4. 时间统计
4.1 数据介绍
打开集算器,直接运行 createOrders.splx,即可得到如下数据表:
有某商超订单数据表 orders.csv,其字段为:
| 列名 | 含义 |
|---|---|
| orderID | 订单号 |
| userID | 用户 ID |
| orderTime | 订单时间 |
| amount | 订单金额 |
此表包含 2022-2024 年共三年的商超订单记录,共计 600 万条,由于字段数少,一般的笔记本电脑均能全内存装下,因此本章依旧按全内存计算来介绍算法。
4.2 按年、月统计销售额
| A | |
|---|---|
| 1 | =file(“orders.csv”).import@tc(orderTime,amount) |
| 2 | =A1.groups(year(orderTime):Year,month(orderTime):Month;sum(amount):TotalAmount) |
A1 从 orders.csv 文件中读入 orderTime,amount 两个字段的数据,import 函数中指定选出字段可节约内存
A2 将 A1 按年、月分组统计销售额,再次强调:年月计算表达式可直接作为分组表达式。
A2 的运行结果:
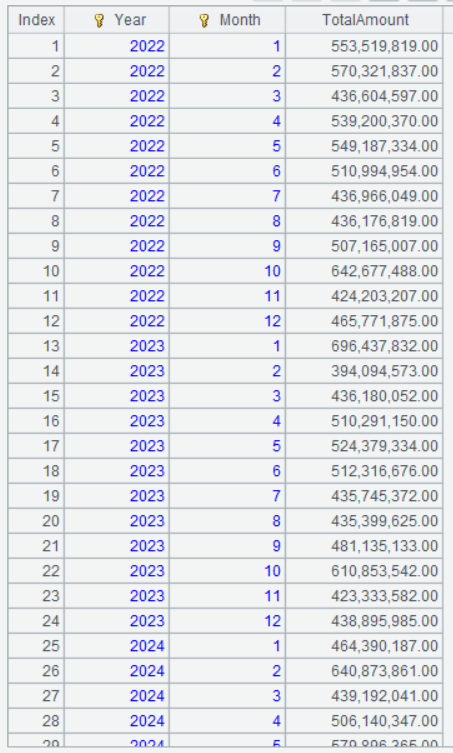
从运算结果可以看出,分组统计的结果自动按分组表达式排序了,下一节的内容需要用到这个有序,就不需要再次排序了。
4.3 销售额环比增长率
| A | |
|---|---|
| 1 | =file(“orders.csv”).import@tc(orderTime,amount) |
| 2 | =A1.groups(year(orderTime):Year,month(orderTime):Month;sum(amount):TotalAmount) |
| 3 | =A2.derive((TotalAmount-TotalAmount[-1])/TotalAmount[-1]:MoM) |
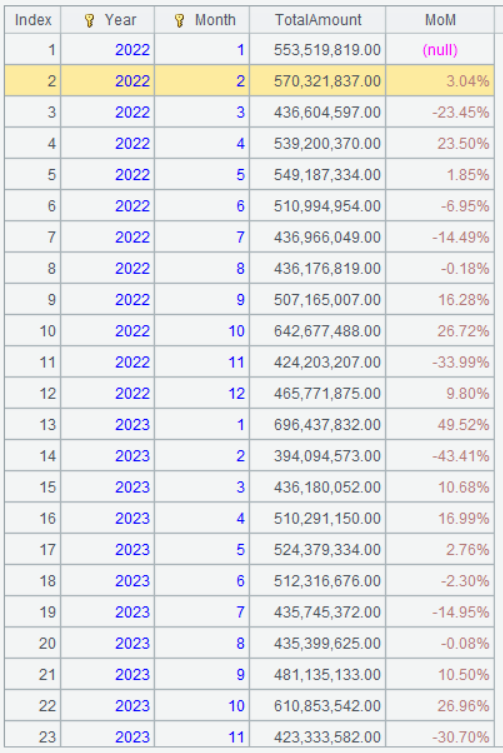
