


第三篇 - 外键维表的关联
SQL 对关联的定义过于简单,就是两个表做笛卡尔积后再过滤,在语法上写成 A JOIN B ON …的形式。这样笼统处理多种关联,不体现关联运算本质,书写和优化都困难。
SPL 重新定义了关联。关联不再和笛卡尔积有关,而是分成两种情况:外键关联和主键关联。SPL 用不同的函数来计算不同的关联,体现关联运算本质。这样就可以利用不同关联的特征,采用不同的手段甚至不同的存储方式有效提速。
关联的一种情况是外键关联。一个表的普通字段(外键)和另一个表的主键关联。比如订单表与客户表、运货商表都是外键关联。
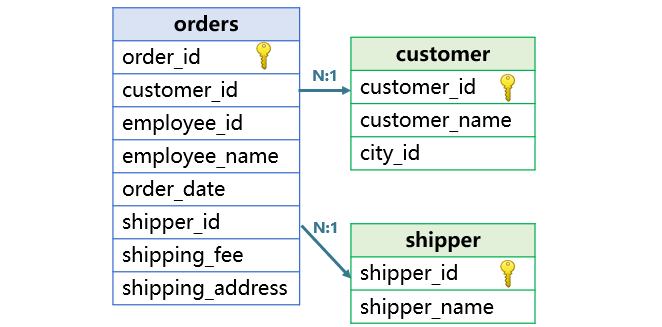
外键在关联表中是主键,具有唯一性,SPL 把外键理解成一个对象。
要注意,这里说的是逻辑上的主键,是在表中取值唯一的字段,不一定是在物理表上建立的 primary key。外键也不一定是物理上的 foreign key。
另一种关联是主键关联。用一个表的主键,关联另一个表的主键或部分主键。比如订单表的主键订单号,关联明细表的部分主键订单号。
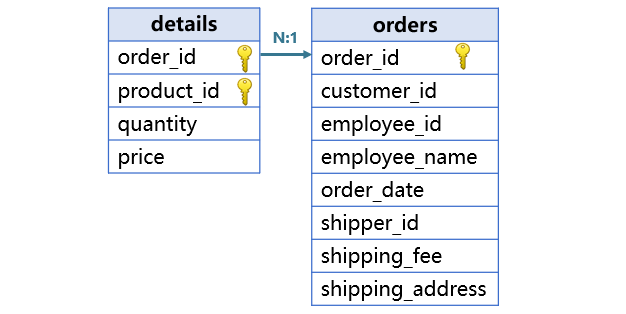
SPL 把主键关联看作记录对象或记录集合之间的连接。
这里要“敲黑板、划重点”啦:使用 SPL 编程实现关联,最重要的是要先识别关联类型!只有识别了关联的类型,才能选择相应的方法实现。识别的时候,重点要看主键在连接中的作用!
下面,我们以订单表、客户表、城市表、州表和运货商表为例,介绍 esProc SPL 外置数据提速外键关联的方法。
使用 ETL 工具定义 Q3.etl,拖拽需要的表:

比较大的 orders 是事实表,转储成 CTX。较小的维表转成 BTX,编程更方便。
定义关联字段序号化,比如 customer 中的 city_id,转维表 city 中的序号。
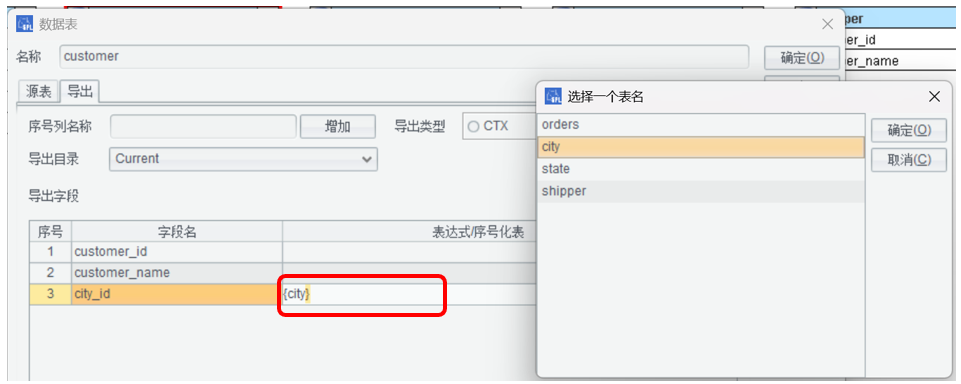
双击表达式 / 序号化表空白处—选择 city 表。city 表的 state_id,要类似的设置成 state 表。
修改 orders 表名为 ordersQ3(区别前面的表 ):
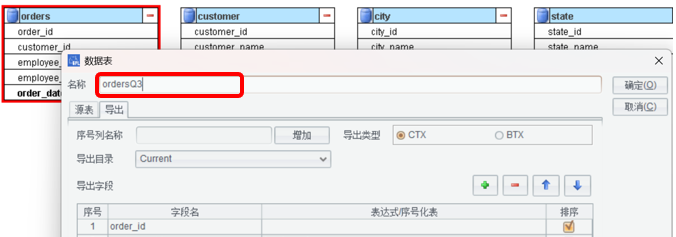
employee_name 没有维表,要在 ordersQ3 表中找全所有值,新建维表 employee:
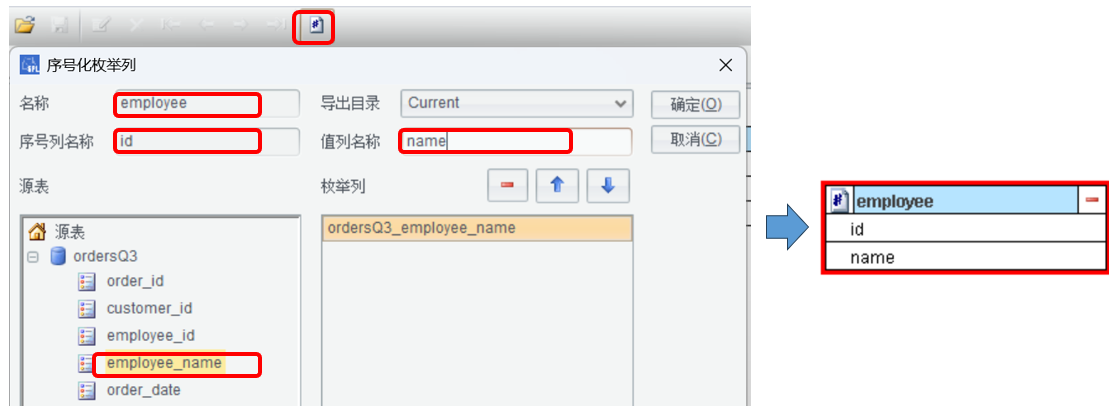
上图的操作顺序:1、点击序号化枚举列。2、双击 employee_name。3、定义维表名 employee。4、定义维表序号列名称 id。5、定义维表值列名称 name。
还要设置 ordersQ3 中的序号化字段:
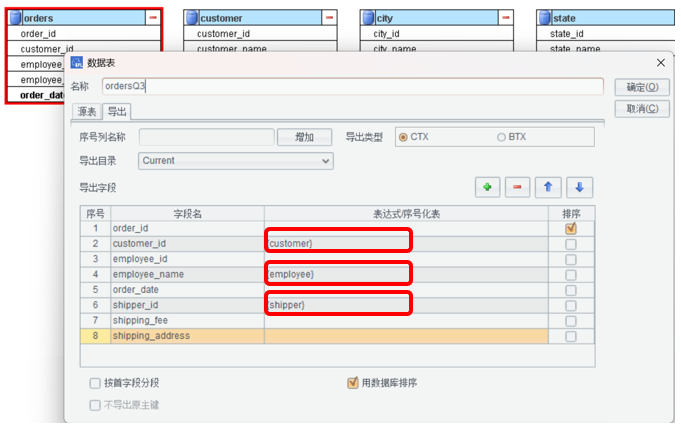
生成 SPL 代码 14:导出数据,转储成 BTX 或 CTX。
A |
|
1 |
=connect("speed") |
2 |
="d:\\speed\\etl\\" |
3 |
=A1.query("SELECT Distinct employee_name FROM orders") |
4 |
=A3.(employee_name).new(#:id,~:name).keys@i(name) |
5 |
=file(A2+"employee.btx").export@b(A4) |
6 |
=A1.query("SELECT state_id,state_name FROM state ORDER BY state_id") |
7 |
=A6.keys@i(state_id) |
8 |
=file(A2+"state.btx").export@b(A6) |
9 |
=A1.query("SELECT city_id,city_name,state_id FROM city ORDER BY city_id") |
10 |
