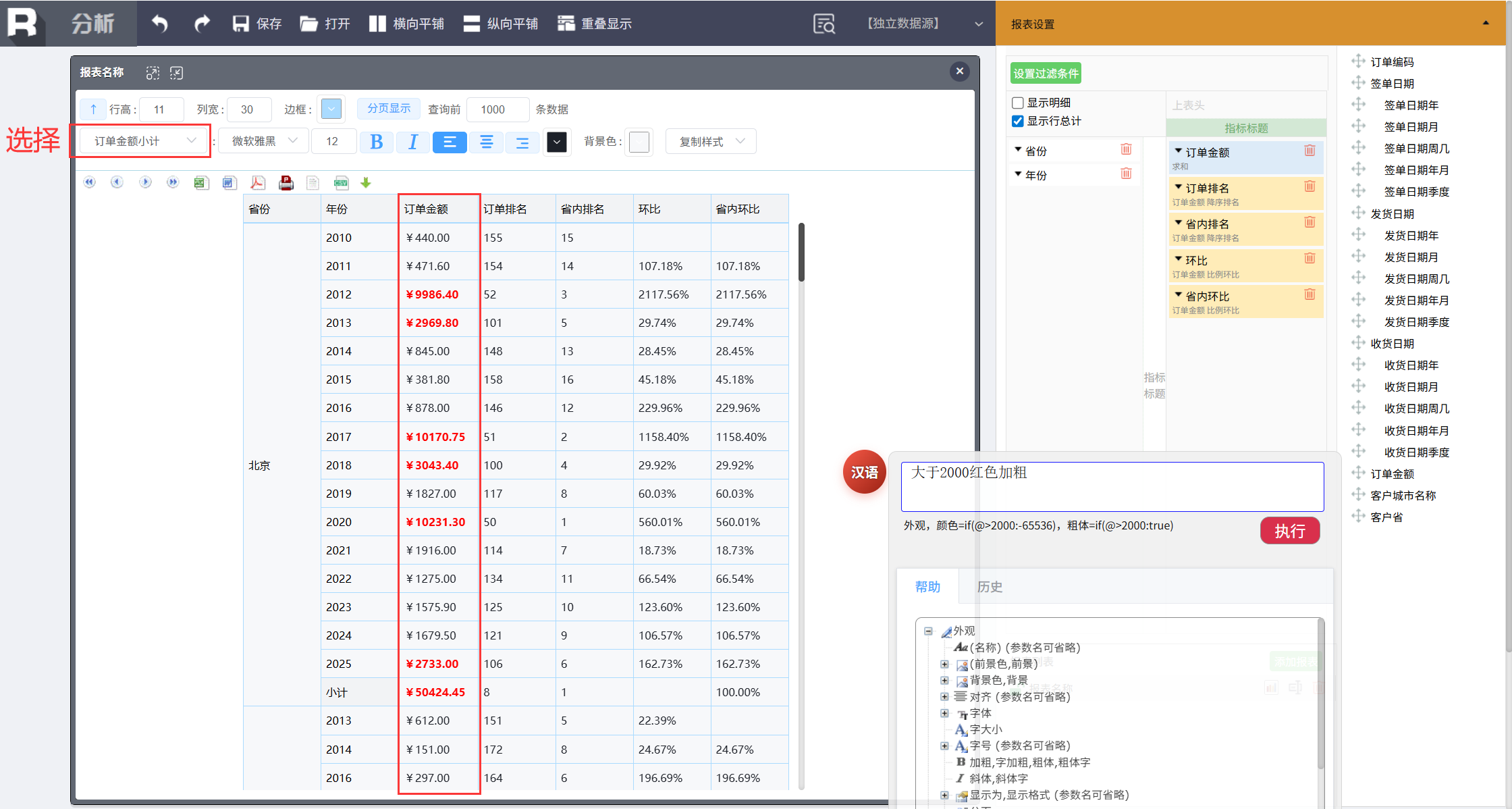
还想突出显示大于 2000 的订单金额小计为红色,在报表区域选中“订单金额小计”,让命令作用在订单金额列上,然后输入:
大于2000红色加粗
类似的,前景色、背景色、字体等属性都可以通过命令设置。
通过这个例子可以看到,润乾 BI 的 Chat 命令已经支持比较复杂的条件形式。
数据过滤
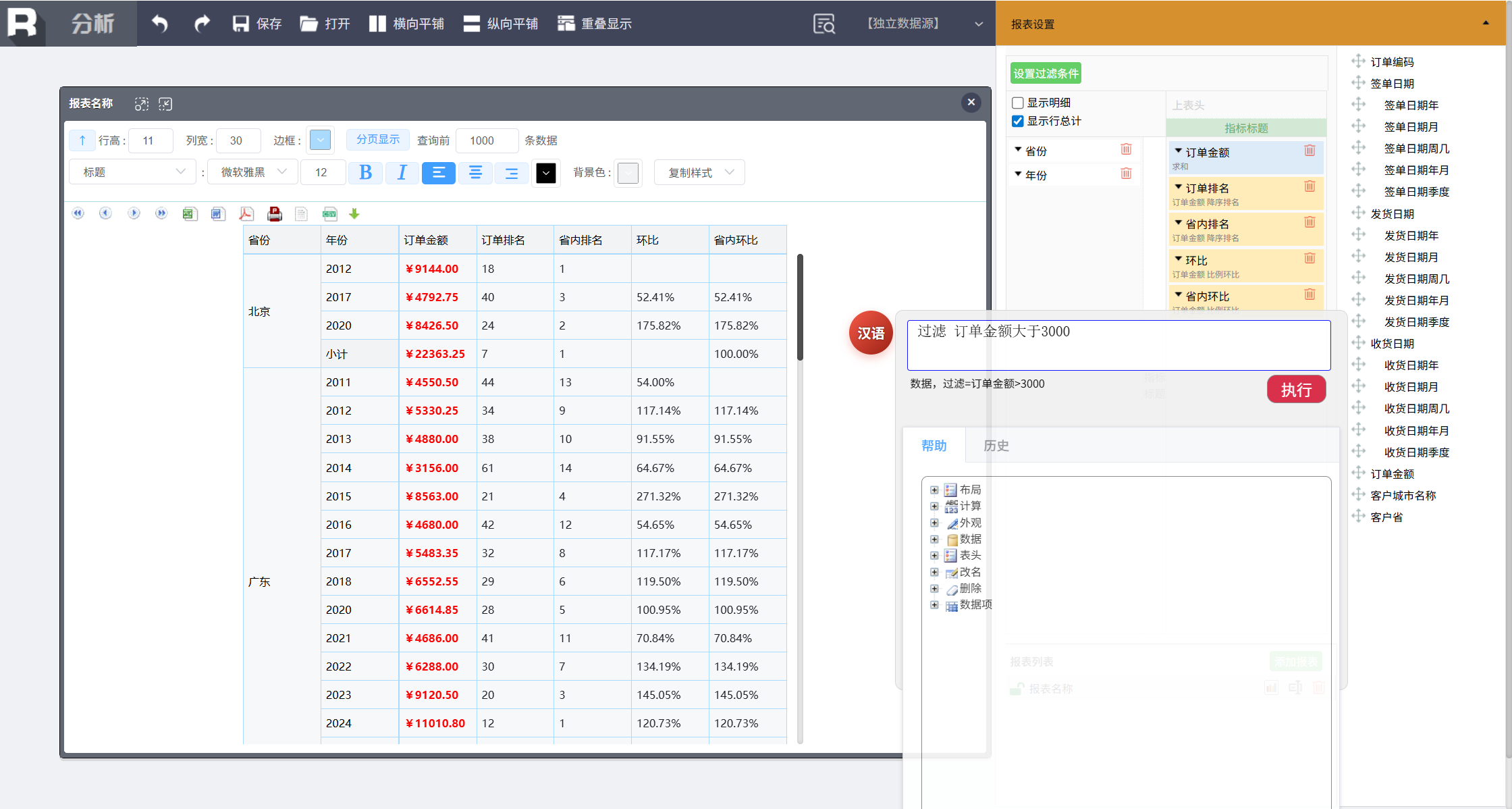
支持了条件形式,我们还可以做数据过滤,也就是多维分析中常见的切片 / 切块。过滤订单金额超过 3000 的命令:
