


第四篇 - 大主子表关联
这一篇介绍主键关联的提速。
主表订单表和子表明细表的关联就是主键关联。SQL 中,这种关联仍用 JOIN 实现,在两个表都很大的情况下,常常出现计算速度非常慢的现象。
如果预先将主子表都按照主键有序存储,就可以使用归并算法实现关联。这种算法只需要对两个表依次遍历,不必借助外存缓存,可以大幅降低计算量和 IO 量。
esProc SPL 支持有序归并算法,可以大幅提升主子表关联计算性能。
先做数据准备,把历史数据从数据库导出为 CTX 文件。在 ETL 中定义 Q4.etl:
修改两个表的名字,加上 Q4。
detailsQ4 表按照首字段分段:
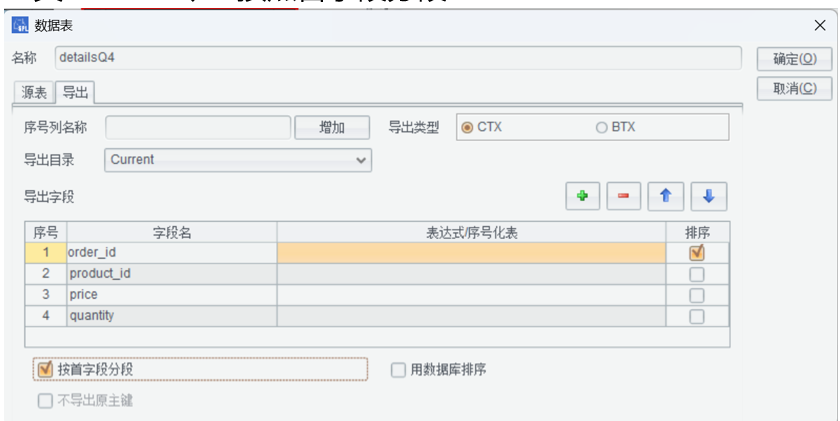
detailsQ4 表中的 order_id 不唯一,要声明第一个字段是分段键。
防止分段读取时,把某个 order_id 的记录拆分到两段。SPLX 中 create 会自动加 p 选项。
注意:两表要按照 order_id 连接,就按照这个字段有序存储。但不选中“用数据库排序”。
生成 SPL 代码 18:
A |
|
1 |
=connect("speed") |
2 |
="d:\\speed\\etl\\" |
3 |
=A1.cursor("SELECT order_id,customer_id,employee_id,employee_name,order_date,shipper_id,shipping_fee,shipping_address FROM orders") |
4 |
=A3.sortx(order_id) |
5 |
=file(A2+"ordersQ4.ctx").create@y(#order_id,customer_id,employee_id,employee_name,order_date,shipper_id,shipping_fee,shipping_address).append(A4).close() |
6 |
=A1.cursor("SELECT order_id,product_id,price,quantity FROM details") |
7 |
=A6.sortx(order_id) |
8 |
=file(A2+"detailsQ4.ctx").create@yp(#order_id,product_id,price,quantity).append(A7).close() |
9 |
=A1.close() |
A5和 A8 中用 #order_id 来声明 CTX 是对这个字段有序的。
在 details 表中,A8 自动给 create 函数加 @p 选项,表示第一个字段是分段键。防止分段读取时,把某个 order_id 的记录拆分到两段。
例 4.1 指定日期范围,按照客户分组统计订单金额。
select
o.customer_id,sum(d.quantity * d.price)
from
orders o
join
details d on o.order_id = d.order_id
where o.order_date>='2024-01-15'
and o.order_date<='2024-03-15'
group by o.customer_id;
执行时间 25 秒。
SPL 代码 19:
A |
|
1 |
=now() |
2 |
=file("ordersQ4.ctx").open().cursor@m(order_id,customer_id;order_date>=date(2024,1,15) && order_date<=date(2024,3,15)) |
3 |
=file("detailsQ4.ctx").open().cursor(order_id,quantity,price;;A2) |
4 |
=joinx(A2:o,order_id;A3:d,order_id) |
5 |
=A4.groups(o.customer_id;sum(d.quantity*d.price)) |
6 |
>output("query cost:"/interval@ms(A1,now())/"ms") |