=A9.new(city_id,city_name,A7.pfind(state_id):state_id).keys@i(city_id) |
11 |
=file(A2+"city.btx").export@b(A9) |
12 |
=A1.query("SELECT customer_id,customer_name,city_id FROM customer ORDER BY customer_id") |
13 |
=A12.new(customer_id,customer_name,A10.pfind(city_id):city_id).keys@i(customer_id) |
14 |
=file(A2+"customer.btx").export@b(A12) |
15 |
=A1.query("SELECT shipper_id,shipper_name FROM shipper ORDER BY shipper_id") |
16 |
=A15.keys@i(shipper_id) |
17 |
=file(A2+"shipper.btx").export@b(A15) |
18 |
=A1.cursor("SELECT order_id,customer_id,employee_id,employee_name,order_date,shipper_id,shipping_fee,shipping_address FROM orders ORDER BY order_id") |
19 |
=A18.new(order_id,A13.pfind(customer_id):customer_id,employee_id,A4.pfind(employee_name):employee_name,order_date,A16.pfind(shipper_id):shipper_id,shipping_fee,shipping_address) |
20 |
=file(A2+"ordersQ3.ctx").create@y(#order_id,customer_id,employee_id,employee_name,order_date,shipper_id,shipping_fee,shipping_address).append(A19).close() |
21 |
=A1.close() |
A13 中,customer 表的 city_id,用 pfind 函数转为维表 city 中的序号:
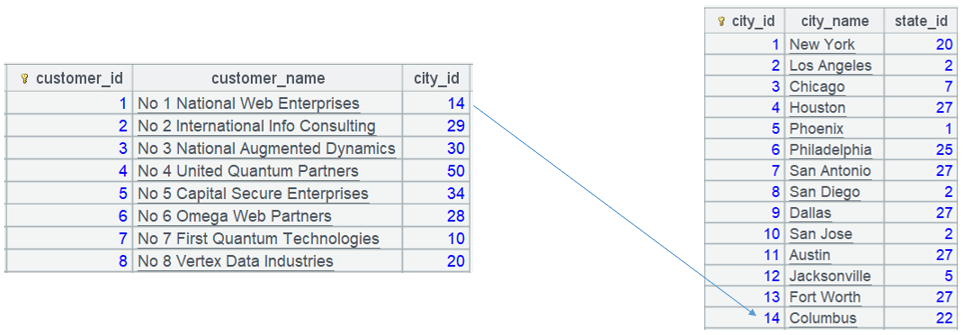
SPL 代码 15:在系统启动,或数据有变动时执行初始化。
A |
B |
|
1 |
=file("state.btx").import@b() |
=env(state,A1) |
2 |
=file("city.btx").import@b() |
=env(city,A2) |
3 |
=file("customer.btx").import@b() |
=env(customer,A3) |
4 |
=file("shipper.btx").import@b() |
=env(shipper,A4) |
5 |
=city.run(state_id=state(state_id)) |
|
6 |
=customer.run(city_id=city(city_id)) |
|
初始化完成预加载,预先把维表读入内存,用 env 存成全局变量。
还要完成预关联,预先把外键用 run 转换成对应维表的记录,比如 A6:

序表 customer 的普通字段 city_id 被转换为 city 表的记录。
数据转储、初始化完成后,可以实际计算,比如下面的例子:
例 3.1 某州订单,按运货商分组统计运费,结果包括运货商名。
SQL 这样写:
select shipper.shipper_id, shipper.shipper_name,sum(o.shipping_fee)
from
orders o
join