过滤 订单金额大于3000
多个条件还可以组合使用, 比如:
过滤 订单金额大于1000 且 发货日期晚于2023年12月31日
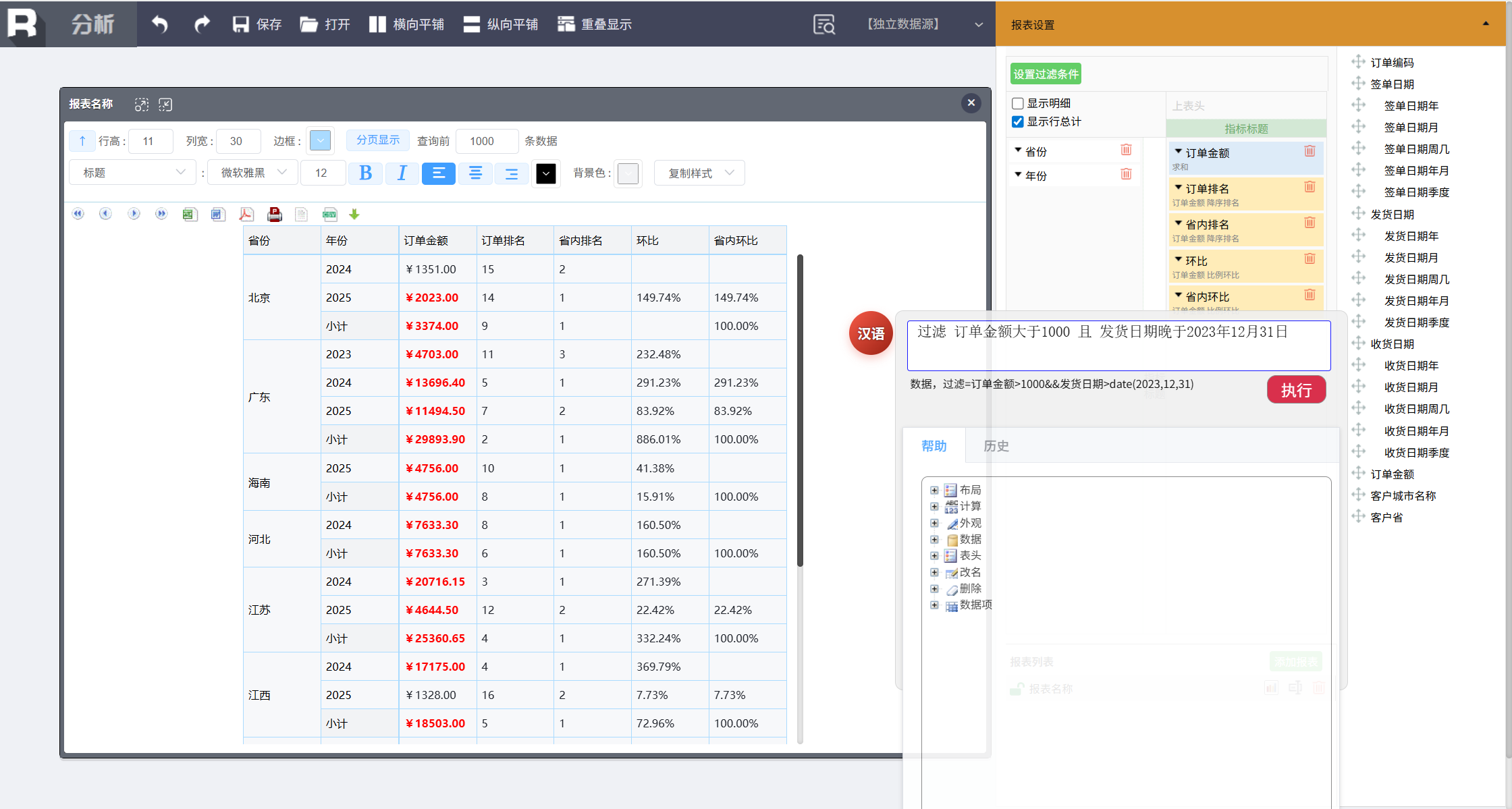
排序
对数据排序,输入:
排序 省份升序,年份降序
可以针对多列进行排序。
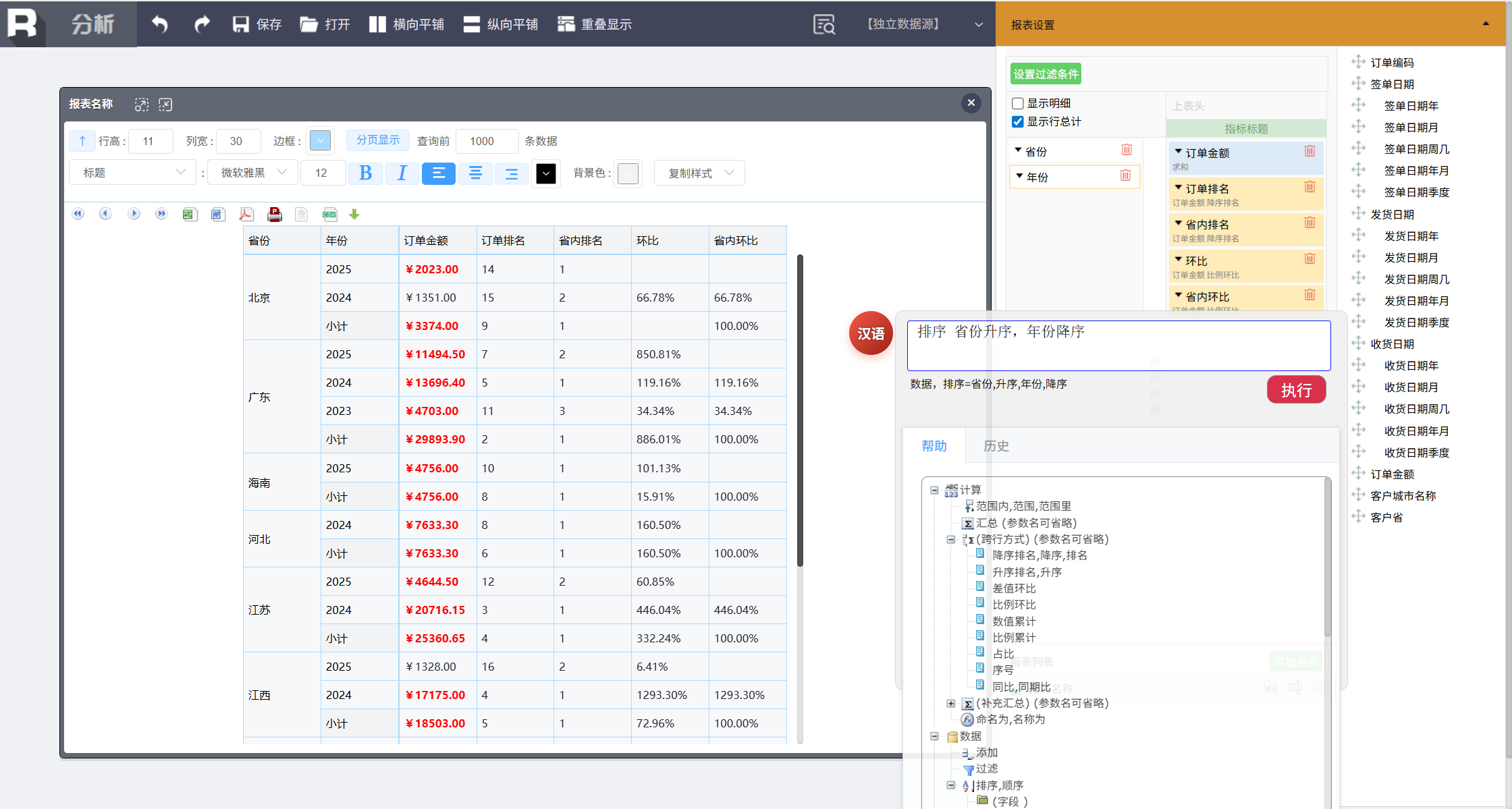
行列转换
多维分析的旋转操作也可以用命令完成,输入:
上表头 年份
把年份放到上表头,形成交叉表。
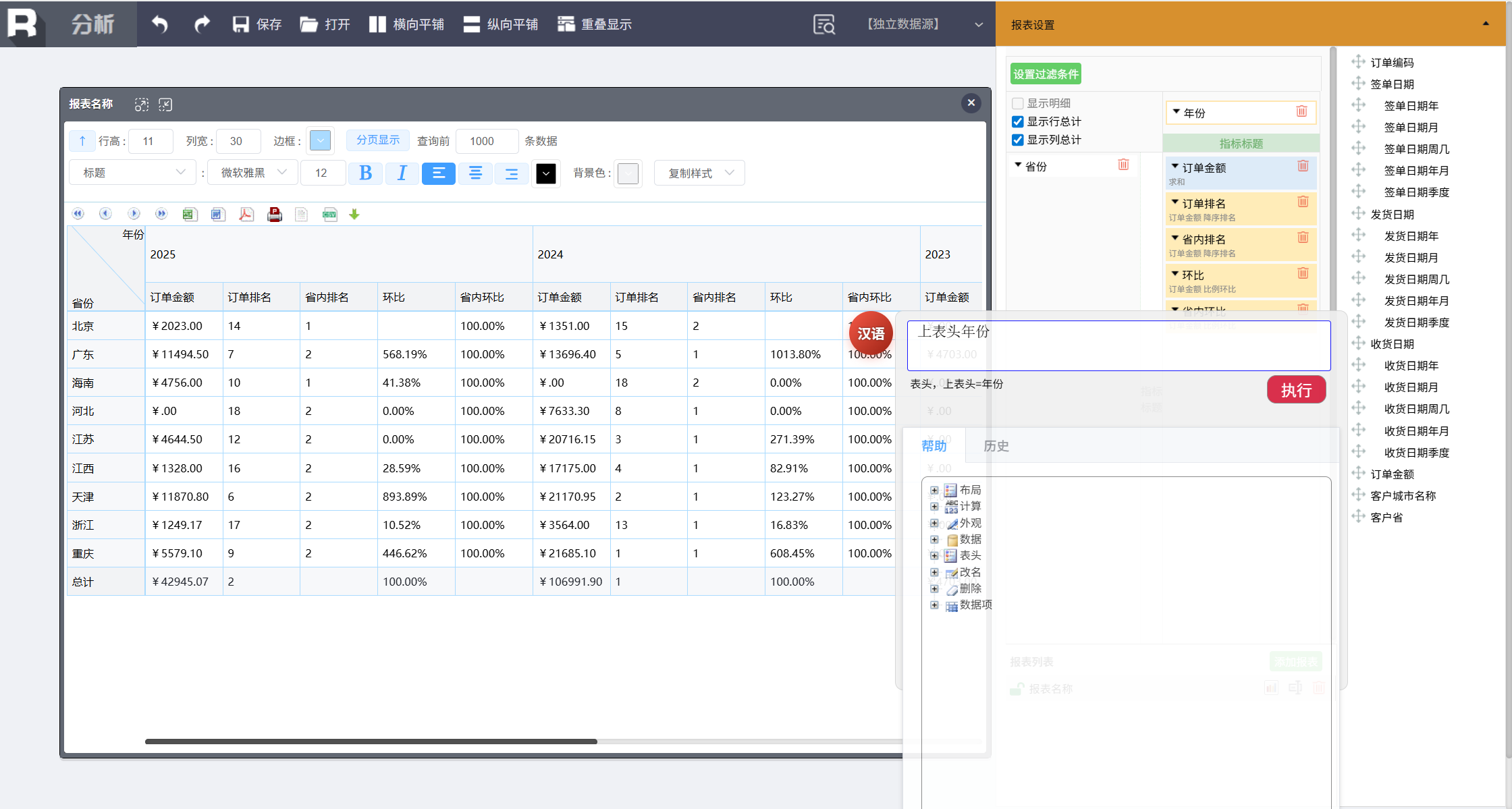