A3 由于 A2 的数据已经按年月有序了,因此这里直接用 [-1] 运算符获得上一行的TotalAmount,即可直接算出环比增长率。[-1] 运算符的含义参见前面的知识点介绍。
A3 的运算结果:
知识点:什么是环比增长率(MoM, Month-over-Month Growth Rate)
环比增长率是指某一指标(如销售额、用户数、GDP 等)在相邻两个统计周期(通常按月或季度)之间的增长比率,用于衡量短期内的变化趋势。
- 计算公式:
$$
环比增长率 =(本期数值−上期数值)/ 上期数值
$$
- 核心特点:
- 时间周期连续:比较的是相邻时间段(如本月 vs. 上月,本季度 vs. 上季度)。
- 反映短期波动:适合分析季节性、突发事件或短期趋势(如节日促销后的销售变化)。
- 受季节影响大:例如零售业在 12 月(圣诞节 / 元旦)的环比增长率可能显著高于其他月份。
4.4 同比增长率
实现思路一:由于超市每月都有数据,不存在断月的情况,所以用 [-12] 即可获得上一年同月的数据
| A | |
|---|---|
| 1 | =file(“orders.csv”).import@tc(orderTime,amount) |
| 2 | =A1.groups(year(orderTime):Year,month(orderTime):Month;sum(amount):TotalAmount) |
| 3 | =A2.derive((TotalAmount-TotalAmount[-12])/TotalAmount[-12]:YoY) |
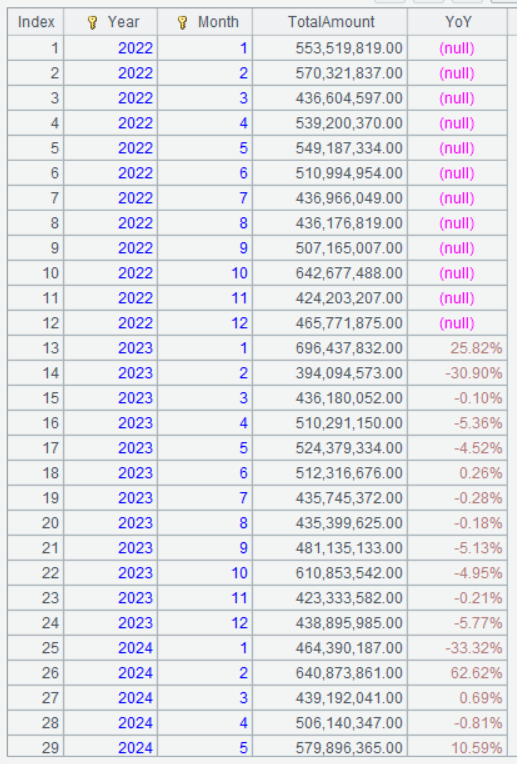
A3 TotalAmount[-12]获得去年同月的数据,[-12]的含义参见前面的知识点介绍。
A3 的运行结果:
实现思路二:将数据按月、年排序,这样就可以使用 [-1] 来获得去年同月的数据,加上 if 判断,即可实现断月的情况:
| A | |
|---|---|
| 1 | =file(“orders.csv”).import@tc(orderTime,amount) |
| 2 | =A1.groups(month(orderTime):Month,year(orderTime):Year;sum(amount):TotalAmount) |