执行时间 1 秒
A3 中游标的最后一个参数是 A2,表示多线程并行时,details 表会跟随 orders 表分段,保证后面两个表有序归并的正确性。
A4 中 orders 和 details 有序关联归并。
A5 对归并的结果分组汇总。
重点注意 A4:
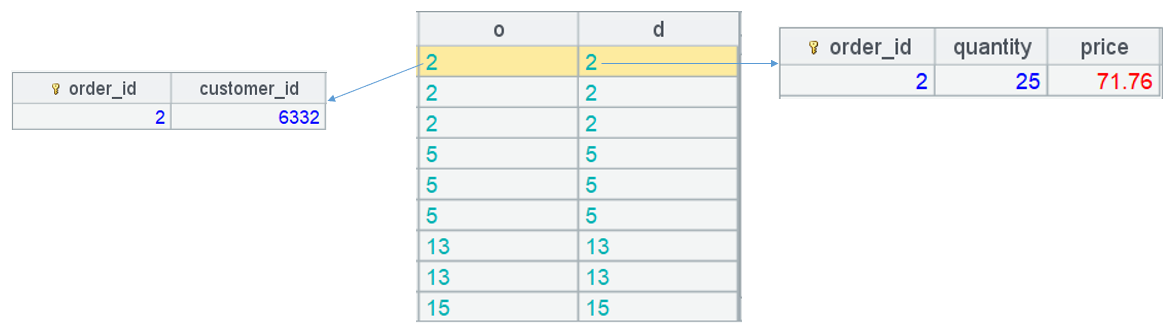
joinx 对 orders 和 details 有序关联归并,结果游标包含两个字段。图中可以看到,每个字段值都是记录对象。
还要注意,两表是一对多关系,订单表数据会被复制。
例 4.2 客户号是 3 或 9 的订单,按照产品号分组统计订单金额。
select
d.product_id,sum(d.quantity * d.price)
from
orders o
join
details d on o.order_id = d.order_id
where o.customer_id =3
or o.customer_id=9
group by d.product_id;
执行时间 21 秒。
SPL 代码 20:
A |
|
1 |
=now() |
2 |
=file("ordersQ4.ctx").open().cursor@m(order_id;customer_id==3 || customer_id==9) |
3 |
=file("detailsQ4.ctx").open().cursor(order_id,quantity,price,product_id;;A2) |
4 |
=joinx(A2:o,order_id;A3:d,order_id) |
5 |
=A4.groups(d.product_id;sum(d.quantity*d.price)) |
6 |
>output("query cost:"/interval@ms(A1,now())/"ms") |
执行时间 0.6 秒。
例 4.3 求平均每个订单的金额。要求:找产品号不是 2、8 的订单明细,按照日期分组,求平均每个订单的金额。注意:订单数量要去重计数。
select
o.order_date,sum(d.quantity * d.price)/count(distinct o.order_id)
from
orders o
join
details d on o.order_id = d.order_id
where d.product_id !=2
and d.product_id !=8
group by o.order_date;
执行时间是 40 秒,在主子表关联后计算去重计数,这两种计算 SQL 的性能都不佳。
SPL 代码 21:
A |
|
1 |
=now() |
2 |
=file("ordersQ4.ctx").open().cursor@m(order_id,order_date) |
3 |
=file("detailsQ4.ctx").open().cursor(order_id,quantity,price;product_id!=2 && product_id!=8;A2) |
4 |
=joinx(A2:o,order_id;A3:d,order_id) |
5 |
=A4.groups(o.order_date;sum(d.quantity*d.price)/icount@o(o.order_id)) |
6 |
>output("query cost:"/interval@ms(A1,now())/"ms") |
SPL 的有序去重计数性能要好的多,而且有序去重计数正好也需要数据对 order_id 有序,可以在有序归并后顺利实施。
执行时间:1.5 秒
小结一下性能(单位 - 秒):
MYSQL |
SPL |
|
例 4.1 |
25 |
1 |
例 4.2 |
21 |
0.6 |
例 4.3 |
40 |
1.5 |
请动手练习一下:
1、找出产品号是 3 或者 6 的订单明细,按照客户分组,求平均每个订单的金额。
2、思考:在自己熟悉的数据库中有没有大主子表关联?是否可以用有序归并方法提速?