还可以进行行列互换,输入:
左表头年份,上表头省份
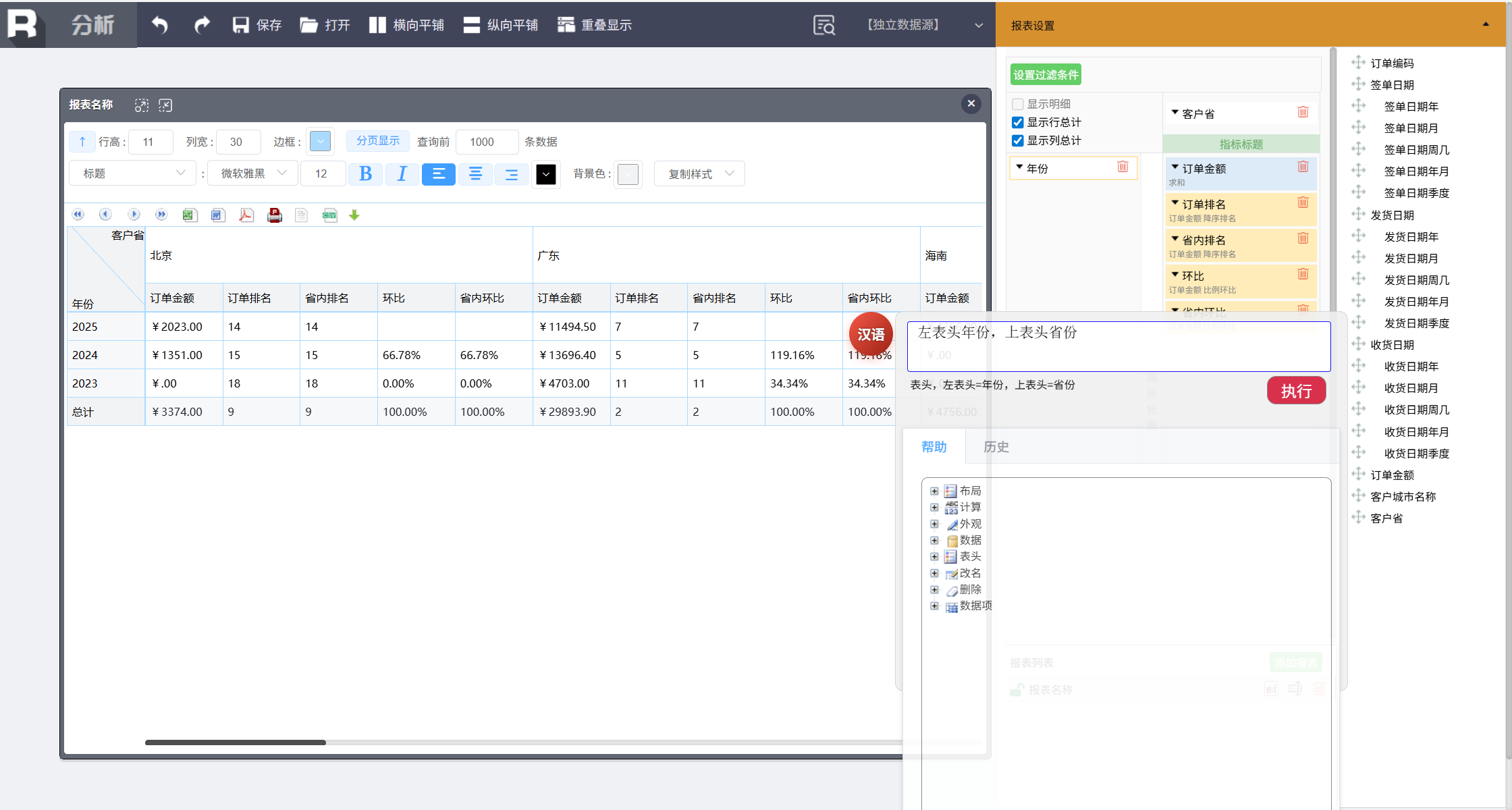
统计图
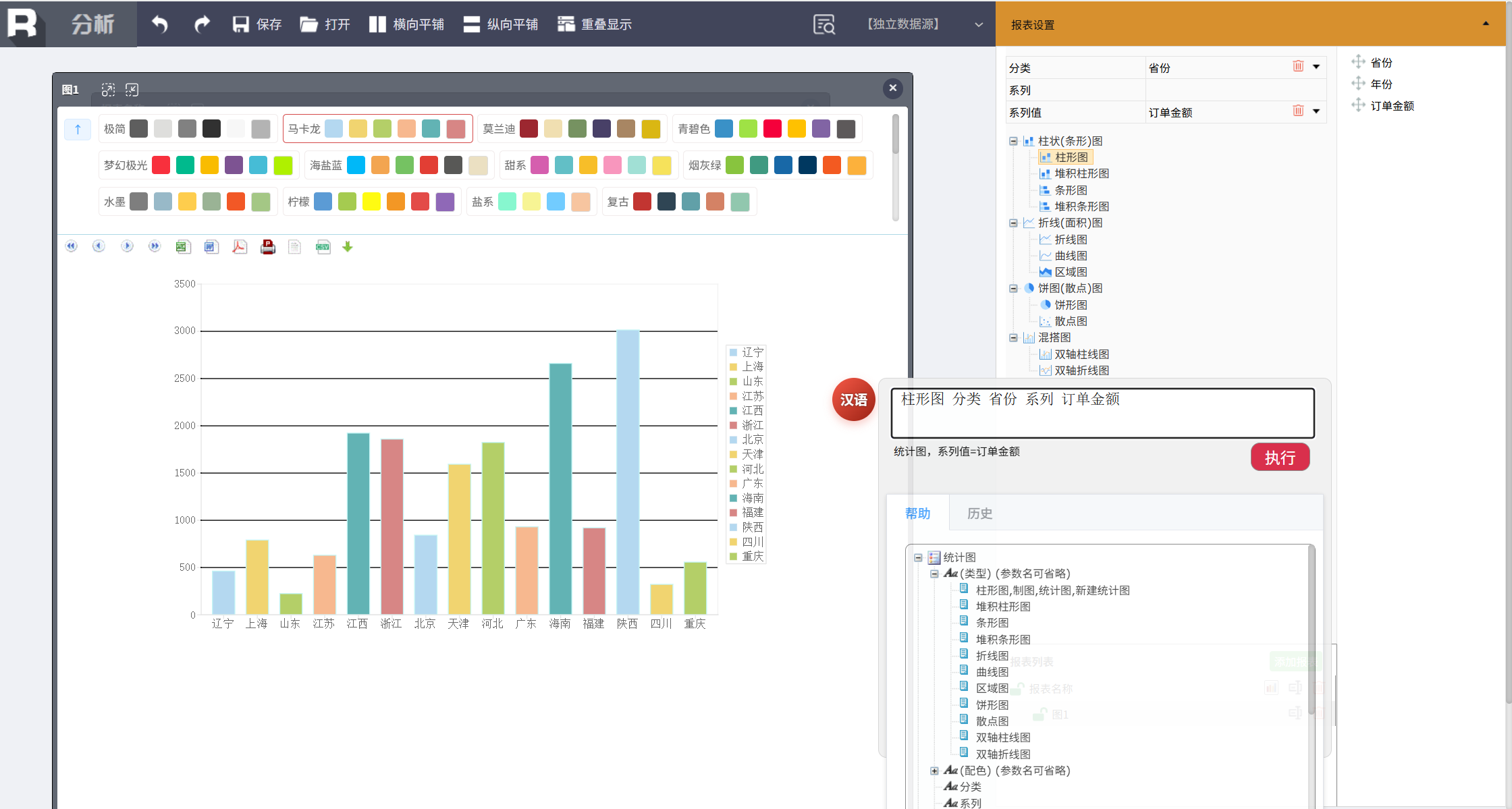
通过命令还可以生成各种类型的统计图及配色方案,输入如下命令:
柱形图 分类 省份 系列 订单金额
就得到了下面按省份统计订单金额的柱形图。
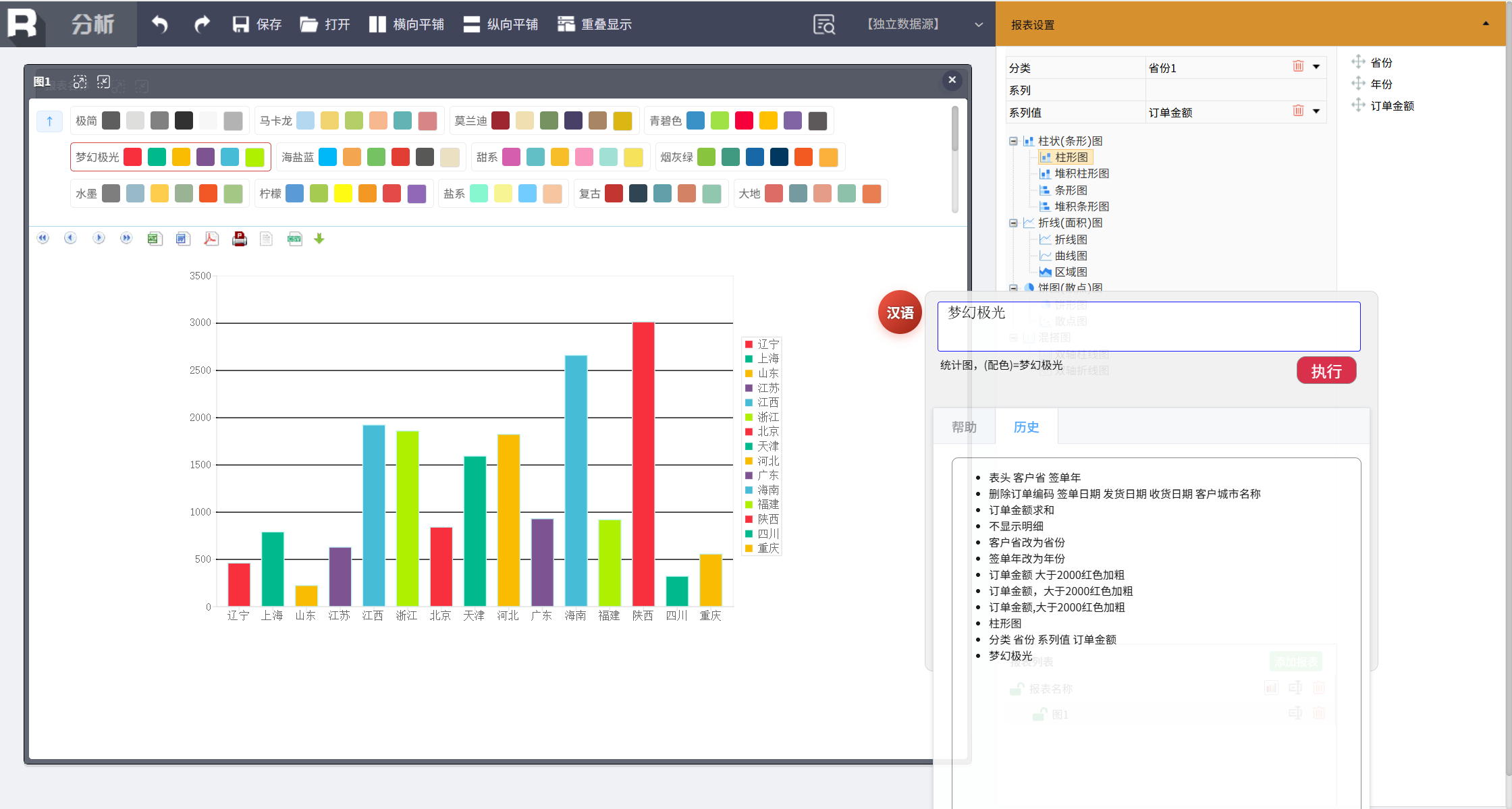
想要更改统计图的配色,输入命令:
梦幻极光
就得到了对应的配色方案
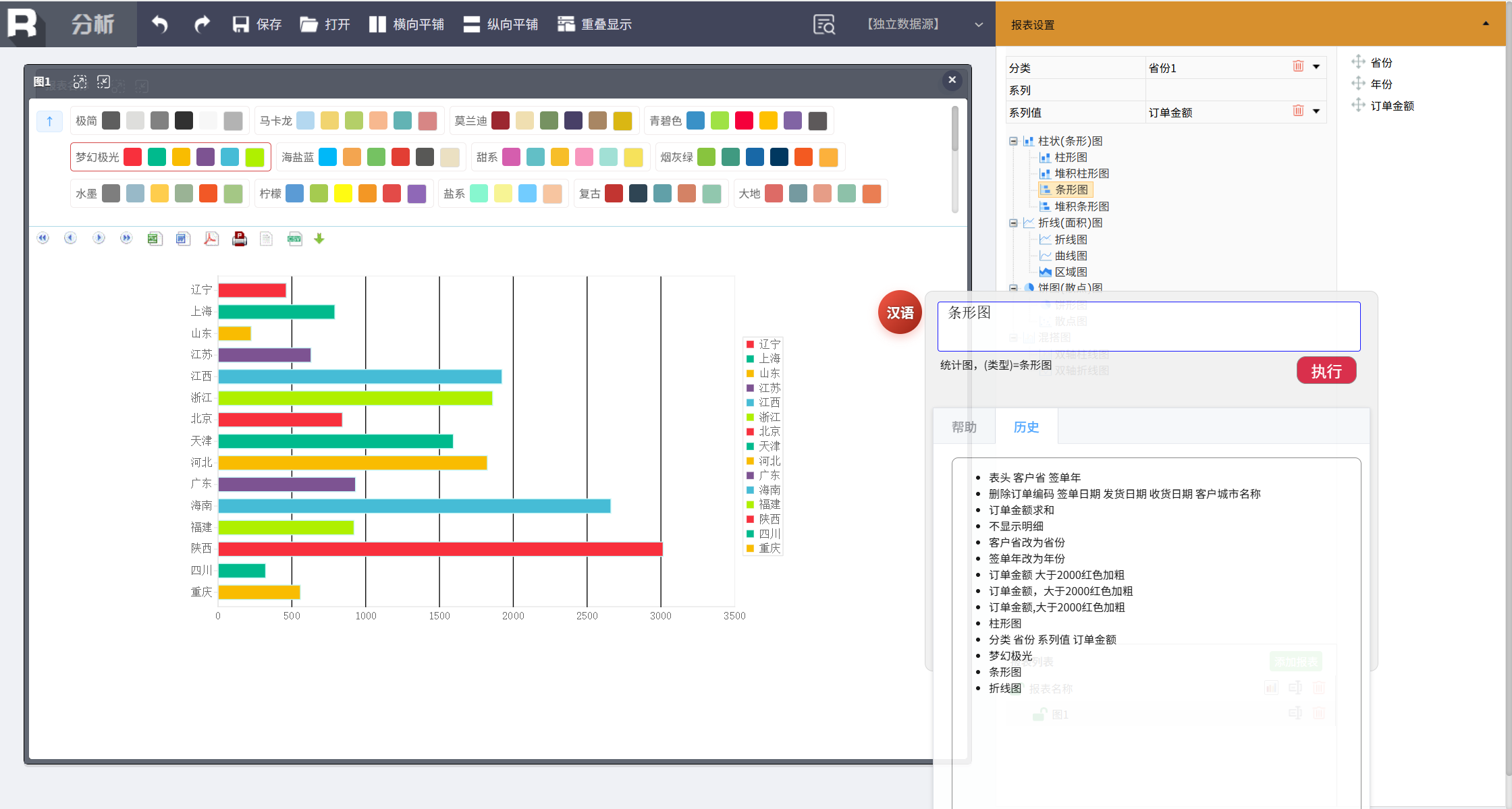