| 3 | =A2.derive(if(Year[-1]==Year-1 && Month[-1]==Month, (TotalAmount-TotalAmount[-1])/TotalAmount[-1], null):YoY) |
A2 按月、年排序
A3 增加 if 判断,如果上一行的年份等于当前年份 -1,且上一行的月份等于当前月份,则用(TotalAmount-TotalAmount[-1])/TotalAmount[-1]表达式计算比去年同期,否则返回 null
知识点:什么是同比增长率(YoY, Year-over-Year Growth Rate)
同比增长率是指某一指标(如销售额、利润、GDP 等)在相同统计周期但不同年份之间的增长比率,用于消除季节性影响,反映长期趋势。
- 计算公式:
$$
同比增长率 =(本期数值−去年同期数值)/ 去年同期数值
$$
- 核心特点:
- 时间周期同比:比较的是相同时间段的不同年份(如 2024 年 Q1 vs. 2023 年 Q1)。
- 消除季节波动:避免节假日、气候等季节性因素的干扰,更反映真实增长潜力。
- 衡量长期趋势:适合分析年度增长、行业周期或政策效果。
4.5 5 日移动平均
| A | |
|---|---|
| 1 | =file(“orders.csv”).import@tc(orderTime,amount) |
| 2 | =A1.groups(date(orderTime):Date;sum(amount):Amount) |
| 3 | =A2.derive(Amount[-2:2].avg():ma5) |
A2 将数据按日分组统计日总销售额
A3 Amount[-2:2]表示当前行的前两行到后两行之间,一共五行的Amount字段值组成的集合,.avg()表示对其求平均
A3 的运行结果如下:
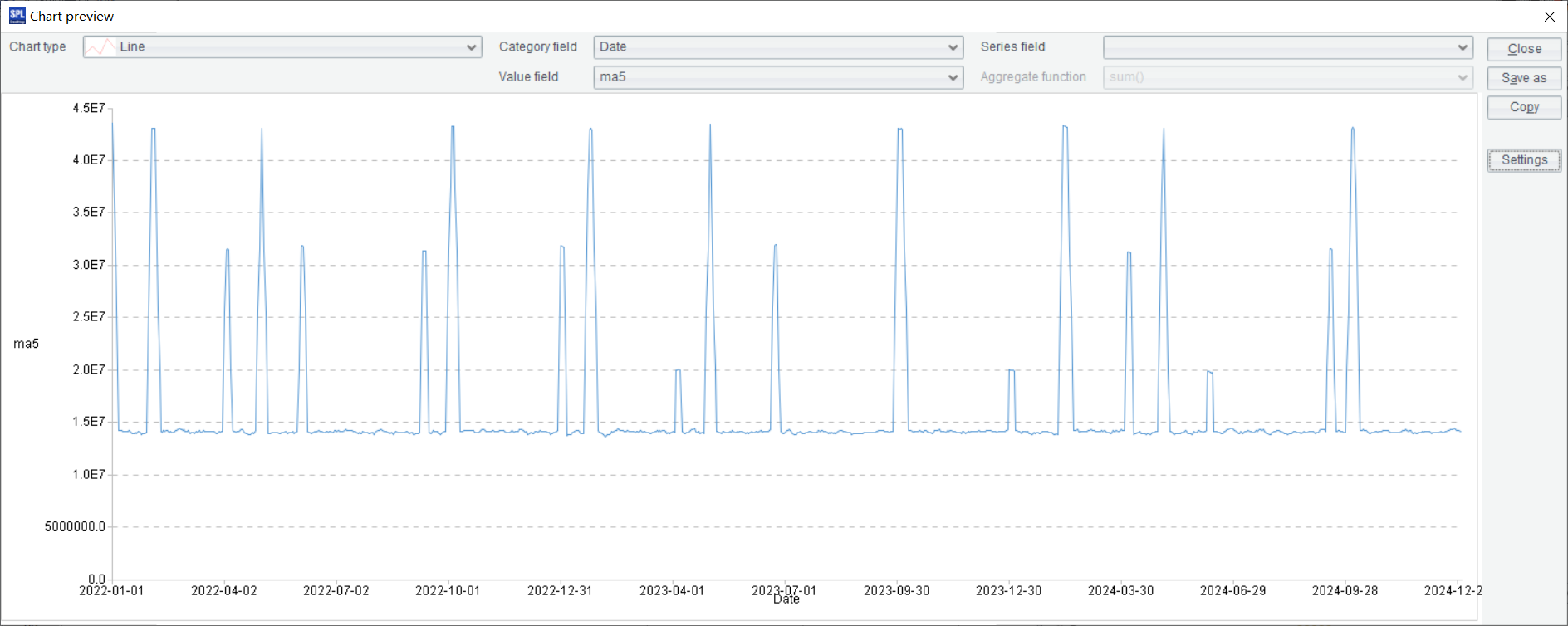
点击右上角的统计图标:
选择 Line,Category 选择 Date,Value 选择 ma5,点击 settings 按钮,弹出框里,
横轴标签间隔选 90,Legend 选择 None,于是得到如下统计图展示:
知识点:什么是 Amount[-2:2]
在集算器 (esProc) 的 SPL 语言中,Amount[-2:2]表示对Amount字段进行相对位置范围引用,这是一种强大的滑动窗口引用语法。
Amount [-2:2] 表示以当前记录为中心,向前取 2 条记录、向后取 2 条记录(包含当前记录本身)构成的子序列。这种引用方式特别适合实现滑动窗口计算、移动平均等需要上下文数据的分析场景。
-
基本特性
- 窗口定义:[起始偏移: 结束偏移] 定义相对位置窗口
- 包含边界:包含起始和结束偏移位置的记录
- 动态窗口:窗口大小固定但内容随当前记录位置变化
- 自动截断:当窗口超出序列边界时自动截断
-
示例数据表
| 行号 | 月份 | Amount |
|---|---|---|
| 1 | 1 月 | 100 |
| 2 | 2 月 | 120 |
| 3 | 3 月 | 150 |
| 4 | 4 月 | 130 |
| 5 | 5 月 | 160 |
- Amount[-2:2] 运算过程
| 当前处理行 | Amount[-2:2] 取值 | 窗口包含的记录位置 |
|---|---|---|
| 1 月记录 | [100,120,150] | 行 1-3,无法向前取 2 行 |
| 2 月记录 | [100,120,150,130] | 行 1-4,无法向前取足 2 行 |
| 3 月记录 | [100,120,150,130,160] | 行 1-5(完整的 -2:+2 窗口) |
| 4 月记录 | [120,150,130,160] | 行 2-5,无法向后取足 2 行 |
| 5 月记录 | [150,130,160] | 行 3-5,无法向后取 2 行 |
-
边界情况处理
- 起始边界:当向前取不到足够记录时,窗口自动缩小
- 结束边界:当向后取不到足够记录时,窗口自动缩小
- 空窗口:极端情况下可能返回空序列
- 非对称窗口:也支持如 Amount[-3:1] 这样的非对称窗口
-
应用场景
这种灵活的窗口引用机制使得 SPL 能够用非常简洁的语法实现复杂的滑动窗口分析,包括:
- 移动平均计算
- 滚动统计量
- 前后记录对比分析
- 局部趋势计算等
知识点:什么是移动平均?
