


AI 查询数据,何必动用“核武器”?这引擎 CPU 就能跑,成本直降 90%
AI 时代,我们都很期待用自然语言查询数据,比如:只要输入 "我要查今年广东省客户的空调订单金额",系统就能自动转换成查询语句并返回结果,效率直接提升 N 倍!
实测一下效果似乎也不错,主流 AI 大模型在标准测试数据集 SPIDER 上能够达到 80% 以上的准确率,在中文测试数据集 CSPIDER 上也能达到 60% 以上的准确率。
但是,面对企业数据查询却遇到了难题。

企业级 AI 数据查询的难题
企业应用中的数据查询要用到特定的领域知识,包括:数据结构、业务规则和相关编程知识。
大模型可以对现有模型进行微调来获取这些领域知识。但微调需要用大量计算资源和高质量的标注数据对大模型进行训练,技术难度大,资源成本高,开发周期长。而且,一旦业务规则或者数据结构发生变化,模型就要重新微调,非常不灵活。
简单在提示词中嵌入领域知识,一定程度上也可以让大模型获取这些知识。不过,这会让提示词变得很长:

这么长的上下文信息提交到公用大模型,比如 DeepSeek,平均要等待一分钟以上才能得到结果,体验太恶劣了,而且 token 费用也很高昂。
私有化部署大模型可以提高性能,但成本却非常巨大:

这样的投入,堪称 "核武器" 级别,对大多数企业来说都是难以承受的。
润乾报表另辟蹊径,实现 AI 式的自然语言数据查询突破
润乾报表 NLQ 组件采用规则引擎技术,通过抽象汉语规律得到规则模型实现自然语言查询,能从根本上解决这一难题。
NLQ 组件预先用领域知识建立词典,导入数据结构,定义数据表、字段、维度、指标等专用词汇。词典中还包含比较词、量纲、聚合词、连接词等查询要素。
这些词汇承载了领域知识,从用户输入的自然语言词句匹配到词典中的词汇,就是应用领域知识的过程:

词典的规模不会超过十几万字符,规则引擎仅用普通 CPU 运算即可高效处理。在现代计算设备上,甚至普通笔记本电脑都能流畅地并行多个任务,完全不需要 GPU 集群。
润乾报表 NLQ 组件还能杜绝相当多的大模型幻觉问题,不会给出看似符合语法的错误语句。NLQ 如果识别不了用户的输入,会提示无法查询,请用户换一种说法再尝试。而大模型则永远会给出一个结果,即使是错误结果。这种情况下,不懂编程的业务用户根本没办法发现和纠正大模型的错误。
NLQ 组件给出结果后,会以用户看得懂的形式对这个语句进行解释,如果有多种解释也会让用户选择,比如日期可以是发货日期或者收货日期:
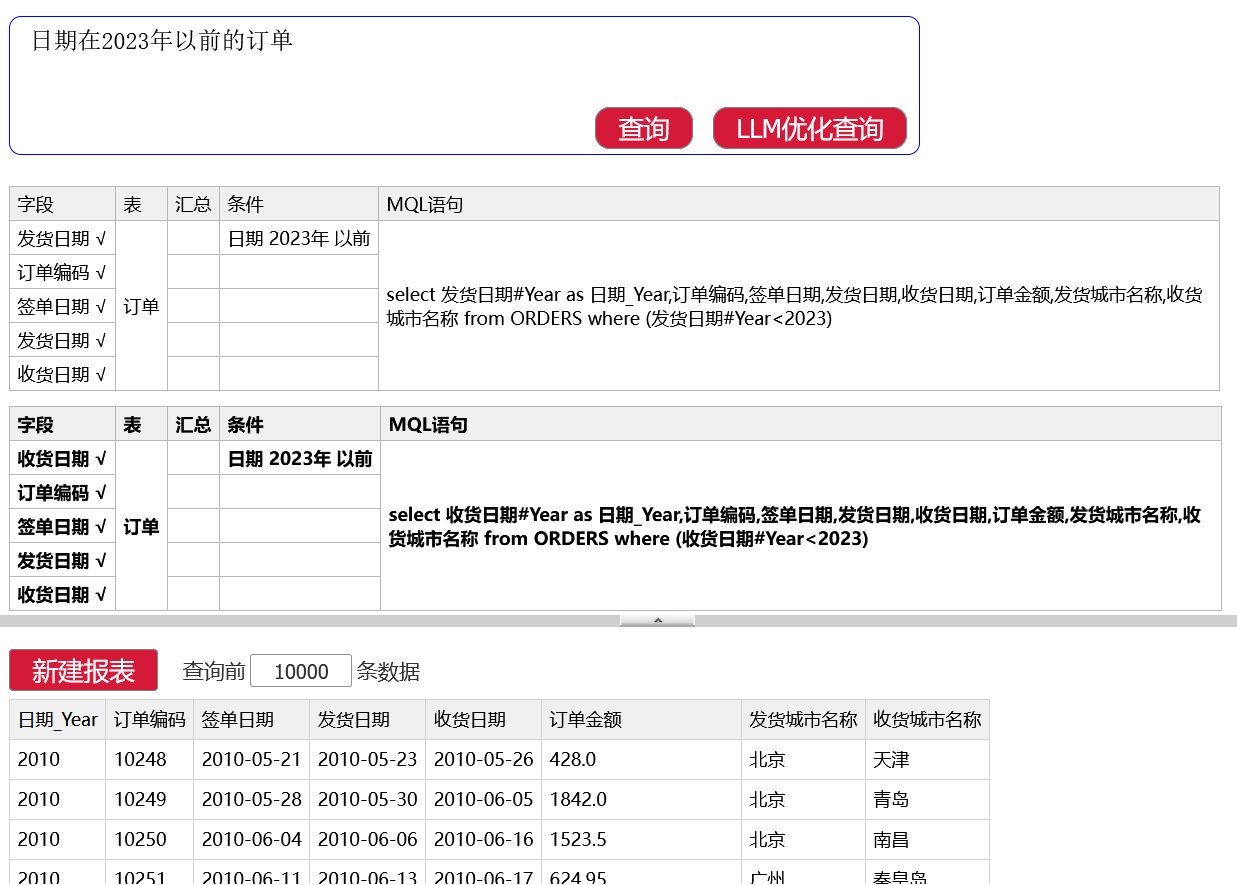
润乾报表 NLQ 搭配大模型,让自然语言数据查询锦上添花
规则引擎对自然语言的规范性有一定要求,不能使用太随意的词句。我们可以通过适当的培训,让用户习惯用相对规范的自然语言表达,就可以达到很好的使用效果。实际上,用户使用大模型也常常要学习“提示工程”,了解如何写提示词才能得到较好的结果。
润乾报表 NLQ 组件不依赖大模型就可以工作,搭配大模型后还能进一步提升用户体验,可以用更为随意的自然语言来查询数据:

这样搭配的优势很明显:大模型不需要获得领域知识,负载降到最低,企业也不需要私有化部署,直接使用公用接口即可达到性能要求。规则引擎承载所有的领域知识,全部计算都利用本地 CPU 完成,不需要高端 GPU 资源。
在技术快速发展的今天,我们不需要总是动用 "核武器" 来解决所有问题。像润乾报表 NLQ 组件这样的规则引擎,抽象汉语规律来实现 AI 式自然语言查询的解决方案,用 CPU 资源就能获得出色效果,建设成本从私有部署大模型的百万元级别到十万元级别,降低了 90%,为企业提供了更加务实和经济的选择,每个企业都能以更低的成本享受 AI 数据查询带来的效率提升。