如果还想更改统计图类型,可以直接输入:
条形图
我们暂列这些,更多的命令及功能欢迎体验。
润乾 BI 的这套自然语言交互能力,延续了与 NLQ 一脉相承的规则引擎技术路线(而非依赖 LLM)。这带来了一个显著特点:极高的准确性与可靠性,从根本上杜绝了“幻觉”。相应地,系统需要接收相对规范、结构清晰的指令方能完美执行,例如“订单金额 降序排名 命名为‘订单排名’”。
不过,这也意味着一定的局限性,要求用户输入的语句有一定规范性,而不能随意使用完全口语化的命令。不过,BI 分析的操作空间本身有限且明确,使用规范语句带来的限制并不严重,很快就能熟悉掌握,和充满歧义、极度自由的自然语言相比,规范指令反而能带来准确无歧义、表达简洁高效的优点。
当然,对于不熟悉命令规范的新手,这还是会有一些使用门槛。为此,润乾 BI 内置了智能帮助体系。在输入框中键入时,系统会进行实时关键词过滤,动态联想并展示最相关的命令范例和完整参数提示,引导用户快速形成有效指令。
比如当输入到 “降序排名” 时会出现跨行运算提示,以及该命令需要的后续参数(命名为、数据项)。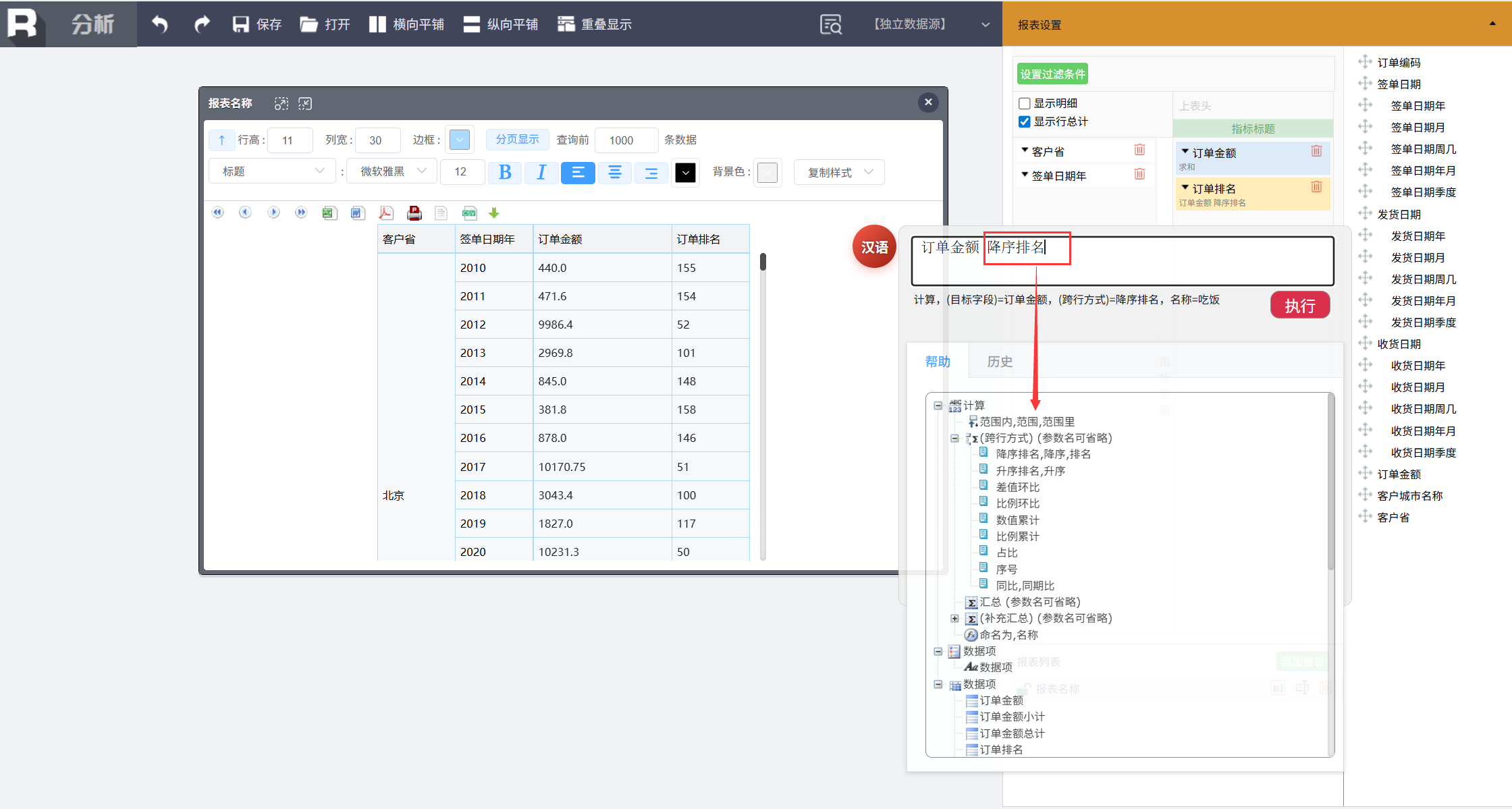
再比如输入“表头”,则会直接出现可以使用的数据项。