移动平均是一种用于分析时间序列数据的统计方法,通过计算特定时间窗口内数据的平均值来平滑短期波动,帮助观察长期趋势。它广泛应用于金融(如股票分析)、经济学、气象学、质量控制等领域。
-
核心概念
- 平滑数据:消除短期噪声(如价格波动、随机误差),凸显主要趋势。
- 时间窗口:计算平均值的时间范围(如 5 日、20 日、200 日等),窗口越大,曲线越平滑,但对近期变化反应越迟钝。
-
计算公式:
$$
MAn=(p1+p2+⋯+pn)/n
$$
其中 pn 为第 n 天的数据(如收盘价),n 为窗口大小(如 5 天)。
- 应用场景
- 股票的均线分析:如 5 日均线(短期)、20 日均线(中期)、200 日均线(长期)。股票的均线是往前求平均,如 [-5:-1] 和[-19:-1],是不对称窗口,这点在 SPL 中有很强的优势,不需要专门的函数来处理。
- 经济数据:平滑 GDP、失业率等指标的季节性波动。
- 气象学:处理温度、降水量的短期波动。
4.6 工作日 vs 周末销售对比
实现思路:将数据按日统计后,分别算出星期数,然后分别选出周六日的数据和工作日的数据各自算日平均,即可获得两者数据的对比
| A | |
|---|---|
| 1 | =file(“orders.csv”).import@tc(orderTime,amount) |
| 2 | =A1.groups(date(orderTime):Date;sum(amount):Amount) |
| 3 | =A2.derive(day@w(Date):weekday) |
| 4 | =A3.select(weekday==1 || weekday==7) |
| 5 | =(A3\A4) |
| 6 | =A4.avg(Amount) |
| 7 | =A5.avg(Amount) |
A3 添加计算列,算出日期对应星期几,day@w(Date)表示计算 Date 的星期几。
A4 选出星期几为 1 或 7 的记录,对应周日和周六。
A5 从 A3 中选出 A4 中不存在的记录,即返回工作日记录。\ 符号是序列(也就是集合)的差运算。
A6 和 A7 各自算出工作日和周末的日均销售额。
从计算结果可以看出,周末的日均销售额比工作日的日均销售额大很多,可以在周末增加人手。
4.7 时段销售占比
实现思路:将销售数据按小时分组汇总,然后求出小时的平均销售额,最后算出一天内的占比,从而了解一天内销售的波峰和低谷,考虑到周六日和工作日的不同,所以这两种日期分别统计:
| A | |
|---|---|
| 1 | =file(“orders.csv”).import@tc(orderTime,amount) |
| 2 | =A1.groups(date(orderTime):Date,hour(orderTime):Hour;sum(amount):Amount) |
| 3 | =A2.select([1,7].pos(day@w(Date))) |
| 4 | =(A2\A3) |