customer c on o.customer_id = c.customer_id
join
city on city.city_id = c.city_id
join
state on state.state_id = city.state_id
join
shipper on o.shipper_id = shipper.shipper_id
where
state.state_name = 'California'
group by
shipper.shipper_id, shipper.shipper_name;
执行时间是 20 秒。
SPL 代码 16:
A |
|
1 |
=now() |
2 |
=file("ordersQ3.ctx").open() |
3 |
=A2.cursor@m(order_id, customer_id,shipper_id,shipping_fee;customer_id:customer:#,shipper_id:shipper:#) |
4 |
=A3.select(customer_id.city_id.state_id.state_name=="California").groups(shipper_id;shipper_id.shipper_name,sum(shipping_fee)) |
5 |
>output("query cost:"/interval@ms(A1,now())/"ms") |
A2 中 customer_id:customer:# 的写法,是利用序号 #,在游标上完成订单记录与客户表的关联。关联后, customer_id 和 shipper_id 字段都被转换为对应表的记录对象。
由于维表已经在初始化时预先关联好了,A3 就可以采用对象属性的方式写代码: customer_id.city_id.state_id.state_name。
执行时间是 0.4 秒
例 3.2 按客户所在城市分组统计订单数量,结果要包含州名称、城市名称。
select city.city_id,city.city_name,state.state_name,count(o.order_id)
from
orders o
join
customer c on o.customer_id = c.customer_id
join
city on c.city_id = city.city_id
join
state on city.state_id = state.state_id
group by
city.city_id,city.city_name,state.state_name;
执行时间:22 秒。
SPL 代码 17:在前面代码 SPL 代码 16 基础上,改一下 A4 就可以了。
A |
|
1 |
=now() |
2 |
=file("ordersQ3.ctx").open() |
3 |
=A2.cursor@m(order_id, customer_id,shipper_id,shipping_fee;customer_id:customer:#,shipper_id:shipper:#) |
4 |
=A3.groups(customer_id.city_id.city_id;customer_id.city_id.city_name,customer_id.city_id.state_id.state_name, count(1)) |
5 |
>output("query cost:"/interval@ms(A1,now())/"ms") |
执行时间是 0.3 秒。
小结一下性能(单位 - 秒):
MYSQL |
SPL |
|
例 3.1 |
20 |
0.4 |
例 3.2 |
22 |
0.3 |
请动手练习一下:
1、找出运货商是 Elite Shipping Co. 的订单,按客户所在州分组统计运货费。结果要包括州名称。
2、思考:在自己熟悉的数据库中有没有通过外键关联的多个表?是否可以用序号关联的方法来提速?

