


KNN 指标
KNN 是机器学习中的一种算法,它的核心思想是:如果一个样本在特征空间中的 K 个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别。更通俗点说,KNN 可以找到和目标样本最相似的 K 个样本,然后根据其中的大多数来预测目标样本。
我们也可以用这种方法来预测股票的涨跌,构造一个特征空间然后在历史数据中找到和当日特征最相似的 K 个交易日数据,然后根据这 K 个交易日第二天的涨跌情况来预测第二天的涨跌(大多数涨就预测为涨,大多数跌就预测为跌)。
KNN 简单策略的具体方法如下:
1. 将第二天是否上涨作为预测目标,即计算收盘 [1]- 收盘,大于 0 时目标值为 1,小于 0 时为 -1,其余为 0。
2. 增加两个特征,最高价 - 最低价和收盘价 - 开盘价作为特征空间
3. 计算历史数据和当日样本特征之间的距离,距离越近越相似。具体为:计算当天样本特征和之前 n 个交易日的特征距离,找到距离最近的 m 个交易日数据,把这 m 个交易日目标值的众数作为第二天的预测结果。
指标参数:
y |
指标返回列。1上涨信号,-1下跌信号 |
n |
数字,计算和前n个交易日的特征距离 |
m |
数字,前m个距离最近的数据 |
函数代码:
A |
B |
|
1 |
func KNNDIF(A, $y, n, m) |
=A.derive@o( [最高-最低,收盘-开盘]:KNNDIF1, sign(收盘[1]-收盘):KNNDIF2) |
2 |
=A.run(${y}=~[-n:-1].top(m; dis( KNNDIF1, A.KNNDIF1) ).(KNNDIF2).mode() ) |
|
3 |
=A.alter(; KNNDIF1, KNNDIF2) |
B1 格中的 [最高 - 最低, 收盘 - 开盘] 是我们构造的特征空间,读者可以自行修改。
举例:调用脚本计算浦发银行 2024 年的 KNN 指标。n 取 100,m 取 20。
A |
B |
|
… |
… |
… |
5 |
=call@f("indicator.splx") |
登记脚本中的函数 |
6 |
… |
计算出源数据 |
7 |
=A6.derive(:KNN) |
增加要返回的指标字段 |
8 |
=KNNDIF(A7, KNN, 100, 20) |
调用函数计算指标 |
运行效果:
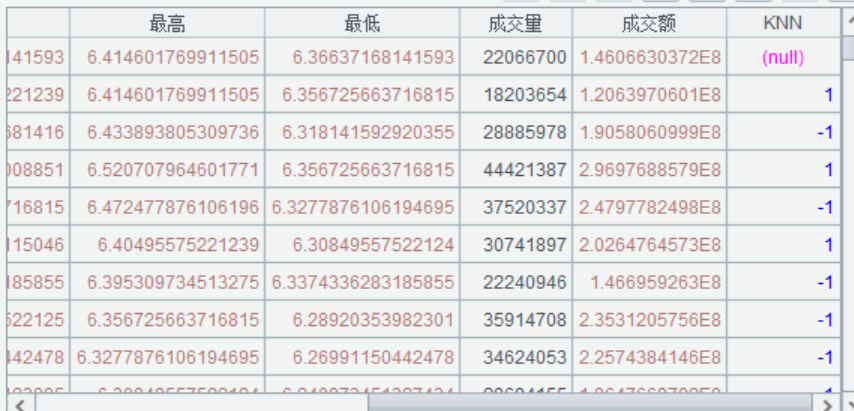
指标应用案例:第 13 章 KNN 简单策略 - 乾学院