| 5 | =A3.groups(Hour;avg(Amount):avgAmount).sort(-avgAmount) |
| 6 | =A4.groups(Hour;avg(Amount):avgAmount).sort(-avgAmount) |
A2 将数据按日期、小时分组统计总销售额。
A3 选出星期几为 1 或 7 的记录,即周末的数据。[1,7].pos(day@w(Date))表示day@w(Date)算出的星期几是否在集合[1,7]中,如果在,返回序号,不在,则返回 null。
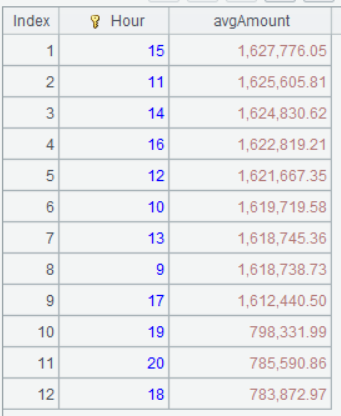
A5 按小时分组统计周末的时均销售额,并排序。
A6 按小时分组统计工作日的时均销售额,并排序。
A5 的运算结果:
A6 的运算结果:
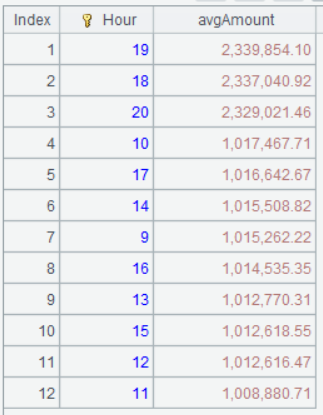
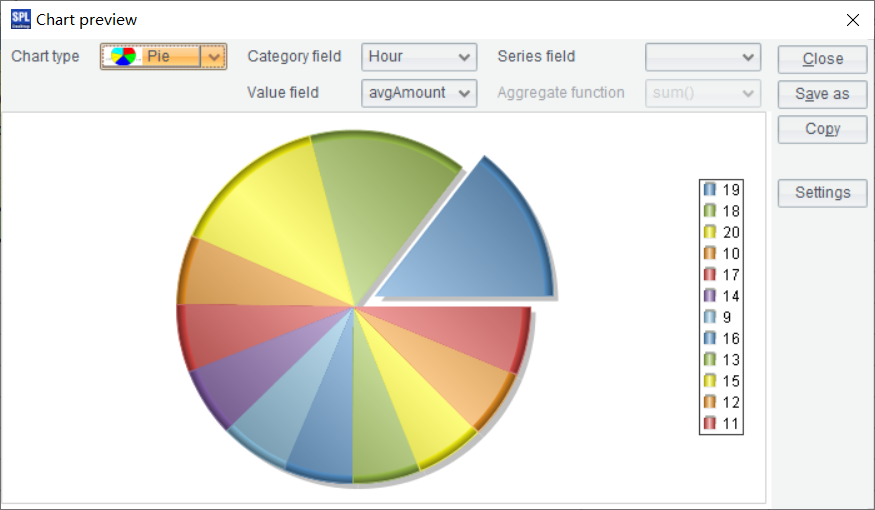
从结果可以看出,工作日 18-21 点为销售高峰,周末 9-18 点为销售高峰,可以据此优化营业时间或资源分配(如增加高峰时段人手)
4.8 销售完成度追踪
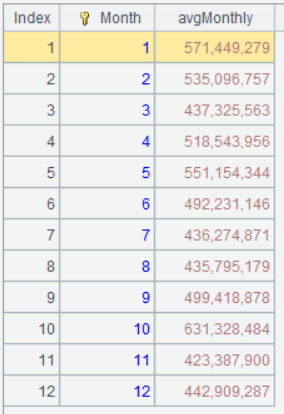
以月均销售额作为月销售目标,要求计算 24 年 10 月份的日累计销售完成度
第一步:计算月均销售额
| A | |
|---|---|
| 1 | =file(“orders.csv”).import@tc(orderTime,amount) |
| 2 | =A1.groups(year(orderTime):Year,month(orderTime):Month;sum(amount):TotalAmount) |
| 3 | =A2.groups(Month;avg(TotalAmount):avgMonthly) |
A2 按年、月分组统计月销售额。
A3 按月分组统计月均销售额,即为该月的销售目标。
A3 的运行结果如下:
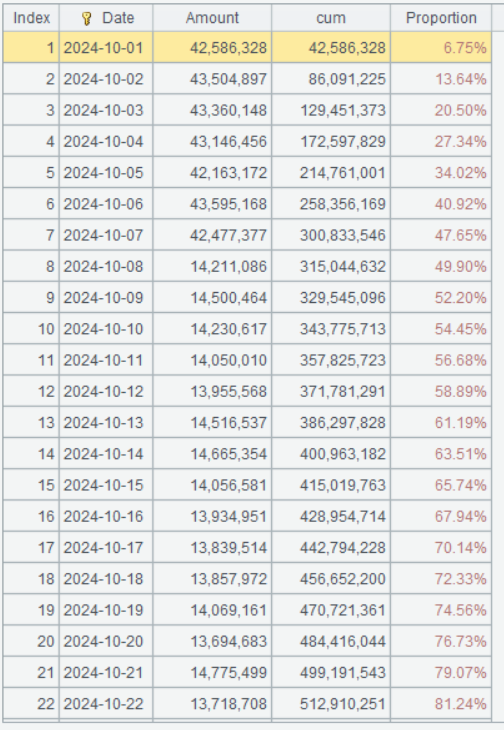
第二步:选出 24 年 10 月份的数据,先按日分组统计日销售额,然后算累计,再用累计除以销售目标,获得当日销售完成度。
| A | |
|---|---|
| 4 | =A1.select(year(orderTime)==2024 && month(orderTime)==10) |
| 5 | =A4.groups(date(orderTime):Date;sum(amount):Amount) |
| 6 | =A5.derive(cum[-1]+Amount:cum,cum/A3(10).avgMonthly:Proportion) |
A4 选出 24 年 10 月份的数据。
A5 按日统计销售额。
A6 cum[-1]+Amount表示用前一日的累计值加本日的销售额,即为当日累计值;cum/A3(10).avgMonthly表示用当日累计销售额除以 10 月份的销售目标,即为当日累计销售完成度。A3(10)表示从 A3 中取第 10 条记录,A3(10).avgMonthly表示取该记录avgMonthly字段值。