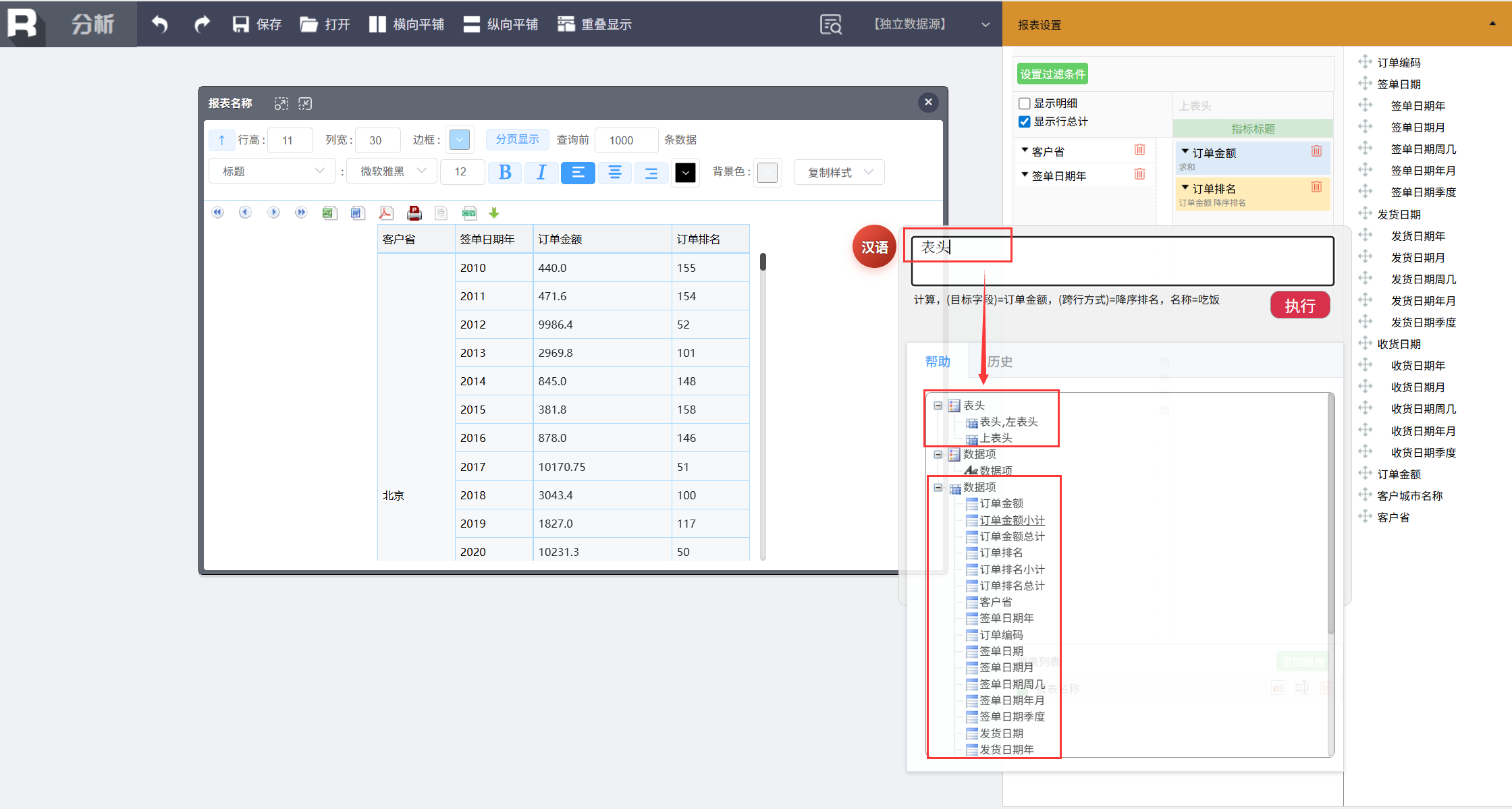
这意味着,无需记忆复杂语法,通过提示和参考,可以快速掌握“如何说”,从而将分析意图转化为有效的指令。对于熟悉业务的用户而言,这一过程非常直观自然。
润乾 BI 已能通过自然语言指令,全面驱动包括复杂筛选、多级排序、分组汇总、计算衍生指标(如排名、环比、占比)、单元格格式调整以及图表生成在内的所有核心分析操作。
这套自然语言操控能力为实现与大型语言模型(LLM)的深度协同奠定了理想的基础。一个清晰的演进路径是:将润乾 BI 的这套自然语言命令,作为可被 AI Agent 精准调用的“分析 API”。
LLM 能够充分发挥其“高级翻译官”与“任务规划师”的作用。当用户提出一个综合性、口语化的业务问题,例如:“分析一下我们上月在各区域的销售表现,找出问题并给出建议”,LLM 可以轻松地将其理解并分解,转化为一系列润乾 BI 可直接、精确执行的规范指令:
过滤签单年月是 202509 或是 202510
表头 区域 签单年月
订单金额求和
排序 签单年月升序
在客户省范围内 订单金额 比例环比 命名为 “环比”
环比小于 5% 红色加粗
这种结构清晰、语义明确的规范语句,对 LLM 而言,远比生成复杂的 JSON/XML 等程序化接口更为直接和友好。这一协同模式,完美融合了 LLM 在泛化理解、意图分解与逻辑规划方面的优势,以及润乾 BI 在分析操作执行上的绝对确定性与可靠性。更重要的是,LLM 生成的这一系列步骤,对于业务用户而言是可理解、可确认的,发现不合理时还可以即时修改,彻底打破了传统 AI 黑箱的局限。这使得处理复杂、多步骤的分析任务变得既高效灵活,又全程可信、可控。
ChatBI 的真正内涵,远不止于 Text2SQL。润乾 BI 让你用说话的方式直接操控报表,就像指挥一个懂业务的助手。不搞虚的,专注解决你每天实际要用的分析动作,让数据跟着你的话走,决策自然更轻松。