A6 的运行结果:
4.9 复购周期分析
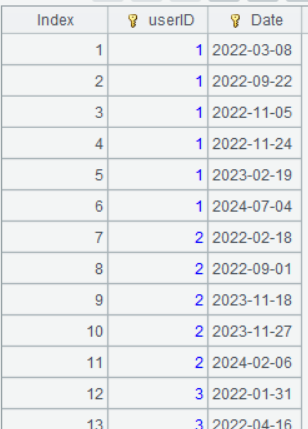
第一步:读数,把数据按用户 ID、下单日期求唯一,我们把一天内购买多次的用户视为购买遗漏商品,或者为了优惠拆单下单,不视作复购用户,因此对其按日期求唯一。
| A | |
|---|---|
| 1 | =file(“orders.csv”).import@tc(userID,orderTime) |
| 2 | =A1.groups(userID,date(orderTime):Date) |
A1 从 orders.csv 文件中读出 userID,orderTime 字段
A2 将数据按UserID、date(orderTime)分组。groups 函数没有聚合表达式,表示对分组字段求 distinct。
A2 运行结果如下:
第二步:计算复购间隔:
| A | |
|---|---|
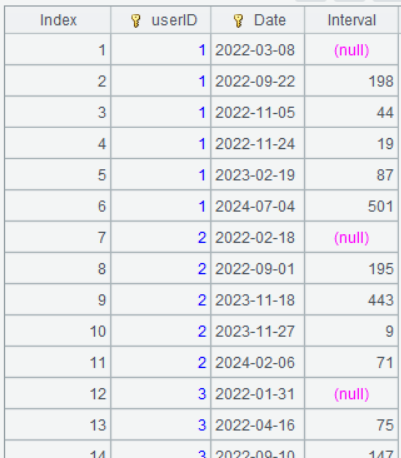
| 3 | =A2.derive(if(userID[-1]==userID,interval(Date[-1],Date),null):Interval) |
A3 if(userID[-1]==userID,interval(Date[-1],Date),null)表示当上一行的 userID 和本行相同时,计算上一行和本行的日期间隔几天,否则返回 null。interval函数用于计算两个日期的间隔,缺省返回值的单位是天。
A3 的运行结果为:
第三步:计算平均复购天数
| A | |
|---|---|
| 4 | =A3.select(Interval) |
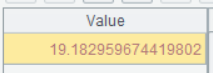
| 5 | =A4.avg(Interval) |
A4 选出 Interval 不为空的记录
A5 计算平均复购天数
A5 的运行结果为:
第四步:选出最后一次购买日期早于“平均复购天数”之前的用户
| A | |
|---|---|
| 6 | =now@d()-A5 |
| 7 | =A2.group@o(userID).(~.m(-1)) |
| 8 | =A7.select(Date<A6) |
A6 now@d()表示返回当前日期,不包含时间分量;now@d()-A5计算 "平均复购天数" 之前的日期。在 SPL 中,可以像 excel 一样直接用减号/加号计算 n 天之前或 n 天之后的日期。
A7 将 A2 按 userID 分组,选出每一组的最后一条记录,即为该用户最后一次购买的日期。~.m(-1)表示从当前组中选出最后一条记录。
A8 从 A7 中选出购买日期早于 A6 的,即为当前购买间隔已经超过平均复购天数的用户,需要对其制定召回策略。
A7 的运行结果为: